 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLipschitz bounds for integral kernels
Apr 03, 2026Feature maps associated with positive definite kernels play a central role in kernel methods and learning theory, where regularity properties such as Lipschitz continuity are closely related to robustness and stability guarantees. Despite their importance, explicit characterizations of the Lipschitz constant of kernel feature maps are available only in a limited number of cases. In this paper, we study the Lipschitz regularity of feature maps associated with integral kernels under differentiability assumptions. We first provide sufficient conditions ensuring Lipschitz continuity and derive explicit formulas for the corresponding Lipschitz constants. We then identify a condition under which the feature map fails to be Lipschitz continuous and apply these results to several important classes of kernels. For infinite width two-layer neural network with isotropic Gaussian weight distributions, we show that the Lipschitz constant of the associated kernel can be expressed as the supremum of a two-dimensional integral, leading to an explicit characterization for the Gaussian kernel and the ReLU random neural network kernel. We also study continuous and shift-invariant kernels such as Gaussian, Laplace, and Matérn kernels, which admit an interpretation as neural network with cosine activation function. In this setting, we prove that the feature map is Lipschitz continuous if and only if the weight distribution has a finite second-order moment, and we then derive its Lipschitz constant. Finally, we raise an open question concerning the asymptotic behavior of the convergence of the Lipschitz constant in finite width neural networks. Numerical experiments are provided to support this behavior.
Toward an Operational GNN-Based Multimesh Surrogate for Fast Flood Forecasting
Apr 03, 2026Operational flood forecasting still relies on high-fidelity two-dimensional hydraulic solvers, but their runtime can be prohibitive for rapid decision support on large urban floodplains. In parallel, AI-based surrogate models have shown strong potential in several areas of computational physics for accelerating otherwise expensive high-fidelity simulations. We address this issue on the lower Têt River (France), starting from a production-grade Telemac2D model defined on a high-resolution unstructured finite-element mesh with more than $4\times 10^5$ nodes. From this setup, we build a learning-ready database of synthetic but operationally grounded flood events covering several representative hydrograph families and peak discharges. On top of this database, we develop a graph-neural surrogate based on projected meshes and multimesh connectivity. The projected-mesh strategy keeps training tractable while preserving high-fidelity supervision from the original Telemac simulations, and the multimesh construction enlarges the effective spatial receptive field without increasing network depth. We further study the effect of an explicit discharge feature $Q(t)$ and of pushforward training for long autoregressive rollouts. The experiments show that conditioning on $Q(t)$ is essential in this boundary-driven setting, that multimesh connectivity brings additional gains once the model is properly conditioned, and that pushforward further improves rollout stability. Among the tested configurations, the combination of $Q(t)$, multimesh connectivity, and pushforward provides the best overall results. These gains are observed both on hydraulic variables over the surrogate mesh and on inundation maps interpolated onto a common $25\,\mathrm{m}$ regular grid and compared against the original high-resolution Telemac solution. On the studied case, the learned surrogate produces 6-hour predictions in about $0.4\,\mathrm{s}$ on a single NVIDIA A100 GPU, compared with about $180\,\mathrm{min}$ on 56 CPU cores for the reference simulation. These results support graph-based surrogates as practical complements to industrial hydraulic solvers for operational flood mapping.
Multi-Preconditioned LBFGS for Training Finite-Basis PINNs
Jan 13, 2026A multi-preconditioned LBFGS (MP-LBFGS) algorithm is introduced for training finite-basis physics-informed neural networks (FBPINNs). The algorithm is motivated by the nonlinear additive Schwarz method and exploits the domain-decomposition-inspired additive architecture of FBPINNs, in which local neural networks are defined on subdomains, thereby localizing the network representation. Parallel, subdomain-local quasi-Newton corrections are then constructed on the corresponding local parts of the architecture. A key feature is a novel nonlinear multi-preconditioning mechanism, in which subdomain corrections are optimally combined through the solution of a low-dimensional subspace minimization problem. Numerical experiments indicate that MP-LBFGS can improve convergence speed, as well as model accuracy over standard LBFGS while incurring lower communication overhead.
Recursive Bound-Constrained AdaGrad with Applications to Multilevel and Domain Decomposition Minimization
Jul 15, 2025Two OFFO (Objective-Function Free Optimization) noise tolerant algorithms are presented that handle bound constraints, inexact gradients and use second-order information when available.The first is a multi-level method exploiting a hierarchical description of the problem and the second is a domain-decomposition method covering the standard addditive Schwarz decompositions. Both are generalizations of the first-order AdaGrad algorithm for unconstrained optimization. Because these algorithms share a common theoretical framework, a single convergence/complexity theory is provided which covers them both. Its main result is that, with high probability, both methods need at most $O(\epsilon^{-2})$ iterations and noisy gradient evaluations to compute an $\epsilon$-approximate first-order critical point of the bound-constrained problem. Extensive numerical experiments are discussed on applications ranging from PDE-based problems to deep neural network training, illustrating their remarkable computational efficiency.
Feature Representation Transferring to Lightweight Models via Perception Coherence
May 10, 2025



In this paper, we propose a method for transferring feature representation to lightweight student models from larger teacher models. We mathematically define a new notion called \textit{perception coherence}. Based on this notion, we propose a loss function, which takes into account the dissimilarities between data points in feature space through their ranking. At a high level, by minimizing this loss function, the student model learns to mimic how the teacher model \textit{perceives} inputs. More precisely, our method is motivated by the fact that the representational capacity of the student model is weaker than the teacher model. Hence, we aim to develop a new method allowing for a better relaxation. This means that, the student model does not need to preserve the absolute geometry of the teacher one, while preserving global coherence through dissimilarity ranking. Our theoretical insights provide a probabilistic perspective on the process of feature representation transfer. Our experiments results show that our method outperforms or achieves on-par performance compared to strong baseline methods for representation transferring.
Convolutional Rectangular Attention Module
Mar 13, 2025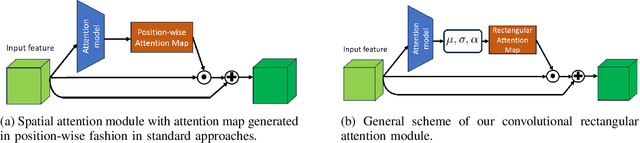
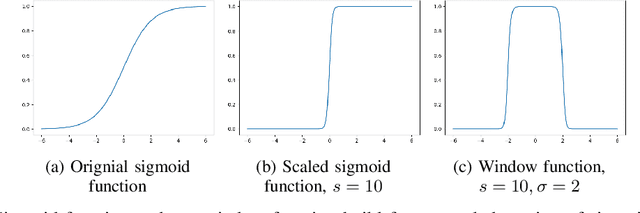
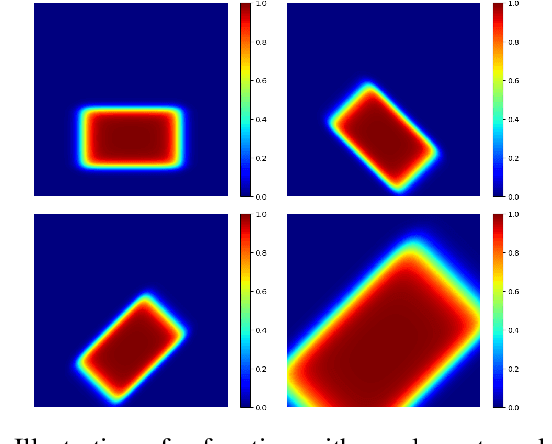
In this paper, we introduce a novel spatial attention module, that can be integrated to any convolutional network. This module guides the model to pay attention to the most discriminative part of an image. This enables the model to attain a better performance by an end-to-end training. In standard approaches, a spatial attention map is generated in a position-wise fashion. We observe that this results in very irregular boundaries. This could make it difficult to generalize to new samples. In our method, the attention region is constrained to be rectangular. This rectangle is parametrized by only 5 parameters, allowing for a better stability and generalization to new samples. In our experiments, our method systematically outperforms the position-wise counterpart. Thus, this provides us a novel useful spatial attention mechanism for convolutional models. Besides, our module also provides the interpretability concerning the ``where to look" question, as it helps to know the part of the input on which the model focuses to produce the prediction.
Two-level deep domain decomposition method
Aug 22, 2024This study presents a two-level Deep Domain Decomposition Method (Deep-DDM) augmented with a coarse-level network for solving boundary value problems using physics-informed neural networks (PINNs). The addition of the coarse level network improves scalability and convergence rates compared to the single level method. Tested on a Poisson equation with Dirichlet boundary conditions, the two-level deep DDM demonstrates superior performance, maintaining efficient convergence regardless of the number of subdomains. This advance provides a more scalable and effective approach to solving complex partial differential equations with machine learning.
Large Margin Discriminative Loss for Classification
May 28, 2024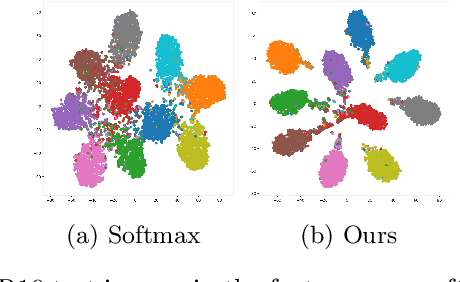
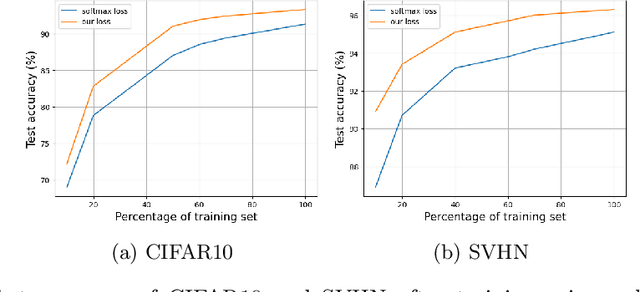
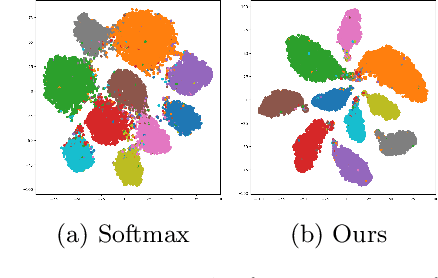
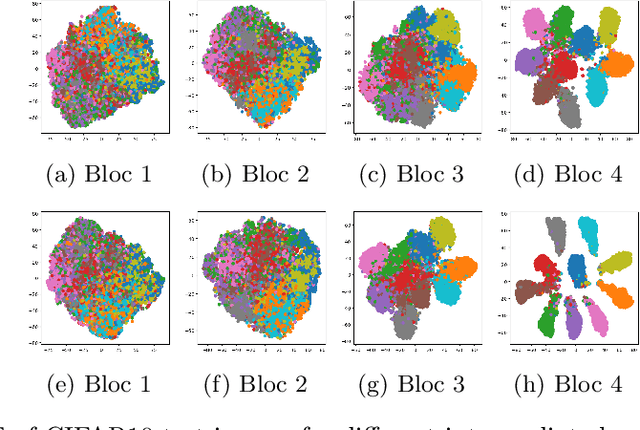
In this paper, we introduce a novel discriminative loss function with large margin in the context of Deep Learning. This loss boosts the discriminative power of neural nets, represented by intra-class compactness and inter-class separability. On the one hand, the class compactness is ensured by close distance of samples of the same class to each other. On the other hand, the inter-class separability is boosted by a margin loss that ensures the minimum distance of each class to its closest boundary. All the terms in our loss have an explicit meaning, giving a direct view of the feature space obtained. We analyze mathematically the relation between compactness and margin term, giving a guideline about the impact of the hyper-parameters on the learned features. Moreover, we also analyze properties of the gradient of the loss with respect to the parameters of the neural net. Based on this, we design a strategy called partial momentum updating that enjoys simultaneously stability and consistency in training. Furthermore, we also investigate generalization errors to have better theoretical insights. Our loss function systematically boosts the test accuracy of models compared to the standard softmax loss in our experiments.
Combining Statistical Depth and Fermat Distance for Uncertainty Quantification
Apr 12, 2024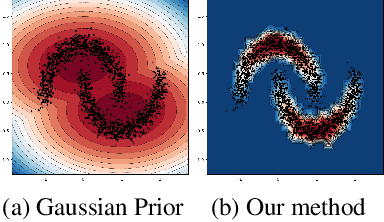
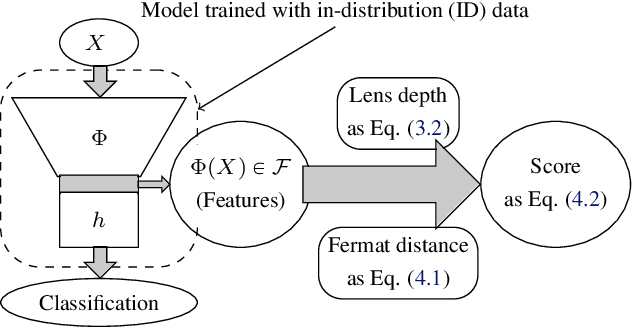
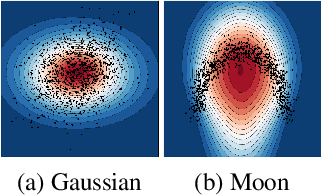
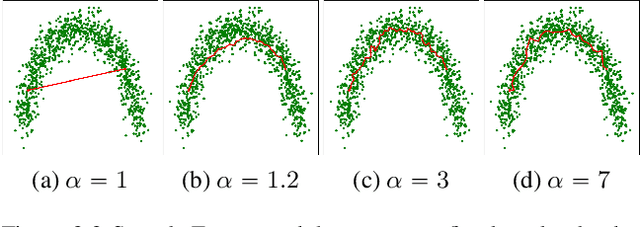
We measure the Out-of-domain uncertainty in the prediction of Neural Networks using a statistical notion called ``Lens Depth'' (LD) combined with Fermat Distance, which is able to capture precisely the ``depth'' of a point with respect to a distribution in feature space, without any assumption about the form of distribution. Our method has no trainable parameter. The method is applicable to any classification model as it is applied directly in feature space at test time and does not intervene in training process. As such, it does not impact the performance of the original model. The proposed method gives excellent qualitative result on toy datasets and can give competitive or better uncertainty estimation on standard deep learning datasets compared to strong baseline methods.
A Block-Coordinate Approach of Multi-level Optimization with an Application to Physics-Informed Neural Networks
May 25, 2023Multi-level methods are widely used for the solution of large-scale problems, because of their computational advantages and exploitation of the complementarity between the involved sub-problems. After a re-interpretation of multi-level methods from a block-coordinate point of view, we propose a multi-level algorithm for the solution of nonlinear optimization problems and analyze its evaluation complexity. We apply it to the solution of partial differential equations using physics-informed neural networks (PINNs) and show on a few test problems that the approach results in better solutions and significant computational savings