 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Soft Actor-Critic with Global Loss for Autonomous Mobility-on-Demand Fleet Control
Apr 10, 2024We study a sequential decision-making problem for a profit-maximizing operator of an Autonomous Mobility-on-Demand system. Optimizing a central operator's vehicle-to-request dispatching policy requires efficient and effective fleet control strategies. To this end, we employ a multi-agent Soft Actor-Critic algorithm combined with weighted bipartite matching. We propose a novel vehicle-based algorithm architecture and adapt the critic's loss function to appropriately consider global actions. Furthermore, we extend our algorithm to incorporate rebalancing capabilities. Through numerical experiments, we show that our approach outperforms state-of-the-art benchmarks by up to 12.9% for dispatching and up to 38.9% with integrated rebalancing.
Risk-Sensitive Soft Actor-Critic for Robust Deep Reinforcement Learning under Distribution Shifts
Feb 15, 2024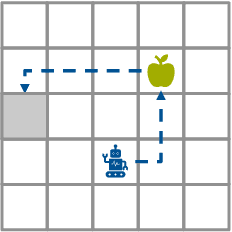
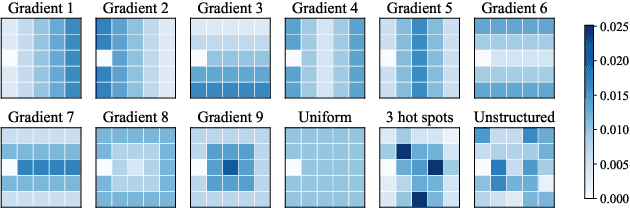
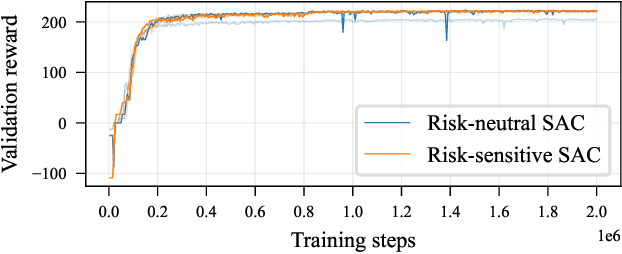
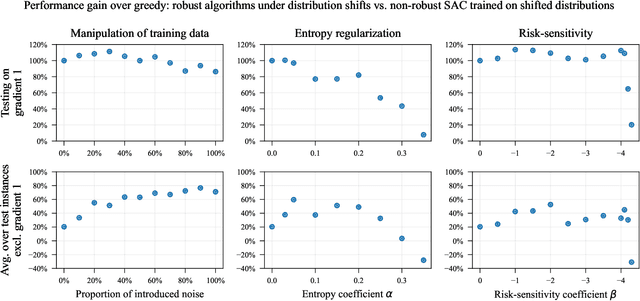
We study the robustness of deep reinforcement learning algorithms against distribution shifts within contextual multi-stage stochastic combinatorial optimization problems from the operations research domain. In this context, risk-sensitive algorithms promise to learn robust policies. While this field is of general interest to the reinforcement learning community, most studies up-to-date focus on theoretical results rather than real-world performance. With this work, we aim to bridge this gap by formally deriving a novel risk-sensitive deep reinforcement learning algorithm while providing numerical evidence for its efficacy. Specifically, we introduce discrete Soft Actor-Critic for the entropic risk measure by deriving a version of the Bellman equation for the respective Q-values. We establish a corresponding policy improvement result and infer a practical algorithm. We introduce an environment that represents typical contextual multi-stage stochastic combinatorial optimization problems and perform numerical experiments to empirically validate our algorithm's robustness against realistic distribution shifts, without compromising performance on the training distribution. We show that our algorithm is superior to risk-neutral Soft Actor-Critic as well as to two benchmark approaches for robust deep reinforcement learning. Thereby, we provide the first structured analysis on the robustness of reinforcement learning under distribution shifts in the realm of contextual multi-stage stochastic combinatorial optimization problems.
Global Rewards in Multi-Agent Deep Reinforcement Learning for Autonomous Mobility on Demand Systems
Dec 14, 2023We study vehicle dispatching in autonomous mobility on demand (AMoD) systems, where a central operator assigns vehicles to customer requests or rejects these with the aim of maximizing its total profit. Recent approaches use multi-agent deep reinforcement learning (MADRL) to realize scalable yet performant algorithms, but train agents based on local rewards, which distorts the reward signal with respect to the system-wide profit, leading to lower performance. We therefore propose a novel global-rewards-based MADRL algorithm for vehicle dispatching in AMoD systems, which resolves so far existing goal conflicts between the trained agents and the operator by assigning rewards to agents leveraging a counterfactual baseline. Our algorithm shows statistically significant improvements across various settings on real-world data compared to state-of-the-art MADRL algorithms with local rewards. We further provide a structural analysis which shows that the utilization of global rewards can improve implicit vehicle balancing and demand forecasting abilities. Our code is available at https://github.com/tumBAIS/GR-MADRL-AMoD.
Hybrid Multi-agent Deep Reinforcement Learning for Autonomous Mobility on Demand Systems
Dec 14, 2022We consider the sequential decision-making problem of making proactive request assignment and rejection decisions for a profit-maximizing operator of an autonomous mobility on demand system. We formalize this problem as a Markov decision process and propose a novel combination of multi-agent Soft Actor-Critic and weighted bipartite matching to obtain an anticipative control policy. Thereby, we factorize the operator's otherwise intractable action space, but still obtain a globally coordinated decision. Experiments based on real-world taxi data show that our method outperforms state of the art benchmarks with respect to performance, stability, and computational tractability.