 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTarget-Aligned Reinforcement Learning
Mar 31, 2026Many reinforcement learning algorithms rely on target networks - lagged copies of the online network - to stabilize training. While effective, this mechanism introduces a fundamental stability-recency tradeoff: slower target updates improve stability but reduce the recency of learning signals, hindering convergence speed. We propose Target-Aligned Reinforcement Learning (TARL), a framework that emphasizes transitions for which the target and online network estimates are highly aligned. By focusing updates on well-aligned targets, TARL mitigates the adverse effects of stale target estimates while retaining the stabilizing benefits of target networks. We provide a theoretical analysis demonstrating that target alignment correction accelerates convergence, and empirically demonstrate consistent improvements over standard reinforcement learning algorithms across various benchmark environments.
Breaking the Grid: Distance-Guided Reinforcement Learning in Large Discrete and Hybrid Action Spaces
Feb 09, 2026Reinforcement Learning is increasingly applied to logistics, scheduling, and recommender systems, but standard algorithms struggle with the curse of dimensionality in such large discrete action spaces. Existing algorithms typically rely on restrictive grid-based structures or computationally expensive nearest-neighbor searches, limiting their effectiveness in high-dimensional or irregularly structured domains. We propose Distance-Guided Reinforcement Learning (DGRL), combining Sampled Dynamic Neighborhoods (SDN) and Distance-Based Updates (DBU) to enable efficient RL in spaces with up to 10$^\text{20}$ actions. Unlike prior methods, SDN leverages a semantic embedding space to perform stochastic volumetric exploration, provably providing full support over a local trust region. Complementing this, DBU transforms policy optimization into a stable regression task, decoupling gradient variance from action space cardinality and guaranteeing monotonic policy improvement. DGRL naturally generalizes to hybrid continuous-discrete action spaces without requiring hierarchical dependencies. We demonstrate performance improvements of up to 66% against state-of-the-art benchmarks across regularly and irregularly structured environments, while simultaneously improving convergence speed and computational complexity.
Trapped in the past? Disentangling fluid and crystallized intelligence of large language models using chess
Jan 23, 2026Large Language Models (LLMs) exhibit remarkable capabilities, yet it remains unclear to what extent these reflect sophisticated recall (crystallized intelligence) or reasoning ability (fluid intelligence). We introduce chess as a controlled testbed for disentangling these faculties. Leveraging the game's structure and scalable engine evaluations, we construct a taxonomy of positions varying in training corpus proximity--ranging from common states solvable by memorization to novel ones requiring first-principles reasoning. We systematically evaluate multiple GPT generations under varying reasoning intensities. Our analysis reveals a clear gradient: performance consistently degrades as fluid intelligence demands increase. Notably, in out-of-distribution tasks, performance collapses to random levels. While newer models improve, progress slows significantly for tasks outside the training distribution. Furthermore, while reasoning-augmented inference improves performance, its marginal benefit per token decreases with distributional proximity. These results suggest current architectures remain limited in systematic generalization, highlighting the need for mechanisms beyond scale to achieve robust fluid intelligence.
Combinatorial Optimization Augmented Machine Learning
Jan 15, 2026Combinatorial optimization augmented machine learning (COAML) has recently emerged as a powerful paradigm for integrating predictive models with combinatorial decision-making. By embedding combinatorial optimization oracles into learning pipelines, COAML enables the construction of policies that are both data-driven and feasibility-preserving, bridging the traditions of machine learning, operations research, and stochastic optimization. This paper provides a comprehensive overview of the state of the art in COAML. We introduce a unifying framework for COAML pipelines, describe their methodological building blocks, and formalize their connection to empirical cost minimization. We then develop a taxonomy of problem settings based on the form of uncertainty and decision structure. Using this taxonomy, we review algorithmic approaches for static and dynamic problems, survey applications across domains such as scheduling, vehicle routing, stochastic programming, and reinforcement learning, and synthesize methodological contributions in terms of empirical cost minimization, imitation learning, and reinforcement learning. Finally, we identify key research frontiers. This survey aims to serve both as a tutorial introduction to the field and as a roadmap for future research at the interface of combinatorial optimization and machine learning.
Reproducibility in the Control of Autonomous Mobility-on-Demand Systems
Jun 09, 2025



Autonomous Mobility-on-Demand (AMoD) systems, powered by advances in robotics, control, and Machine Learning (ML), offer a promising paradigm for future urban transportation. AMoD offers fast and personalized travel services by leveraging centralized control of autonomous vehicle fleets to optimize operations and enhance service performance. However, the rapid growth of this field has outpaced the development of standardized practices for evaluating and reporting results, leading to significant challenges in reproducibility. As AMoD control algorithms become increasingly complex and data-driven, a lack of transparency in modeling assumptions, experimental setups, and algorithmic implementation hinders scientific progress and undermines confidence in the results. This paper presents a systematic study of reproducibility in AMoD research. We identify key components across the research pipeline, spanning system modeling, control problems, simulation design, algorithm specification, and evaluation, and analyze common sources of irreproducibility. We survey prevalent practices in the literature, highlight gaps, and propose a structured framework to assess and improve reproducibility. Specifically, concrete guidelines are offered, along with a "reproducibility checklist", to support future work in achieving replicable, comparable, and extensible results. While focused on AMoD, the principles and practices we advocate generalize to a broader class of cyber-physical systems that rely on networked autonomy and data-driven control. This work aims to lay the foundation for a more transparent and reproducible research culture in the design and deployment of intelligent mobility systems.
Optimization-Augmented Machine Learning for Vehicle Operations in Emergency Medical Services
Mar 14, 2025
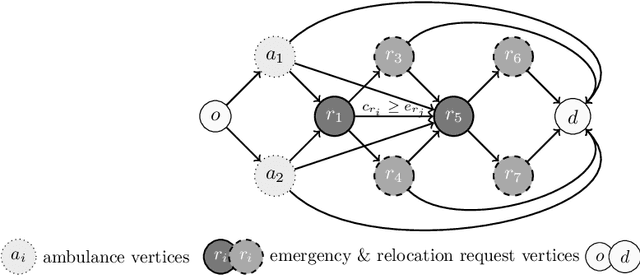

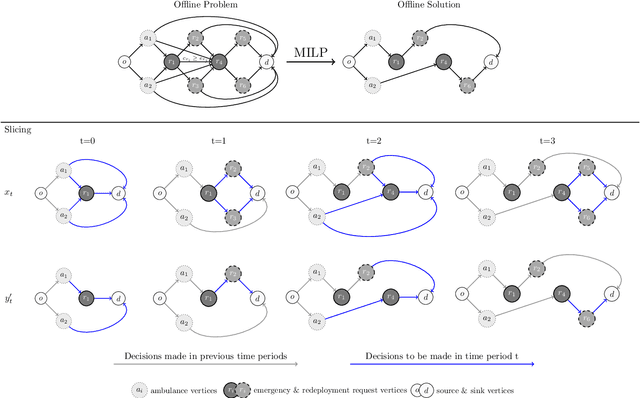
Minimizing response times to meet legal requirements and serve patients in a timely manner is crucial for Emergency Medical Service (EMS) systems. Achieving this goal necessitates optimizing operational decision-making to efficiently manage ambulances. Against this background, we study a centrally controlled EMS system for which we learn an online ambulance dispatching and redeployment policy that aims at minimizing the mean response time of ambulances within the system by dispatching an ambulance upon receiving an emergency call and redeploying it to a waiting location upon the completion of its service. We propose a novel combinatorial optimization-augmented machine learning pipeline that allows to learn efficient policies for ambulance dispatching and redeployment. In this context, we further show how to solve the underlying full-information problem to generate training data and propose an augmentation scheme that improves our pipeline's generalization performance by mitigating a possible distribution mismatch with respect to the considered state space. Compared to existing methods that rely on augmentation during training, our approach offers substantial runtime savings of up to 87.9% while yielding competitive performance. To evaluate the performance of our pipeline against current industry practices, we conduct a numerical case study on the example of San Francisco's 911 call data. Results show that the learned policies outperform the online benchmarks across various resource and demand scenarios, yielding a reduction in mean response time of up to 30%.
Preference-aware compensation policies for crowdsourced on-demand services
Feb 07, 2025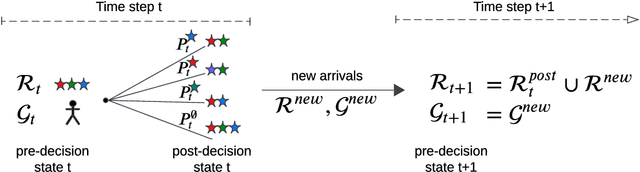
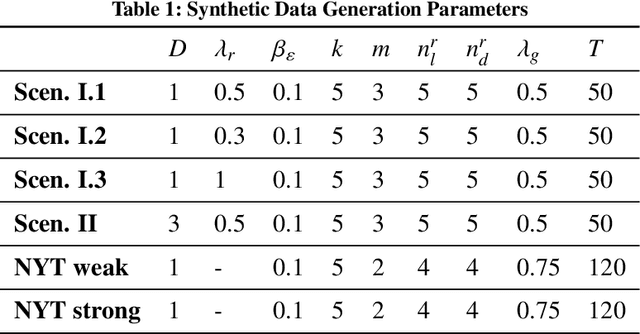

Crowdsourced on-demand services offer benefits such as reduced costs, faster service fulfillment times, greater adaptability, and contributions to sustainable urban transportation in on-demand delivery contexts. However, the success of an on-demand platform that utilizes crowdsourcing relies on finding a compensation policy that strikes a balance between creating attractive offers for gig workers and ensuring profitability. In this work, we examine a dynamic pricing problem for an on-demand platform that sets request-specific compensation of gig workers in a discrete-time framework, where requests and workers arrive stochastically. The operator's goal is to determine a compensation policy that maximizes the total expected reward over the time horizon. Our approach introduces compensation strategies that explicitly account for gig worker request preferences. To achieve this, we employ the Multinomial Logit model to represent the acceptance probabilities of gig workers, and, as a result, derive an analytical solution that utilizes post-decision states. Subsequently, we integrate this solution into an approximate dynamic programming algorithm. We compare our algorithm against benchmark algorithms, including formula-based policies and an upper bound provided by the full information linear programming solution. Our algorithm demonstrates consistent performance across diverse settings, achieving improvements of at least 2.5-7.5% in homogeneous gig worker populations and 9% in heterogeneous populations over benchmarks, based on fully synthetic data. For real-world data, it surpasses benchmarks by 8% in weak and 20% in strong location preference scenarios.
WardropNet: Traffic Flow Predictions via Equilibrium-Augmented Learning
Oct 09, 2024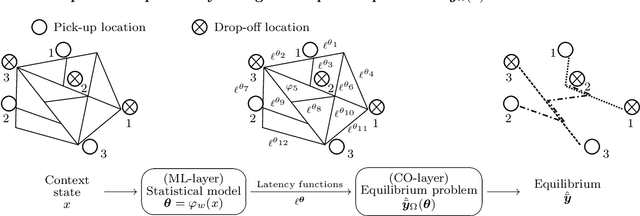
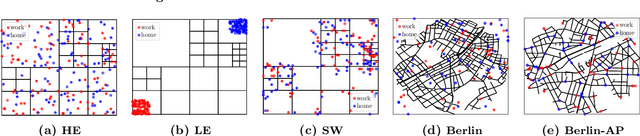
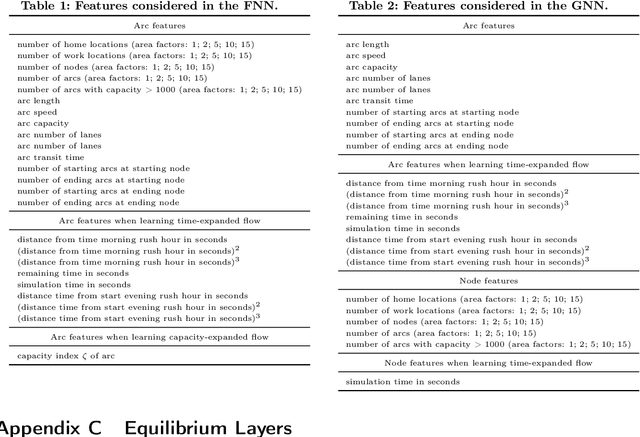
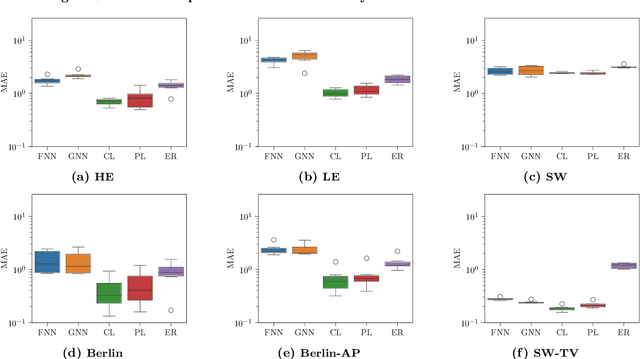
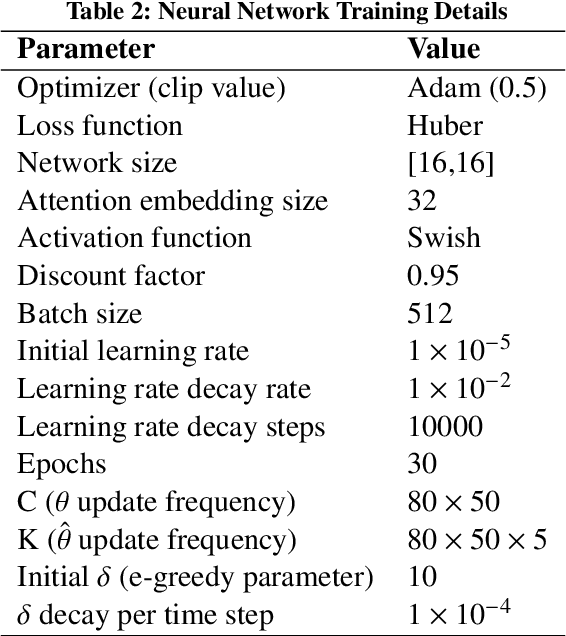
When optimizing transportation systems, anticipating traffic flows is a central element. Yet, computing such traffic equilibria remains computationally expensive. Against this background, we introduce a novel combinatorial optimization augmented neural network architecture that allows for fast and accurate traffic flow predictions. We propose WardropNet, a neural network that combines classical layers with a subsequent equilibrium layer: the first ones inform the latter by predicting the parameterization of the equilibrium problem's latency functions. Using supervised learning we minimize the difference between the actual traffic flow and the predicted output. We show how to leverage a Bregman divergence fitting the geometry of the equilibria, which allows for end-to-end learning. WardropNet outperforms pure learning-based approaches in predicting traffic equilibria for realistic and stylized traffic scenarios. On realistic scenarios, WardropNet improves on average for time-invariant predictions by up to 72% and for time-variant predictions by up to 23% over pure learning-based approaches.
Multi-Agent Soft Actor-Critic with Global Loss for Autonomous Mobility-on-Demand Fleet Control
Apr 10, 2024We study a sequential decision-making problem for a profit-maximizing operator of an Autonomous Mobility-on-Demand system. Optimizing a central operator's vehicle-to-request dispatching policy requires efficient and effective fleet control strategies. To this end, we employ a multi-agent Soft Actor-Critic algorithm combined with weighted bipartite matching. We propose a novel vehicle-based algorithm architecture and adapt the critic's loss function to appropriately consider global actions. Furthermore, we extend our algorithm to incorporate rebalancing capabilities. Through numerical experiments, we show that our approach outperforms state-of-the-art benchmarks by up to 12.9% for dispatching and up to 38.9% with integrated rebalancing.
Risk-Sensitive Soft Actor-Critic for Robust Deep Reinforcement Learning under Distribution Shifts
Feb 15, 2024
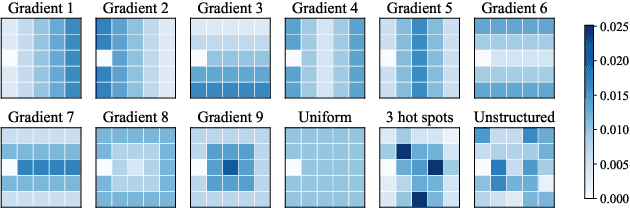
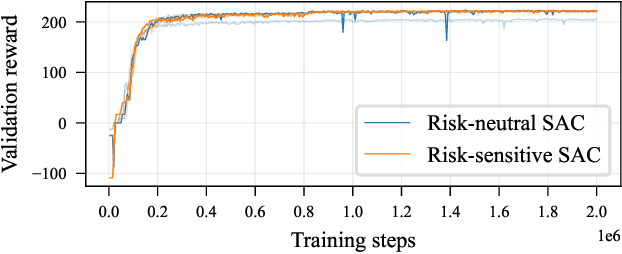
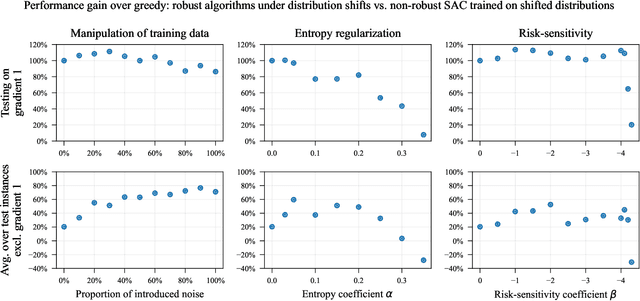
We study the robustness of deep reinforcement learning algorithms against distribution shifts within contextual multi-stage stochastic combinatorial optimization problems from the operations research domain. In this context, risk-sensitive algorithms promise to learn robust policies. While this field is of general interest to the reinforcement learning community, most studies up-to-date focus on theoretical results rather than real-world performance. With this work, we aim to bridge this gap by formally deriving a novel risk-sensitive deep reinforcement learning algorithm while providing numerical evidence for its efficacy. Specifically, we introduce discrete Soft Actor-Critic for the entropic risk measure by deriving a version of the Bellman equation for the respective Q-values. We establish a corresponding policy improvement result and infer a practical algorithm. We introduce an environment that represents typical contextual multi-stage stochastic combinatorial optimization problems and perform numerical experiments to empirically validate our algorithm's robustness against realistic distribution shifts, without compromising performance on the training distribution. We show that our algorithm is superior to risk-neutral Soft Actor-Critic as well as to two benchmark approaches for robust deep reinforcement learning. Thereby, we provide the first structured analysis on the robustness of reinforcement learning under distribution shifts in the realm of contextual multi-stage stochastic combinatorial optimization problems.