 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Graph Neural Network for Urban Spaces: Interpolating Citywide Traffic Volume
May 07, 2025



Reliable street-level traffic volume data, covering multiple modes of transportation, helps urban planning by informing decisions on infrastructure improvements, traffic management, and public transportation. Yet, traffic sensors measuring traffic volume are typically scarcely located, due to their high deployment and maintenance costs. To address this, interpolation methods can estimate traffic volumes at unobserved locations using available data. Graph Neural Networks have shown strong performance in traffic volume forecasting, particularly on highways and major arterial networks. Applying them to urban settings, however, presents unique challenges: urban networks exhibit greater structural diversity, traffic volumes are highly overdispersed with many zeros, the best way to account for spatial dependencies remains unclear, and sensor coverage is often very sparse. We introduce the Graph Neural Network for Urban Interpolation (GNNUI), a novel urban traffic volume estimation approach. GNNUI employs a masking algorithm to learn interpolation, integrates node features to capture functional roles, and uses a loss function tailored to zero-inflated traffic distributions. In addition to the model, we introduce two new open, large-scale urban traffic volume benchmarks, covering different transportation modes: Strava cycling data from Berlin and New York City taxi data. GNNUI outperforms recent, some graph-based, interpolation methods across metrics (MAE, RMSE, true-zero rate, Kullback-Leibler divergence) and remains robust from 90% to 1% sensor coverage. On Strava, for instance, MAE rises only from 7.1 to 10.5, on Taxi from 23.0 to 40.4, demonstrating strong performance under extreme data scarcity, common in real-world urban settings. We also examine how graph connectivity choices influence model accuracy.
Deep Reinforcement Learning for Day-to-day Dynamic Tolling in Tradable Credit Schemes
Apr 10, 2025Tradable credit schemes (TCS) are an increasingly studied alternative to congestion pricing, given their revenue neutrality and ability to address issues of equity through the initial credit allocation. Modeling TCS to aid future design and implementation is associated with challenges involving user and market behaviors, demand-supply dynamics, and control mechanisms. In this paper, we focus on the latter and address the day-to-day dynamic tolling problem under TCS, which is formulated as a discrete-time Markov Decision Process and solved using reinforcement learning (RL) algorithms. Our results indicate that RL algorithms achieve travel times and social welfare comparable to the Bayesian optimization benchmark, with generalization across varying capacities and demand levels. We further assess the robustness of RL under different hyperparameters and apply regularization techniques to mitigate action oscillation, which generates practical tolling strategies that are transferable under day-to-day demand and supply variability. Finally, we discuss potential challenges such as scaling to large networks, and show how transfer learning can be leveraged to improve computational efficiency and facilitate the practical deployment of RL-based TCS solutions.
Assessing the impacts of tradable credit schemes through agent-based simulation
Feb 17, 2025Tradable credit schemes (TCS) have been attracting interest from the transportation research community as an appealing alternative to congestion pricing, due to the advantages of revenue neutrality and equity. Nonetheless, existing research has largely employed network and market equilibrium approaches with simplistic characterizations of transportation demand, supply, credit market operations, and market behavior. Agent- and activity-based simulation affords a natural means to comprehensively assess TCS by more realistically modeling demand, supply, and individual market interactions. We propose an integrated simulation framework for modeling a TCS, and implements it within the state-of-the-art open-source urban simulation platform SimMobility, including: (a) a flexible TCS design that considers multiple trips and explicitly accounts for individual trading behaviors; (b) a simulation framework that captures the complex interactions between a TCS regulator, the traveler, and the TCS market itself, with the flexibility to test future TCS designs and relevant mobility models; and (c) a set of simulation experiments on a large mesoscopic multimodal network combined with a Bayesian Optimization approach for TCS optimal design. The experiment results indicate network and market performance to stabilize over the day-to-day process, showing the alignment of our agent-based simulation with the known theoretical properties of TCS. We confirm the efficiency of TCS in reducing congestion under the adopted market behavioral assumptions and open the door for simulating different individual behaviors. We measure how TCS impacts differently the local network, heterogeneous users, the different travel behaviors, and how testing different TCS designs can avoid negative market trading behaviors.
Which cycling environment appears safer? Learning cycling safety perceptions from pairwise image comparisons
Dec 13, 2024Cycling is critical for cities to transition to more sustainable transport modes. Yet, safety concerns remain a critical deterrent for individuals to cycle. If individuals perceive an environment as unsafe for cycling, it is likely that they will prefer other means of transportation. Yet, capturing and understanding how individuals perceive cycling risk is complex and often slow, with researchers defaulting to traditional surveys and in-loco interviews. In this study, we tackle this problem. We base our approach on using pairwise comparisons of real-world images, repeatedly presenting respondents with pairs of road environments and asking them to select the one they perceive as safer for cycling, if any. Using the collected data, we train a siamese-convolutional neural network using a multi-loss framework that learns from individuals' responses, learns preferences directly from images, and includes ties (often discarded in the literature). Effectively, this model learns to predict human-style perceptions, evaluating which cycling environments are perceived as safer. Our model achieves good results, showcasing this approach has a real-life impact, such as improving interventions' effectiveness. Furthermore, it facilitates the continuous assessment of changing cycling environments, permitting short-term evaluations of measures to enhance perceived cycling safety. Finally, our method can be efficiently deployed in different locations with a growing number of openly available street-view images.
* \copyright 2024 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
Large-Scale Demand Prediction in Urban Rail using Multi-Graph Inductive Representation Learning
Aug 28, 2024
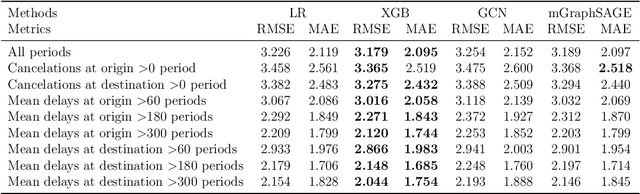

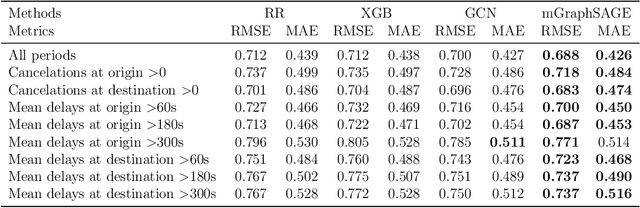
With the expansion of cities over time, URT (Urban Rail Transit) networks have also grown significantly. Demand prediction plays an important role in supporting planning, scheduling, fleet management, and other operational decisions. In this study, we propose an Origin-Destination (OD) demand prediction model called Multi-Graph Inductive Representation Learning (mGraphSAGE) for large-scale URT networks under operational uncertainties. Our main contributions are twofold: we enhance prediction results while ensuring scalability for large networks by relying simultaneously on multiple graphs, where each OD pair is a node on a graph and distinct OD relationships, such as temporal and spatial correlations; we show the importance of including operational uncertainties such as train delays and cancellations as inputs in demand prediction for daily operations. The model is validated on three different scales of the URT network in Copenhagen, Denmark. Experimental results show that by leveraging information from neighboring ODs and learning node representations via sampling and aggregation, mGraphSAGE is particularly suitable for OD demand prediction in large-scale URT networks, outperforming reference machine learning methods. Furthermore, during periods with train cancellations and delays, the performance gap between mGraphSAGE and other methods improves compared to normal operating conditions, demonstrating its ability to leverage system reliability information for predicting OD demand under uncertainty.
Deep-seeded Clustering for Unsupervised Valence-Arousal Emotion Recognition from Physiological Signals
Aug 17, 2023Emotions play a significant role in the cognitive processes of the human brain, such as decision making, learning and perception. The use of physiological signals has shown to lead to more objective, reliable and accurate emotion recognition combined with raising machine learning methods. Supervised learning methods have dominated the attention of the research community, but the challenge in collecting needed labels makes emotion recognition difficult in large-scale semi- or uncontrolled experiments. Unsupervised methods are increasingly being explored, however sub-optimal signal feature selection and label identification challenges unsupervised methods' accuracy and applicability. This article proposes an unsupervised deep cluster framework for emotion recognition from physiological and psychological data. Tests on the open benchmark data set WESAD show that deep k-means and deep c-means distinguish the four quadrants of Russell's circumplex model of affect with an overall accuracy of 87%. Seeding the clusters with the subject's subjective assessments helps to circumvent the need for labels.
Applied metamodelling for ATM performance simulations
Aug 07, 2023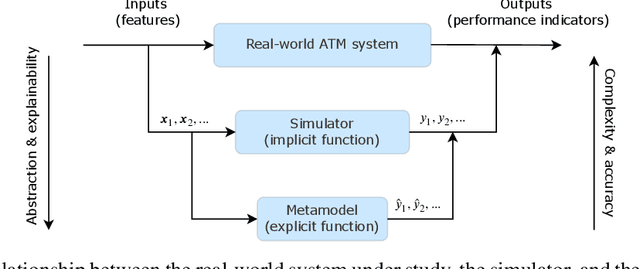
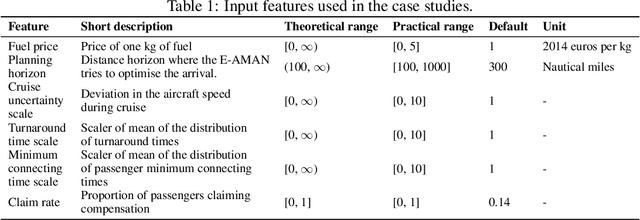
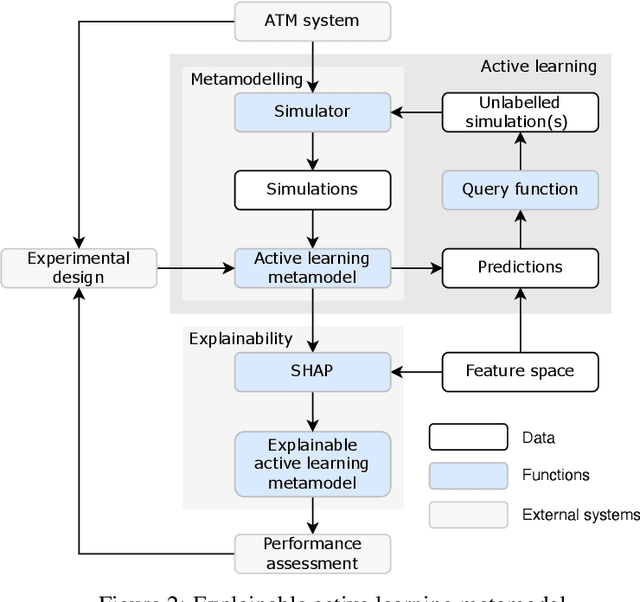
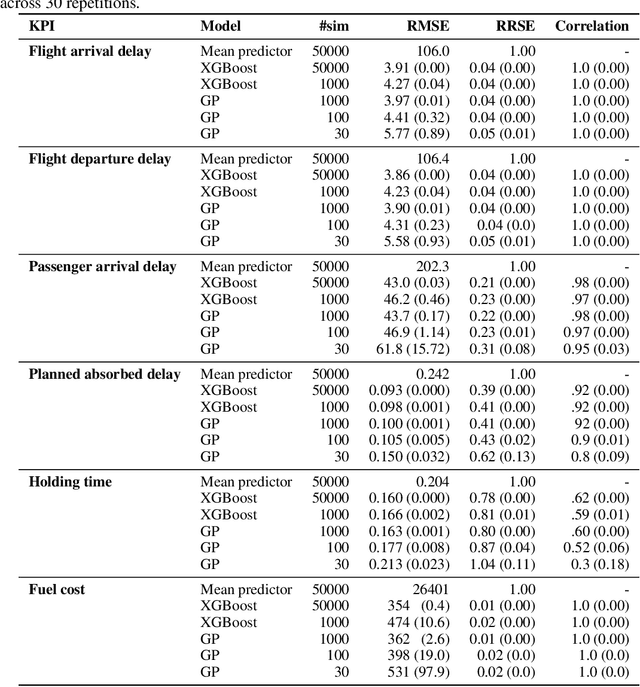
The use of Air traffic management (ATM) simulators for planing and operations can be challenging due to their modelling complexity. This paper presents XALM (eXplainable Active Learning Metamodel), a three-step framework integrating active learning and SHAP (SHapley Additive exPlanations) values into simulation metamodels for supporting ATM decision-making. XALM efficiently uncovers hidden relationships among input and output variables in ATM simulators, those usually of interest in policy analysis. Our experiments show XALM's predictive performance comparable to the XGBoost metamodel with fewer simulations. Additionally, XALM exhibits superior explanatory capabilities compared to non-active learning metamodels. Using the `Mercury' (flight and passenger) ATM simulator, XALM is applied to a real-world scenario in Paris Charles de Gaulle airport, extending an arrival manager's range and scope by analysing six variables. This case study illustrates XALM's effectiveness in enhancing simulation interpretability and understanding variable interactions. By addressing computational challenges and improving explainability, XALM complements traditional simulation-based analyses. Lastly, we discuss two practical approaches for reducing the computational burden of the metamodelling further: we introduce a stopping criterion for active learning based on the inherent uncertainty of the metamodel, and we show how the simulations used for the metamodel can be reused across key performance indicators, thus decreasing the overall number of simulations needed.
Scoring Cycling Environments Perceived Safety using Pairwise Image Comparisons
Jul 31, 2023Today, many cities seek to transition to more sustainable transportation systems. Cycling is critical in this transition for shorter trips, including first-and-last-mile links to transit. Yet, if individuals perceive cycling as unsafe, they will not cycle and choose other transportation modes. This study presents a novel approach to identifying how the perception of cycling safety can be analyzed and understood and the impact of the built environment and cycling contexts on such perceptions. We base our work on other perception studies and pairwise comparisons, using real-world images to survey respondents. We repeatedly show respondents two road environments and ask them to select the one they perceive as safer for cycling. We compare several methods capable of rating cycling environments from pairwise comparisons and classify cycling environments perceived as safe or unsafe. Urban planning can use this score to improve interventions' effectiveness and improve cycling promotion campaigns. Furthermore, this approach facilitates the continuous assessment of changing cycling environments, allows for a short-term evaluation of measures, and is efficiently deployed in different locations or contexts.
Attitudes and Latent Class Choice Models using Machine learning
Feb 20, 2023Latent Class Choice Models (LCCM) are extensions of discrete choice models (DCMs) that capture unobserved heterogeneity in the choice process by segmenting the population based on the assumption of preference similarities. We present a method of efficiently incorporating attitudinal indicators in the specification of LCCM, by introducing Artificial Neural Networks (ANN) to formulate latent variables constructs. This formulation overcomes structural equations in its capability of exploring the relationship between the attitudinal indicators and the decision choice, given the Machine Learning (ML) flexibility and power in capturing unobserved and complex behavioural features, such as attitudes and beliefs. All of this while still maintaining the consistency of the theoretical assumptions presented in the Generalized Random Utility model and the interpretability of the estimated parameters. We test our proposed framework for estimating a Car-Sharing (CS) service subscription choice with stated preference data from Copenhagen, Denmark. The results show that our proposed approach provides a complete and realistic segmentation, which helps design better policies.
Bayesian Active Learning with Fully Bayesian Gaussian Processes
May 20, 2022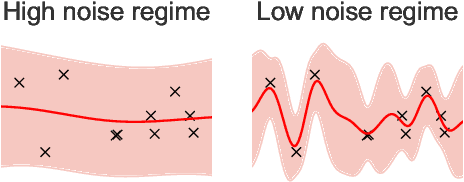
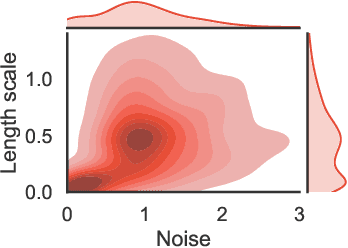
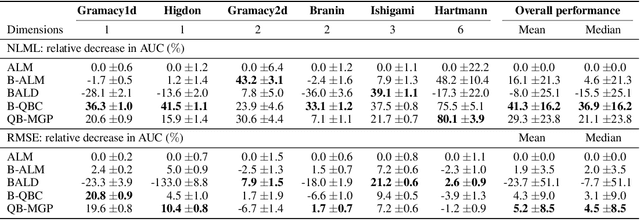
The bias-variance trade-off is a well-known problem in machine learning that only gets more pronounced the less available data there is. In active learning, where labeled data is scarce or difficult to obtain, neglecting this trade-off can cause inefficient and non-optimal querying, leading to unnecessary data labeling. In this paper, we focus on active learning with Gaussian Processes (GPs). For the GP, the bias-variance trade-off is made by optimization of the two hyperparameters: the length scale and noise-term. Considering that the optimal mode of the joint posterior of the hyperparameters is equivalent to the optimal bias-variance trade-off, we approximate this joint posterior and utilize it to design two new acquisition functions. The first one is a Bayesian variant of Query-by-Committee (B-QBC), and the second is an extension that explicitly minimizes the predictive variance through a Query by Mixture of Gaussian Processes (QB-MGP) formulation. Across six common simulators, we empirically show that B-QBC, on average, achieves the best marginal likelihood, whereas QB-MGP achieves the best predictive performance. We show that incorporating the bias-variance trade-off in the acquisition functions mitigates unnecessary and expensive data labeling.