 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinistral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
Voxtral
Jul 17, 2025We present Voxtral Mini and Voxtral Small, two multimodal audio chat models. Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. We also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.
Magistral
Jun 12, 2025



We introduce Magistral, Mistral's first reasoning model and our own scalable reinforcement learning (RL) pipeline. Instead of relying on existing implementations and RL traces distilled from prior models, we follow a ground up approach, relying solely on our own models and infrastructure. Notably, we demonstrate a stack that enabled us to explore the limits of pure RL training of LLMs, present a simple method to force the reasoning language of the model, and show that RL on text data alone maintains most of the initial checkpoint's capabilities. We find that RL on text maintains or improves multimodal understanding, instruction following and function calling. We present Magistral Medium, trained for reasoning on top of Mistral Medium 3 with RL alone, and we open-source Magistral Small (Apache 2.0) which further includes cold-start data from Magistral Medium.
Learning Valid Dual Bounds in Constraint Programming: Boosted Lagrangian Decomposition with Self-Supervised Learning
Aug 22, 2024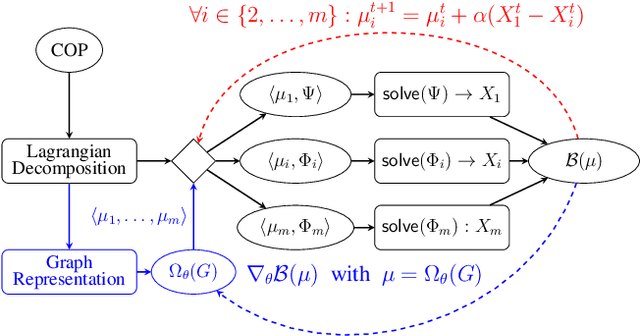

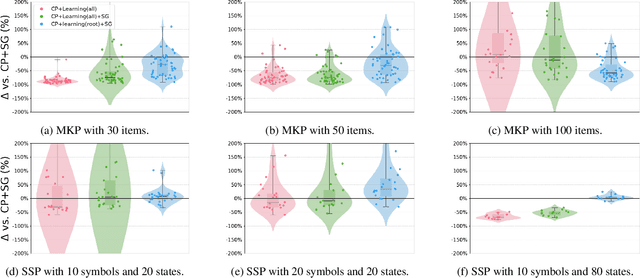
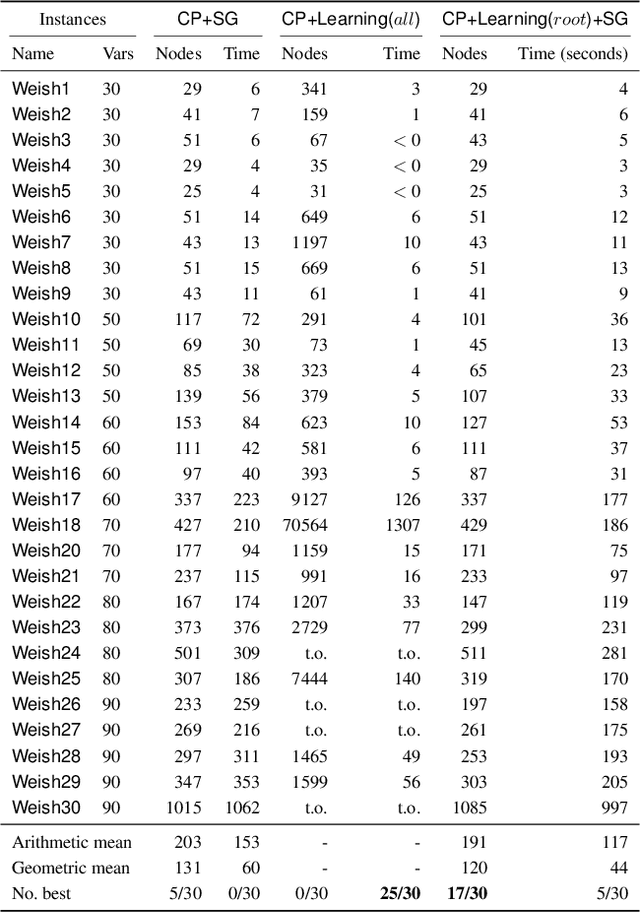
Lagrangian decomposition (LD) is a relaxation method that provides a dual bound for constrained optimization problems by decomposing them into more manageable sub-problems. This bound can be used in branch-and-bound algorithms to prune the search space effectively. In brief, a vector of Lagrangian multipliers is associated with each sub-problem, and an iterative procedure (e.g., a sub-gradient optimization) adjusts these multipliers to find the tightest bound. Initially applied to integer programming, Lagrangian decomposition also had success in constraint programming due to its versatility and the fact that global constraints provide natural sub-problems. However, the non-linear and combinatorial nature of sub-problems in constraint programming makes it computationally intensive to optimize the Lagrangian multipliers with sub-gradient methods at each node of the tree search. This currently limits the practicality of LD as a general bounding mechanism for constraint programming. To address this challenge, we propose a self-supervised learning approach that leverages neural networks to generate multipliers directly, yielding tight bounds. This approach significantly reduces the number of sub-gradient optimization steps required, enhancing the pruning efficiency and reducing the execution time of constraint programming solvers. This contribution is one of the few that leverage learning to enhance bounding mechanisms on the dual side, a critical element in the design of combinatorial solvers. To our knowledge, this work presents the first generic method for learning valid dual bounds in constraint programming.
Fully-fused Multi-Layer Perceptrons on Intel Data Center GPUs
Mar 26, 2024



This paper presents a SYCL implementation of Multi-Layer Perceptrons (MLPs), which targets and is optimized for the Intel Data Center GPU Max 1550. To increase the performance, our implementation minimizes the slow global memory accesses by maximizing the data reuse within the general register file and the shared local memory by fusing the operations in each layer of the MLP. We show with a simple roofline model that this results in a significant increase in the arithmetic intensity, leading to improved performance, especially for inference. We compare our approach to a similar CUDA implementation for MLPs and show that our implementation on the Intel Data Center GPU outperforms the CUDA implementation on Nvidia's H100 GPU by a factor up to 2.84 in inference and 1.75 in training. The paper also showcases the efficiency of our SYCL implementation in three significant areas: Image Compression, Neural Radiance Fields, and Physics-Informed Machine Learning. In all cases, our implementation outperforms the off-the-shelf Intel Extension for PyTorch (IPEX) implementation on the same Intel GPU by up to a factor of 30 and the CUDA PyTorch version on Nvidia's H100 GPU by up to a factor 19. The code can be found at https://github.com/intel/tiny-dpcpp-nn.