 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiated Pickup Point Offering for Emission Reduction in Last-Mile Delivery
Jan 20, 2026Pickup points are widely recognized as a sustainable alternative to home delivery, as consolidating orders at pickup locations can shorten delivery routes and improve first-attempt success rates. However, these benefits may be negated when customers drive to pick up their orders. This study proposes a Differentiated Pickup Point Offering (DPO) policy that aims to jointly reduce emissions from delivery truck routes and customer travel. Under DPO, each arriving customer is offered a single recommended pickup point, rather than an unrestricted choice among all locations, while retaining the option of home delivery. We study this problem in a dynamic and stochastic setting, where the pickup point offered to each customer depends on previously realized customer locations and delivery choices. To design effective DPO policies, we adopt a reinforcement learning-based approach that accounts for spatial relationships between customers and pickup points and their implications for future route consolidation. Computational experiments show that differentiated pickup point offerings can substantially reduce total carbon emissions. The proposed policies reduce total emissions by up to 9% relative to home-only delivery and by 2% on average compared with alternative policies, including unrestricted pickup point choice and nearest pickup point assignment. Differentiated offerings are particularly effective in dense urban settings with many pickup points and short inter-location distances. Moreover, explicitly accounting for the dynamic nature of customer arrivals and choices is especially important when customers are less inclined to choose pickup point delivery over home delivery.
Deep Learning--Accelerated Multi-Start Large Neighborhood Search for Real-time Freight Bundling
Dec 12, 2025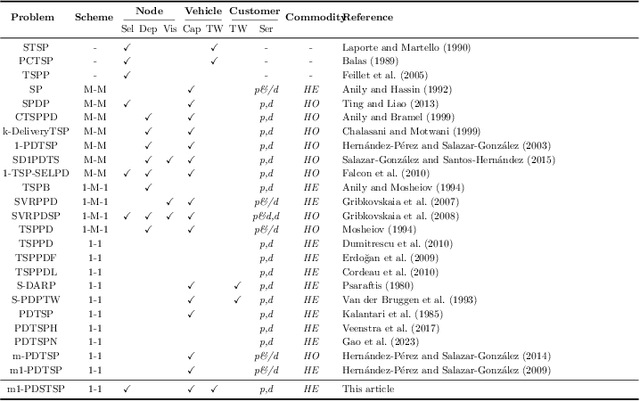

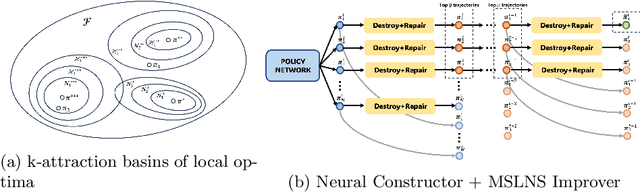

Online Freight Exchange Systems (OFEX) play a crucial role in modern freight logistics by facilitating real-time matching between shippers and carrier. However, efficient combinatorial bundling of transporation jobs remains a bottleneck. We model the OFEX combinatorial bundling problem as a multi-commodity one-to-one pickup-and-delivery selective traveling salesperson problem (m1-PDSTSP), which optimizes revenue-driven freight bundling under capacity, precedence, and route-length constraints. The key challenge is to couple combinatorial bundle selection with pickup-and-delivery routing under sub-second latency. We propose a learning--accelerated hybrid search pipeline that pairs a Transformer Neural Network-based constructive policy with an innovative Multi-Start Large Neighborhood Search (MSLNS) metaheuristic within a rolling-horizon scheme in which the platform repeatedly freezes the current marketplace into a static snapshot and solves it under a short time budget. This pairing leverages the low-latency, high-quality inference of the learning-based constructor alongside the robustness of improvement search; the multi-start design and plausible seeds help LNS to explore the solution space more efficiently. Across benchmarks, our method outperforms state-of-the-art neural combinatorial optimization and metaheuristic baselines in solution quality with comparable time, achieving an optimality gap of less than 2\% in total revenue relative to the best available exact baseline method. To our knowledge, this is the first work to establish that a Deep Neural Network-based constructor can reliably provide high-quality seeds for (multi-start) improvement heuristics, with applicability beyond the \textit{m1-PDSTSP} to a broad class of selective traveling salesperson problems and pickup and delivery problems.
Machine Learning Predictions for Traffic Equilibria in Road Renovation Scheduling
Jun 06, 2025Accurately estimating the impact of road maintenance schedules on traffic conditions is important because maintenance operations can substantially worsen congestion if not carefully planned. Reliable estimates allow planners to avoid excessive delays during periods of roadwork. Since the exact increase in congestion is difficult to predict analytically, traffic simulations are commonly used to assess the redistribution of the flow of traffic. However, when applied to long-term maintenance planning involving many overlapping projects and scheduling alternatives, these simulations must be run thousands of times, resulting in a significant computational burden. This paper investigates the use of machine learning-based surrogate models to predict network-wide congestion caused by simultaneous road renovations. We frame the problem as a supervised learning task, using one-hot encodings, engineered traffic features, and heuristic approximations. A range of linear, ensemble-based, probabilistic, and neural regression models is evaluated under an online learning framework in which data progressively becomes available. The experimental results show that the Costliest Subset Heuristic provides a reasonable approximation when limited training data is available, and that most regression models fail to outperform it, with the exception of XGBoost, which achieves substantially better accuracy. In overall performance, XGBoost significantly outperforms alternatives in a range of metrics, most strikingly Mean Absolute Percentage Error (MAPE) and Pinball loss, where it achieves a MAPE of 11% and outperforms the next-best model by 20% and 38% respectively. This modeling approach has the potential to reduce the computational burden of large-scale traffic assignment problems in maintenance planning.
The Stochastic Dynamic Post-Disaster Inventory Allocation Problem with Trucks and UAVs
Nov 30, 2023



Humanitarian logistics operations face increasing difficulties due to rising demands for aid in disaster areas. This paper investigates the dynamic allocation of scarce relief supplies across multiple affected districts over time. It introduces a novel stochastic dynamic post-disaster inventory allocation problem with trucks and unmanned aerial vehicles delivering relief goods under uncertain supply and demand. The relevance of this humanitarian logistics problem lies in the importance of considering the inter-temporal social impact of deliveries. We achieve this by incorporating deprivation costs when allocating scarce supplies. Furthermore, we consider the inherent uncertainties of disaster areas and the potential use of cargo UAVs to enhance operational efficiency. This study proposes two anticipatory solution methods based on approximate dynamic programming, specifically decomposed linear value function approximation and neural network value function approximation to effectively manage uncertainties in the dynamic allocation process. We compare DL-VFA and NN-VFA with various state-of-the-art methods (exact re-optimization, PPO) and results show a 6-8% improvement compared to the best benchmarks. NN-VFA provides the best performance and captures nonlinearities in the problem, whereas DL-VFA shows excellent scalability against a minor performance loss. The experiments reveal that consideration of deprivation costs results in improved allocation of scarce supplies both across affected districts and over time. Finally, results show that deploying UAVs can play a crucial role in the allocation of relief goods, especially in the first stages after a disaster. The use of UAVs reduces transportation- and deprivation costs together by 16-20% and reduces maximum deprivation times by 19-40%, while maintaining similar levels of demand coverage, showcasing efficient and effective operations.
Handling Large Discrete Action Spaces via Dynamic Neighborhood Construction
May 31, 2023Large discrete action spaces remain a central challenge for reinforcement learning methods. Such spaces are encountered in many real-world applications, e.g., recommender systems, multi-step planning, and inventory replenishment. The mapping of continuous proxies to discrete actions is a promising paradigm for handling large discrete action spaces. Existing continuous-to-discrete mapping approaches involve searching for discrete neighboring actions in a static pre-defined neighborhood, which requires discrete neighbor lookups across the entire action space. Hence, scalability issues persist. To mitigate this drawback, we propose a novel Dynamic Neighborhood Construction (DNC) method, which dynamically constructs a discrete neighborhood to map the continuous proxy, thus efficiently exploiting the underlying action space. We demonstrate the robustness of our method by benchmarking it against three state-of-the-art approaches designed for large discrete action spaces across three different environments. Our results show that DNC matches or outperforms state-of-the-art approaches while being more computationally efficient. Furthermore, our method scales to action spaces that so far remained computationally intractable for existing methodologies.
Strategic bidding in freight transport using deep reinforcement learning
Feb 18, 2021



This paper presents a multi-agent reinforcement learning algorithm to represent strategic bidding behavior in freight transport markets. Using this algorithm, we investigate whether feasible market equilibriums arise without any central control or communication between agents. Studying behavior in such environments may serve as a stepping stone towards self-organizing logistics systems like the Physical Internet. We model an agent-based environment in which a shipper and a carrier actively learn bidding strategies using policy gradient methods, posing bid- and ask prices at the individual container level. Both agents aim to learn the best response given the expected behavior of the opposing agent. A neutral broker allocates jobs based on bid-ask spreads. Our game-theoretical analysis and numerical experiments focus on behavioral insights. To evaluate system performance, we measure adherence to Nash equilibria, fairness of reward division and utilization of transport capacity. We observe good performance both in predictable, deterministic settings (~95% adherence to Nash equilibria) and highly stochastic environments (~85% adherence). Risk-seeking behavior may increase an agent's reward share, as long as the strategies are not overly aggressive. The results suggest a potential for full automation and decentralization of freight transport markets.
Smart Containers With Bidding Capacity: A Policy Gradient Algorithm for Semi-Cooperative Learning
May 01, 2020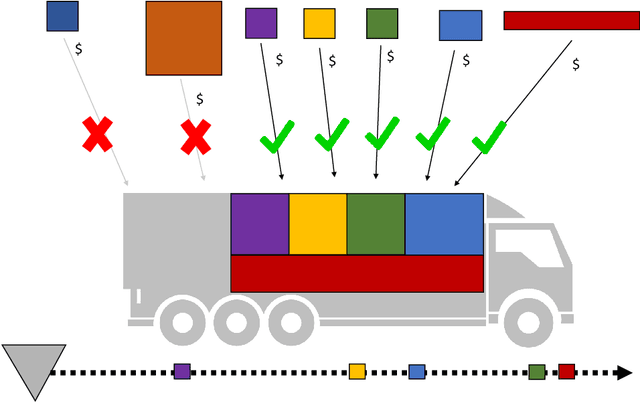



Smart modular freight containers -- as propagated in the Physical Internet paradigm -- are equipped with sensors, data storage capability and intelligence that enable them to route themselves from origin to destination without manual intervention or central governance. In this self-organizing setting, containers can autonomously place bids on transport services in a spot market setting. However, for individual containers it may be difficult to learn good bidding policies due to limited observations. By sharing information and costs between one another, smart containers can jointly learn bidding policies, even though simultaneously competing for the same transport capacity. We replicate this behavior by learning stochastic bidding policies in a semi-cooperative multi agent setting. To this end, we develop a reinforcement learning algorithm based on the policy gradient framework. Numerical experiments show that sharing solely bids and acceptance decisions leads to stable bidding policies. Additional system information only marginally improves performance; individual job properties suffice to place appropriate bids. Furthermore, we find that carriers may have incentives not to share information with the smart containers. The experiments give rise to several directions for follow-up research, in particular the interaction between smart containers and transport services in self-organizing logistics.
Approximate Dynamic Programming with Neural Networks in Linear Discrete Action Spaces
Feb 26, 2019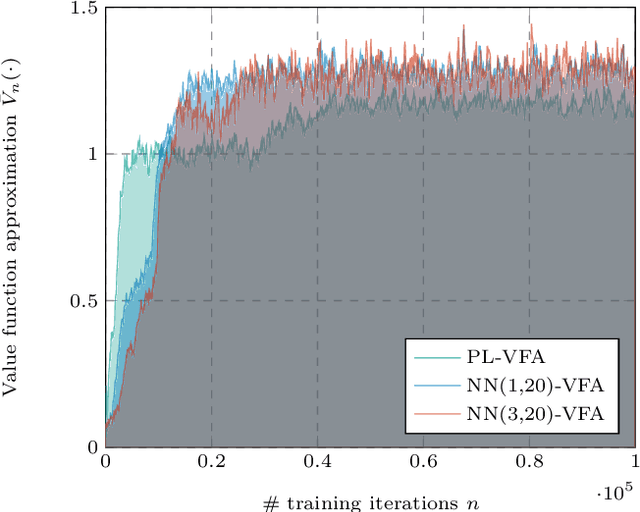

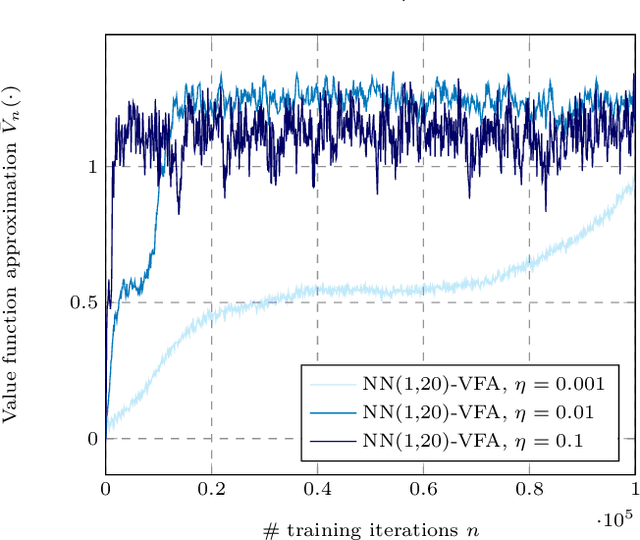
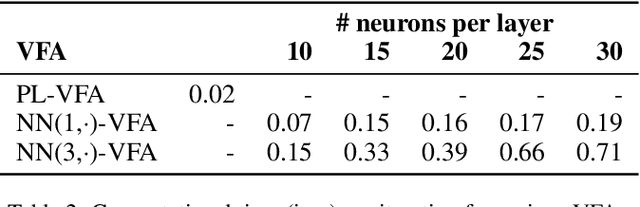
Real-world problems of operations research are typically high-dimensional and combinatorial. Linear programs are generally used to formulate and efficiently solve these large decision problems. However, in multi-period decision problems, we must often compute expected downstream values corresponding to current decisions. When applying stochastic methods to approximate these values, linear programs become restrictive for designing value function approximations (VFAs). In particular, the manual design of a polynomial VFA is challenging. This paper presents an integrated approach for complex optimization problems, focusing on applications in the domain of operations research. It develops a hybrid solution method that combines linear programming and neural networks as part of approximate dynamic programming. Our proposed solution method embeds neural network VFAs into linear decision problems, combining the nonlinear expressive power of neural networks with the efficiency of solving linear programs. As a proof of concept, we perform numerical experiments on a transportation problem. The neural network VFAs consistently outperform polynomial VFAs, with limited design and tuning effort.