 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional Rectangular Attention Module
Paper and Code
Mar 13, 2025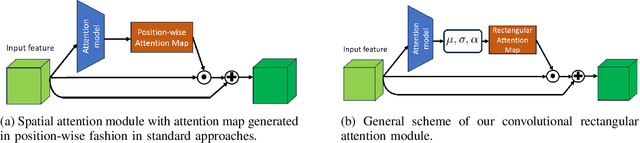
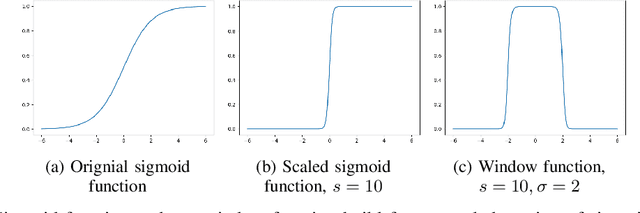
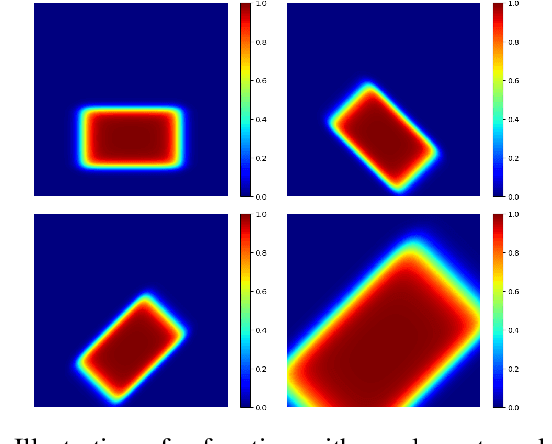
In this paper, we introduce a novel spatial attention module, that can be integrated to any convolutional network. This module guides the model to pay attention to the most discriminative part of an image. This enables the model to attain a better performance by an end-to-end training. In standard approaches, a spatial attention map is generated in a position-wise fashion. We observe that this results in very irregular boundaries. This could make it difficult to generalize to new samples. In our method, the attention region is constrained to be rectangular. This rectangle is parametrized by only 5 parameters, allowing for a better stability and generalization to new samples. In our experiments, our method systematically outperforms the position-wise counterpart. Thus, this provides us a novel useful spatial attention mechanism for convolutional models. Besides, our module also provides the interpretability concerning the ``where to look" question, as it helps to know the part of the input on which the model focuses to produce the prediction.