 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully-fused Multi-Layer Perceptrons on Intel Data Center GPUs
Mar 26, 2024



This paper presents a SYCL implementation of Multi-Layer Perceptrons (MLPs), which targets and is optimized for the Intel Data Center GPU Max 1550. To increase the performance, our implementation minimizes the slow global memory accesses by maximizing the data reuse within the general register file and the shared local memory by fusing the operations in each layer of the MLP. We show with a simple roofline model that this results in a significant increase in the arithmetic intensity, leading to improved performance, especially for inference. We compare our approach to a similar CUDA implementation for MLPs and show that our implementation on the Intel Data Center GPU outperforms the CUDA implementation on Nvidia's H100 GPU by a factor up to 2.84 in inference and 1.75 in training. The paper also showcases the efficiency of our SYCL implementation in three significant areas: Image Compression, Neural Radiance Fields, and Physics-Informed Machine Learning. In all cases, our implementation outperforms the off-the-shelf Intel Extension for PyTorch (IPEX) implementation on the same Intel GPU by up to a factor of 30 and the CUDA PyTorch version on Nvidia's H100 GPU by up to a factor 19. The code can be found at https://github.com/intel/tiny-dpcpp-nn.
A coarse space acceleration of deep-DDM
Dec 07, 2021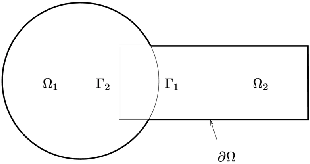



The use of deep learning methods for solving PDEs is a field in full expansion. In particular, Physical Informed Neural Networks, that implement a sampling of the physical domain and use a loss function that penalizes the violation of the partial differential equation, have shown their great potential. Yet, to address large scale problems encountered in real applications and compete with existing numerical methods for PDEs, it is important to design parallel algorithms with good scalability properties. In the vein of traditional domain decomposition methods (DDM), we consider the recently proposed deep-ddm approach. We present an extension of this method that relies on the use of a coarse space correction, similarly to what is done in traditional DDM solvers. Our investigations shows that the coarse correction is able to alleviate the deterioration of the convergence of the solver when the number of subdomains is increased thanks to an instantaneous information exchange between subdomains at each iteration. Experimental results demonstrate that our approach induces a remarkable acceleration of the original deep-ddm method, at a reduced additional computational cost.
Latent Space Data Assimilation by using Deep Learning
Apr 01, 2021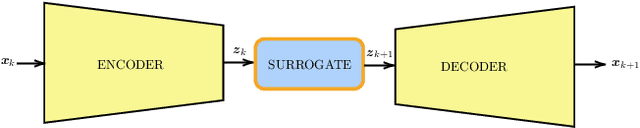
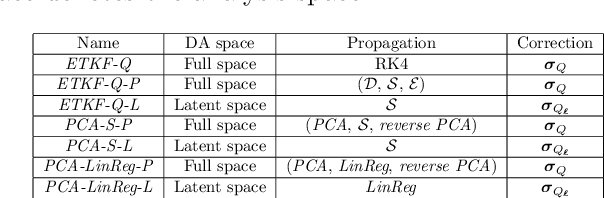
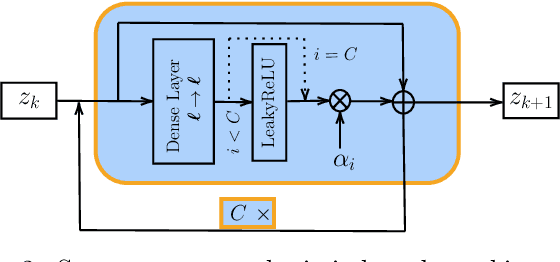
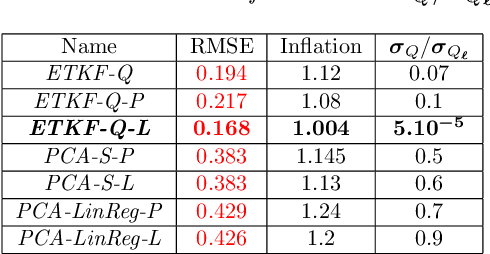
Performing Data Assimilation (DA) at a low cost is of prime concern in Earth system modeling, particularly at the time of big data where huge quantities of observations are available. Capitalizing on the ability of Neural Networks techniques for approximating the solution of PDE's, we incorporate Deep Learning (DL) methods into a DA framework. More precisely, we exploit the latent structure provided by autoencoders (AEs) to design an Ensemble Transform Kalman Filter with model error (ETKF-Q) in the latent space. Model dynamics are also propagated within the latent space via a surrogate neural network. This novel ETKF-Q-Latent (thereafter referred to as ETKF-Q-L) algorithm is tested on a tailored instructional version of Lorenz 96 equations, named the augmented Lorenz 96 system: it possesses a latent structure that accurately represents the observed dynamics. Numerical experiments based on this particular system evidence that the ETKF-Q-L approach both reduces the computational cost and provides better accuracy than state of the art algorithms, such as the ETKF-Q.
DAN -- An optimal Data Assimilation framework based on machine learning Recurrent Networks
Oct 19, 2020



Data assimilation algorithms aim at forecasting the state of a dynamical system by combining a mathematical representation of the system with noisy observations thereof. We propose a fully data driven deep learning architecture generalizing recurrent Elman networks and data assimilation algorithms which provably reaches the same prediction goals as the latter. On numerical experiments based on the well-known Lorenz system and when suitably trained using snapshots of the system trajectory (i.e. batches of state trajectories) and observations, our architecture successfully reconstructs both the analysis and the propagation of probability density functions of the system state at a given time conditioned to past observations.