 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompetitive Multi-Operator Reinforcement Learning for Joint Pricing and Fleet Rebalancing in AMoD Systems
Mar 05, 2026Autonomous Mobility-on-Demand (AMoD) systems promise to revolutionize urban transportation by providing affordable on-demand services to meet growing travel demand. However, realistic AMoD markets will be competitive, with multiple operators competing for passengers through strategic pricing and fleet deployment. While reinforcement learning has shown promise in optimizing single-operator AMoD control, existing work fails to capture competitive market dynamics. We investigate the impact of competition on policy learning by introducing a multi-operator reinforcement learning framework where two operators simultaneously learn pricing and fleet rebalancing policies. By integrating discrete choice theory, we enable passenger allocation and demand competition to emerge endogenously from utility-maximizing decisions. Experiments using real-world data from multiple cities demonstrate that competition fundamentally alters learned behaviors, leading to lower prices and distinct fleet positioning patterns compared to monopolistic settings. Notably, we demonstrate that learning-based approaches are robust to the additional stochasticity of competition, with competitive agents successfully converging to effective policies while accounting for partially unobserved competitor strategies.
Time Series Foundation Models as Strong Baselines in Transportation Forecasting: A Large-Scale Benchmark Analysis
Feb 27, 2026Accurate forecasting of transportation dynamics is essential for urban mobility and infrastructure planning. Although recent work has achieved strong performance with deep learning models, these methods typically require dataset-specific training, architecture design and hyper-parameter tuning. This paper evaluates whether general-purpose time-series foundation models can serve as forecasters for transportation tasks by benchmarking the zero-shot performance of the state-of-the-art model, Chronos-2, across ten real-world datasets covering highway traffic volume and flow, urban traffic speed, bike-sharing demand, and electric vehicle charging station data. Under a consistent evaluation protocol, we find that, even without any task-specific fine-tuning, Chronos-2 delivers state-of-the-art or competitive accuracy across most datasets, frequently outperforming classical statistical baselines and specialized deep learning architectures, particularly at longer horizons. Beyond point forecasting, we evaluate its native probabilistic outputs using prediction-interval coverage and sharpness, demonstrating that Chronos-2 also provides useful uncertainty quantification without dataset-specific training. In general, this study supports the adoption of time-series foundation models as a key baseline for transportation forecasting research.
A Bayesian latent class reinforcement learning framework to capture adaptive, feedback-driven travel behaviour
Dec 08, 2025
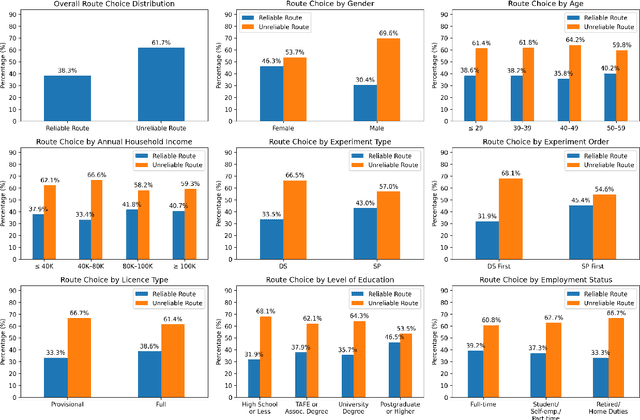


Many travel decisions involve a degree of experience formation, where individuals learn their preferences over time. At the same time, there is extensive scope for heterogeneity across individual travellers, both in their underlying preferences and in how these evolve. The present paper puts forward a Latent Class Reinforcement Learning (LCRL) model that allows analysts to capture both of these phenomena. We apply the model to a driving simulator dataset and estimate the parameters through Variational Bayes. We identify three distinct classes of individuals that differ markedly in how they adapt their preferences: the first displays context-dependent preferences with context-specific exploitative tendencies; the second follows a persistent exploitative strategy regardless of context; and the third engages in an exploratory strategy combined with context-specific preferences.
On Predicting Sociodemographics from Mobility Signals
Nov 06, 2025Inferring sociodemographic attributes from mobility data could help transportation planners better leverage passively collected datasets, but this task remains difficult due to weak and inconsistent relationships between mobility patterns and sociodemographic traits, as well as limited generalization across contexts. We address these challenges from three angles. First, to improve predictive accuracy while retaining interpretability, we introduce a behaviorally grounded set of higher-order mobility descriptors based on directed mobility graphs. These features capture structured patterns in trip sequences, travel modes, and social co-travel, and significantly improve prediction of age, gender, income, and household structure over baselines features. Second, we introduce metrics and visual diagnostic tools that encourage evenness between model confidence and accuracy, enabling planners to quantify uncertainty. Third, to improve generalization and sample efficiency, we develop a multitask learning framework that jointly predicts multiple sociodemographic attributes from a shared representation. This approach outperforms single-task models, particularly when training data are limited or when applying models across different time periods (i.e., when the test set distribution differs from the training set).
Climate Surrogates for Scalable Multi-Agent Reinforcement Learning: A Case Study with CICERO-SCM
Oct 09, 2025Climate policy studies require models that capture the combined effects of multiple greenhouse gases on global temperature, but these models are computationally expensive and difficult to embed in reinforcement learning. We present a multi-agent reinforcement learning (MARL) framework that integrates a high-fidelity, highly efficient climate surrogate directly in the environment loop, enabling regional agents to learn climate policies under multi-gas dynamics. As a proof of concept, we introduce a recurrent neural network architecture pretrained on ($20{,}000$) multi-gas emission pathways to surrogate the climate model CICERO-SCM. The surrogate model attains near-simulator accuracy with global-mean temperature RMSE $\approx 0.0004 \mathrm{K}$ and approximately $1000\times$ faster one-step inference. When substituted for the original simulator in a climate-policy MARL setting, it accelerates end-to-end training by $>\!100\times$. We show that the surrogate and simulator converge to the same optimal policies and propose a methodology to assess this property in cases where using the simulator is intractable. Our work allows to bypass the core computational bottleneck without sacrificing policy fidelity, enabling large-scale multi-agent experiments across alternative climate-policy regimes with multi-gas dynamics and high-fidelity climate response.
Reproducibility in the Control of Autonomous Mobility-on-Demand Systems
Jun 09, 2025



Autonomous Mobility-on-Demand (AMoD) systems, powered by advances in robotics, control, and Machine Learning (ML), offer a promising paradigm for future urban transportation. AMoD offers fast and personalized travel services by leveraging centralized control of autonomous vehicle fleets to optimize operations and enhance service performance. However, the rapid growth of this field has outpaced the development of standardized practices for evaluating and reporting results, leading to significant challenges in reproducibility. As AMoD control algorithms become increasingly complex and data-driven, a lack of transparency in modeling assumptions, experimental setups, and algorithmic implementation hinders scientific progress and undermines confidence in the results. This paper presents a systematic study of reproducibility in AMoD research. We identify key components across the research pipeline, spanning system modeling, control problems, simulation design, algorithm specification, and evaluation, and analyze common sources of irreproducibility. We survey prevalent practices in the literature, highlight gaps, and propose a structured framework to assess and improve reproducibility. Specifically, concrete guidelines are offered, along with a "reproducibility checklist", to support future work in achieving replicable, comparable, and extensible results. While focused on AMoD, the principles and practices we advocate generalize to a broader class of cyber-physical systems that rely on networked autonomy and data-driven control. This work aims to lay the foundation for a more transparent and reproducible research culture in the design and deployment of intelligent mobility systems.
Spatio-Temporal Graph Neural Network for Urban Spaces: Interpolating Citywide Traffic Volume
May 07, 2025



Reliable street-level traffic volume data, covering multiple modes of transportation, helps urban planning by informing decisions on infrastructure improvements, traffic management, and public transportation. Yet, traffic sensors measuring traffic volume are typically scarcely located, due to their high deployment and maintenance costs. To address this, interpolation methods can estimate traffic volumes at unobserved locations using available data. Graph Neural Networks have shown strong performance in traffic volume forecasting, particularly on highways and major arterial networks. Applying them to urban settings, however, presents unique challenges: urban networks exhibit greater structural diversity, traffic volumes are highly overdispersed with many zeros, the best way to account for spatial dependencies remains unclear, and sensor coverage is often very sparse. We introduce the Graph Neural Network for Urban Interpolation (GNNUI), a novel urban traffic volume estimation approach. GNNUI employs a masking algorithm to learn interpolation, integrates node features to capture functional roles, and uses a loss function tailored to zero-inflated traffic distributions. In addition to the model, we introduce two new open, large-scale urban traffic volume benchmarks, covering different transportation modes: Strava cycling data from Berlin and New York City taxi data. GNNUI outperforms recent, some graph-based, interpolation methods across metrics (MAE, RMSE, true-zero rate, Kullback-Leibler divergence) and remains robust from 90% to 1% sensor coverage. On Strava, for instance, MAE rises only from 7.1 to 10.5, on Taxi from 23.0 to 40.4, demonstrating strong performance under extreme data scarcity, common in real-world urban settings. We also examine how graph connectivity choices influence model accuracy.
Deep Reinforcement Learning for Day-to-day Dynamic Tolling in Tradable Credit Schemes
Apr 10, 2025Tradable credit schemes (TCS) are an increasingly studied alternative to congestion pricing, given their revenue neutrality and ability to address issues of equity through the initial credit allocation. Modeling TCS to aid future design and implementation is associated with challenges involving user and market behaviors, demand-supply dynamics, and control mechanisms. In this paper, we focus on the latter and address the day-to-day dynamic tolling problem under TCS, which is formulated as a discrete-time Markov Decision Process and solved using reinforcement learning (RL) algorithms. Our results indicate that RL algorithms achieve travel times and social welfare comparable to the Bayesian optimization benchmark, with generalization across varying capacities and demand levels. We further assess the robustness of RL under different hyperparameters and apply regularization techniques to mitigate action oscillation, which generates practical tolling strategies that are transferable under day-to-day demand and supply variability. Finally, we discuss potential challenges such as scaling to large networks, and show how transfer learning can be leveraged to improve computational efficiency and facilitate the practical deployment of RL-based TCS solutions.
Robo-taxi Fleet Coordination at Scale via Reinforcement Learning
Apr 09, 2025

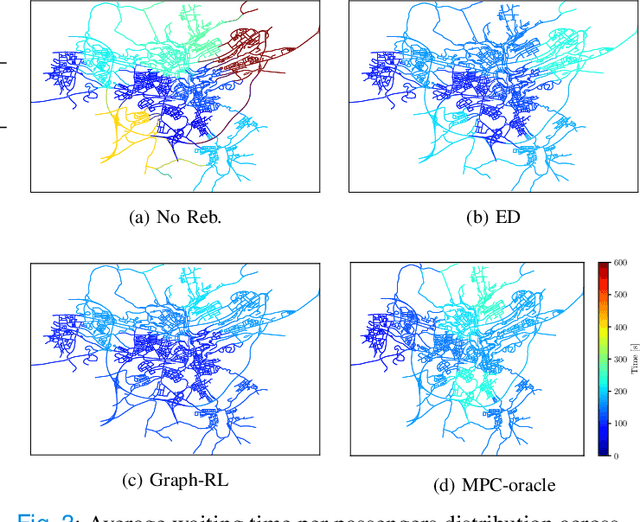

Fleets of robo-taxis offering on-demand transportation services, commonly known as Autonomous Mobility-on-Demand (AMoD) systems, hold significant promise for societal benefits, such as reducing pollution, energy consumption, and urban congestion. However, orchestrating these systems at scale remains a critical challenge, with existing coordination algorithms often failing to exploit the systems' full potential. This work introduces a novel decision-making framework that unites mathematical modeling with data-driven techniques. In particular, we present the AMoD coordination problem through the lens of reinforcement learning and propose a graph network-based framework that exploits the main strengths of graph representation learning, reinforcement learning, and classical operations research tools. Extensive evaluations across diverse simulation fidelities and scenarios demonstrate the flexibility of our approach, achieving superior system performance, computational efficiency, and generalizability compared to prior methods. Finally, motivated by the need to democratize research efforts in this area, we release publicly available benchmarks, datasets, and simulators for network-level coordination alongside an open-source codebase designed to provide accessible simulation platforms and establish a standardized validation process for comparing methodologies. Code available at: https://github.com/StanfordASL/RL4AMOD
Diffusion-aware Censored Gaussian Processes for Demand Modelling
Jan 21, 2025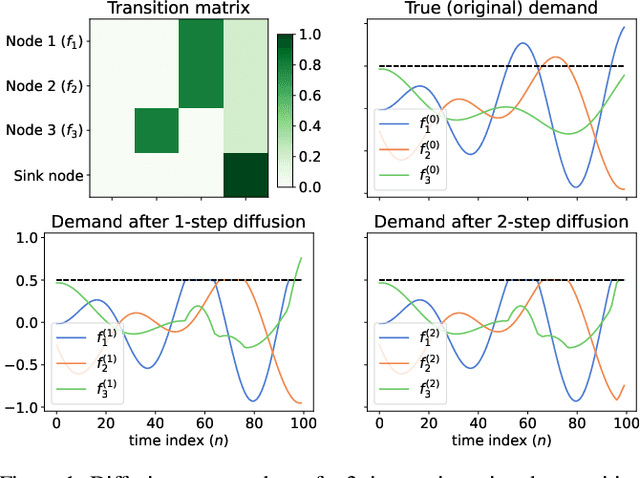
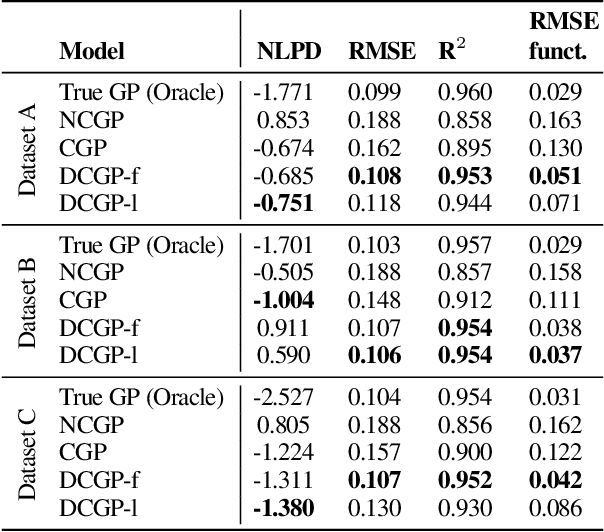
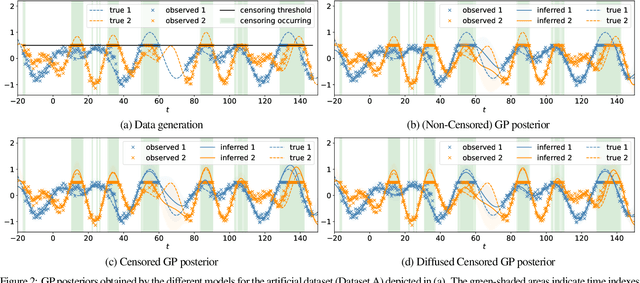
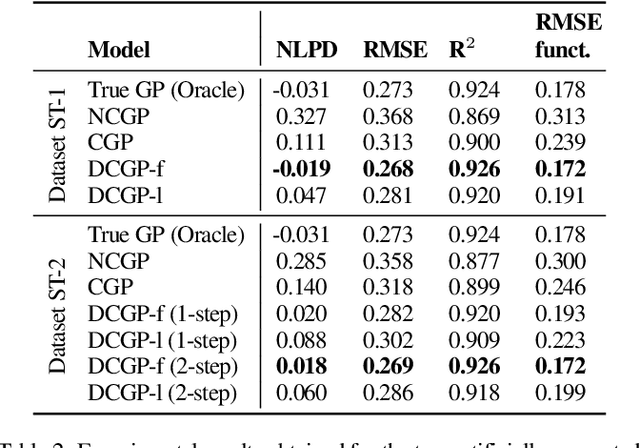
Inferring the true demand for a product or a service from aggregate data is often challenging due to the limited available supply, thus resulting in observations that are censored and correspond to the realized demand, thereby not accounting for the unsatisfied demand. Censored regression models are able to account for the effect of censoring due to the limited supply, but they don't consider the effect of substitutions, which may cause the demand for similar alternative products or services to increase. This paper proposes Diffusion-aware Censored Demand Models, which combine a Tobit likelihood with a graph diffusion process in order to model the latent process of transfer of unsatisfied demand between similar products or services. We instantiate this new class of models under the framework of GPs and, based on both simulated and real-world data for modeling sales, bike-sharing demand, and EV charging demand, demonstrate its ability to better recover the true demand and produce more accurate out-of-sample predictions.