 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Grid: Distance-Guided Reinforcement Learning in Large Discrete and Hybrid Action Spaces
Feb 09, 2026Reinforcement Learning is increasingly applied to logistics, scheduling, and recommender systems, but standard algorithms struggle with the curse of dimensionality in such large discrete action spaces. Existing algorithms typically rely on restrictive grid-based structures or computationally expensive nearest-neighbor searches, limiting their effectiveness in high-dimensional or irregularly structured domains. We propose Distance-Guided Reinforcement Learning (DGRL), combining Sampled Dynamic Neighborhoods (SDN) and Distance-Based Updates (DBU) to enable efficient RL in spaces with up to 10$^\text{20}$ actions. Unlike prior methods, SDN leverages a semantic embedding space to perform stochastic volumetric exploration, provably providing full support over a local trust region. Complementing this, DBU transforms policy optimization into a stable regression task, decoupling gradient variance from action space cardinality and guaranteeing monotonic policy improvement. DGRL naturally generalizes to hybrid continuous-discrete action spaces without requiring hierarchical dependencies. We demonstrate performance improvements of up to 66% against state-of-the-art benchmarks across regularly and irregularly structured environments, while simultaneously improving convergence speed and computational complexity.
Solving Dual Sourcing Problems with Supply Mode Dependent Failure Rates
Oct 04, 2024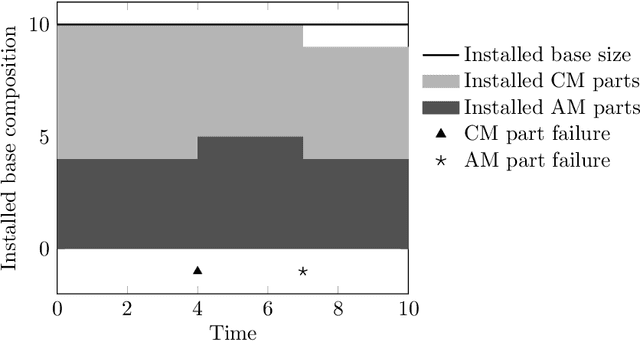
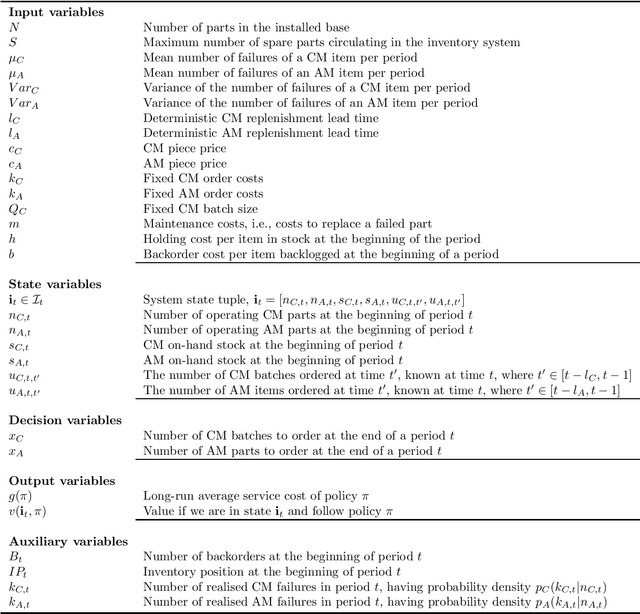
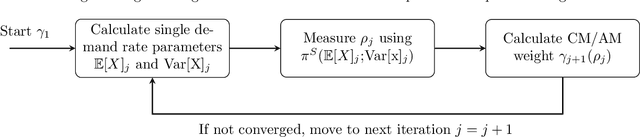
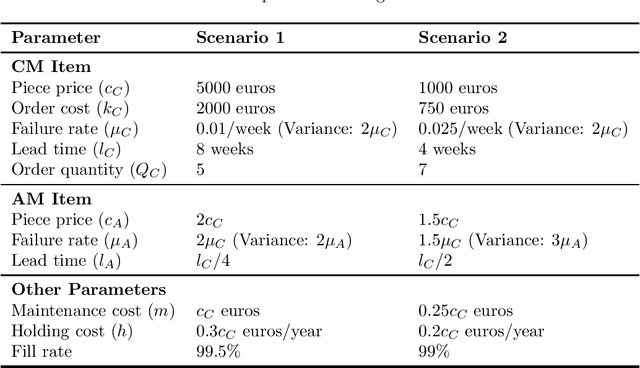
This paper investigates dual sourcing problems with supply mode dependent failure rates, particularly relevant in managing spare parts for downtime-critical assets. To enhance resilience, businesses increasingly adopt dual sourcing strategies using both conventional and additive manufacturing techniques. This paper explores how these strategies can optimise sourcing by addressing variations in part properties and failure rates. A significant challenge is the distinct failure characteristics of parts produced by these methods, which influence future demand. To tackle this, we propose a new iterative heuristic and several reinforcement learning techniques combined with an endogenous parameterised learning (EPL) approach. This EPL approach - compatible with any learning method - allows a single policy to handle various input parameters for multiple items. In a stylised setting, our best policy achieves an average optimality gap of 0.4%. In a case study within the energy sector, our policies outperform the baseline in 91.1% of instances, yielding average cost savings up to 22.6%.
Learning Dynamic Selection and Pricing of Out-of-Home Deliveries
Nov 23, 2023
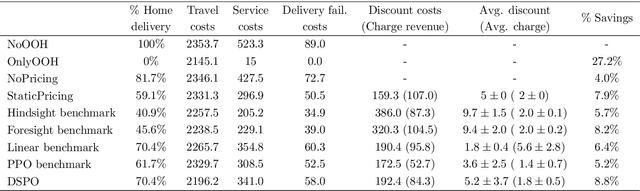

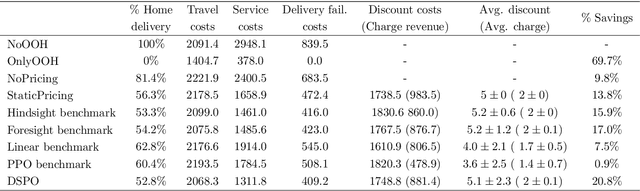
Home delivery failures, traffic congestion, and relatively large handling times have a negative impact on the profitability of last-mile logistics. These external factors contribute to up to $28\%$ of the overall costs and $25\%$ of emissions for the home delivery supply chain. A potential solution, showing annual growth rates up to $36\%$, is the delivery to parcel lockers or parcel shops, denoted by out-of-home (OOH) delivery. In the academic literature, models of customer behavior with respect to OOH delivery were so far limited to deterministic settings, contrasting with the stochastic nature of actual customer choices. We model the sequential decision-making problem of which OOH location to offer against what incentive for each incoming customer, taking into account future customer arrivals and choices. We propose Dynamic Selection and Pricing of OOH (DSPO), an algorithmic pipeline that uses a novel spatial-temporal state encoding as input to a convolutional neural network. We demonstrate the performance of our method by benchmarking it against three state-of-the-art approaches. Our extensive numerical study, guided by real-world data, reveals that DSPO can save $20.8\%$ in costs compared to a situation without OOH locations, $8.1\%$ compared to a static selection and pricing policy, and $4.6\%$ compared to a state-of-the-art demand management benchmark. We provide comprehensive insights into the complex interplay between OOH delivery dynamics and customer behavior influenced by pricing strategies. The implications of our findings suggest practitioners to adopt dynamic selection and pricing policies as OOH delivery gains a larger market share.
Handling Large Discrete Action Spaces via Dynamic Neighborhood Construction
May 31, 2023



Large discrete action spaces remain a central challenge for reinforcement learning methods. Such spaces are encountered in many real-world applications, e.g., recommender systems, multi-step planning, and inventory replenishment. The mapping of continuous proxies to discrete actions is a promising paradigm for handling large discrete action spaces. Existing continuous-to-discrete mapping approaches involve searching for discrete neighboring actions in a static pre-defined neighborhood, which requires discrete neighbor lookups across the entire action space. Hence, scalability issues persist. To mitigate this drawback, we propose a novel Dynamic Neighborhood Construction (DNC) method, which dynamically constructs a discrete neighborhood to map the continuous proxy, thus efficiently exploiting the underlying action space. We demonstrate the robustness of our method by benchmarking it against three state-of-the-art approaches designed for large discrete action spaces across three different environments. Our results show that DNC matches or outperforms state-of-the-art approaches while being more computationally efficient. Furthermore, our method scales to action spaces that so far remained computationally intractable for existing methodologies.