 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Margin Discriminative Loss for Classification
Paper and Code
May 28, 2024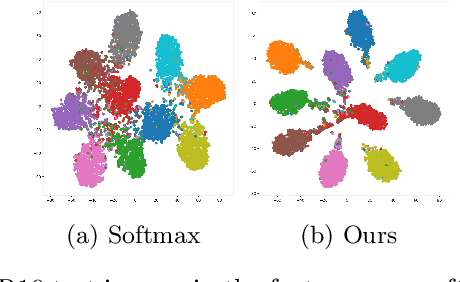
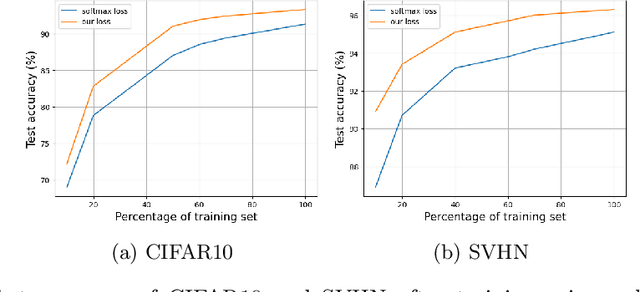
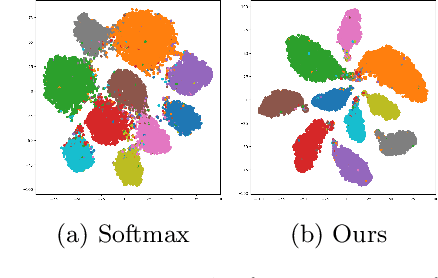
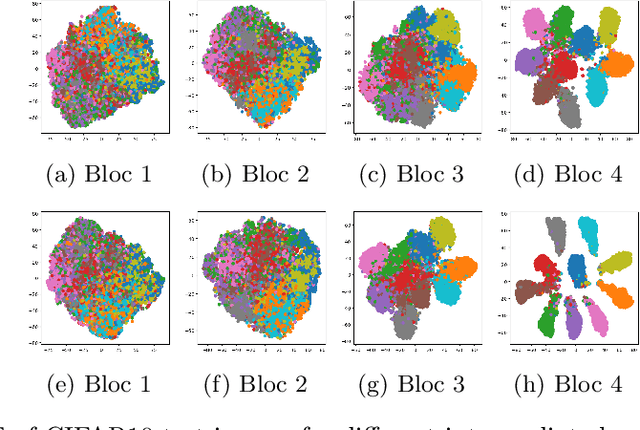
In this paper, we introduce a novel discriminative loss function with large margin in the context of Deep Learning. This loss boosts the discriminative power of neural nets, represented by intra-class compactness and inter-class separability. On the one hand, the class compactness is ensured by close distance of samples of the same class to each other. On the other hand, the inter-class separability is boosted by a margin loss that ensures the minimum distance of each class to its closest boundary. All the terms in our loss have an explicit meaning, giving a direct view of the feature space obtained. We analyze mathematically the relation between compactness and margin term, giving a guideline about the impact of the hyper-parameters on the learned features. Moreover, we also analyze properties of the gradient of the loss with respect to the parameters of the neural net. Based on this, we design a strategy called partial momentum updating that enjoys simultaneously stability and consistency in training. Furthermore, we also investigate generalization errors to have better theoretical insights. Our loss function systematically boosts the test accuracy of models compared to the standard softmax loss in our experiments.