 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Adapted Pre-trained Language Models for Implicit Information Extraction in Crash Narratives
Oct 10, 2025



Free-text crash narratives recorded in real-world crash databases have been shown to play a significant role in improving traffic safety. However, large-scale analyses remain difficult to implement as there are no documented tools that can batch process the unstructured, non standardized text content written by various authors with diverse experience and attention to detail. In recent years, Transformer-based pre-trained language models (PLMs), such as Bidirectional Encoder Representations from Transformers (BERT) and large language models (LLMs), have demonstrated strong capabilities across various natural language processing tasks. These models can extract explicit facts from crash narratives, but their performance declines on inference-heavy tasks in, for example, Crash Type identification, which can involve nearly 100 categories. Moreover, relying on closed LLMs through external APIs raises privacy concerns for sensitive crash data. Additionally, these black-box tools often underperform due to limited domain knowledge. Motivated by these challenges, we study whether compact open-source PLMs can support reasoning-intensive extraction from crash narratives. We target two challenging objectives: 1) identifying the Manner of Collision for a crash, and 2) Crash Type for each vehicle involved in the crash event from real-world crash narratives. To bridge domain gaps, we apply fine-tuning techniques to inject task-specific knowledge to LLMs with Low-Rank Adaption (LoRA) and BERT. Experiments on the authoritative real-world dataset Crash Investigation Sampling System (CISS) demonstrate that our fine-tuned compact models outperform strong closed LLMs, such as GPT-4o, while requiring only minimal training resources. Further analysis reveals that the fine-tuned PLMs can capture richer narrative details and even correct some mislabeled annotations in the dataset.
Climate Surrogates for Scalable Multi-Agent Reinforcement Learning: A Case Study with CICERO-SCM
Oct 09, 2025Climate policy studies require models that capture the combined effects of multiple greenhouse gases on global temperature, but these models are computationally expensive and difficult to embed in reinforcement learning. We present a multi-agent reinforcement learning (MARL) framework that integrates a high-fidelity, highly efficient climate surrogate directly in the environment loop, enabling regional agents to learn climate policies under multi-gas dynamics. As a proof of concept, we introduce a recurrent neural network architecture pretrained on ($20{,}000$) multi-gas emission pathways to surrogate the climate model CICERO-SCM. The surrogate model attains near-simulator accuracy with global-mean temperature RMSE $\approx 0.0004 \mathrm{K}$ and approximately $1000\times$ faster one-step inference. When substituted for the original simulator in a climate-policy MARL setting, it accelerates end-to-end training by $>\!100\times$. We show that the surrogate and simulator converge to the same optimal policies and propose a methodology to assess this property in cases where using the simulator is intractable. Our work allows to bypass the core computational bottleneck without sacrificing policy fidelity, enabling large-scale multi-agent experiments across alternative climate-policy regimes with multi-gas dynamics and high-fidelity climate response.
Learning traffic flows: Graph Neural Networks for Metamodelling Traffic Assignment
May 16, 2025



The Traffic Assignment Problem is a fundamental, yet computationally expensive, task in transportation modeling, especially for large-scale networks. Traditional methods require iterative simulations to reach equilibrium, making real-time or large-scale scenario analysis challenging. In this paper, we propose a learning-based approach using Message-Passing Neural Networks as a metamodel to approximate the equilibrium flow of the Stochastic User Equilibrium assignment. Our model is designed to mimic the algorithmic structure used in conventional traffic simulators allowing it to better capture the underlying process rather than just the data. We benchmark it against other conventional deep learning techniques and evaluate the model's robustness by testing its ability to predict traffic flows on input data outside the domain on which it was trained. This approach offers a promising solution for accelerating out-of-distribution scenario assessments, reducing computational costs in large-scale transportation planning, and enabling real-time decision-making.
A Foundational individual Mobility Prediction Model based on Open-Source Large Language Models
Mar 19, 2025



Large Language Models (LLMs) are widely applied to domain-specific tasks due to their massive general knowledge and remarkable inference capacities. Current studies on LLMs have shown immense potential in applying LLMs to model individual mobility prediction problems. However, most LLM-based mobility prediction models only train on specific datasets or use single well-designed prompts, leading to difficulty in adapting to different cities and users with diverse contexts. To fill these gaps, this paper proposes a unified fine-tuning framework to train a foundational open source LLM-based mobility prediction model. We conducted extensive experiments on six real-world mobility datasets to validate the proposed model. The results showed that the proposed model achieved the best performance in prediction accuracy and transferability over state-of-the-art models based on deep learning and LLMs.
Learning to Control Autonomous Fleets from Observation via Offline Reinforcement Learning
Feb 28, 2023Autonomous Mobility-on-Demand (AMoD) systems are a rapidly evolving mode of transportation in which a centrally coordinated fleet of self-driving vehicles dynamically serves travel requests. The control of these systems is typically formulated as a large network optimization problem, and reinforcement learning (RL) has recently emerged as a promising approach to solve the open challenges in this space. However, current RL-based approaches exclusively focus on learning from online data, fundamentally ignoring the per-sample-cost of interactions within real-world transportation systems. To address these limitations, we propose to formalize the control of AMoD systems through the lens of offline reinforcement learning and learn effective control strategies via solely offline data, thus readily available to current mobility operators. We further investigate design decisions and provide experiments on real-world mobility systems showing how offline learning allows to recover AMoD control policies that (i) exhibit performance on par with online methods, (ii) drastically improve data efficiency, and (iii) completely eliminate the need for complex simulated environments. Crucially, this paper demonstrates that offline reinforcement learning is a promising paradigm for the application of RL-based solutions within economically-critical systems, such as mobility systems.
Attitudes and Latent Class Choice Models using Machine learning
Feb 20, 2023Latent Class Choice Models (LCCM) are extensions of discrete choice models (DCMs) that capture unobserved heterogeneity in the choice process by segmenting the population based on the assumption of preference similarities. We present a method of efficiently incorporating attitudinal indicators in the specification of LCCM, by introducing Artificial Neural Networks (ANN) to formulate latent variables constructs. This formulation overcomes structural equations in its capability of exploring the relationship between the attitudinal indicators and the decision choice, given the Machine Learning (ML) flexibility and power in capturing unobserved and complex behavioural features, such as attitudes and beliefs. All of this while still maintaining the consistency of the theoretical assumptions presented in the Generalized Random Utility model and the interpretability of the estimated parameters. We test our proposed framework for estimating a Car-Sharing (CS) service subscription choice with stated preference data from Copenhagen, Denmark. The results show that our proposed approach provides a complete and realistic segmentation, which helps design better policies.
Bayesian Active Learning with Fully Bayesian Gaussian Processes
May 20, 2022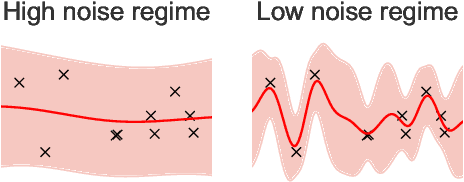
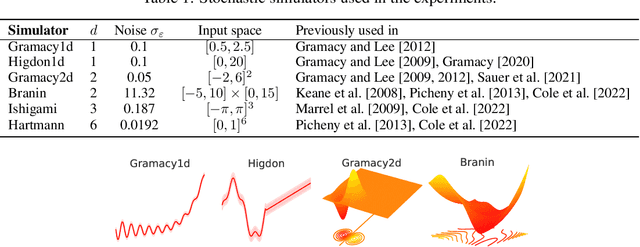
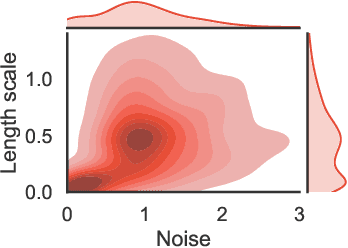
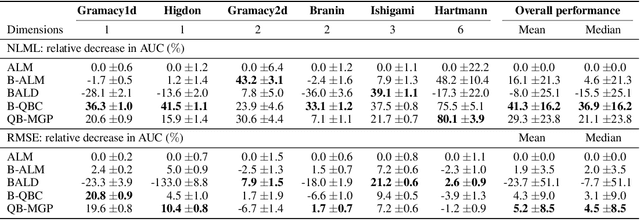
The bias-variance trade-off is a well-known problem in machine learning that only gets more pronounced the less available data there is. In active learning, where labeled data is scarce or difficult to obtain, neglecting this trade-off can cause inefficient and non-optimal querying, leading to unnecessary data labeling. In this paper, we focus on active learning with Gaussian Processes (GPs). For the GP, the bias-variance trade-off is made by optimization of the two hyperparameters: the length scale and noise-term. Considering that the optimal mode of the joint posterior of the hyperparameters is equivalent to the optimal bias-variance trade-off, we approximate this joint posterior and utilize it to design two new acquisition functions. The first one is a Bayesian variant of Query-by-Committee (B-QBC), and the second is an extension that explicitly minimizes the predictive variance through a Query by Mixture of Gaussian Processes (QB-MGP) formulation. Across six common simulators, we empirically show that B-QBC, on average, achieves the best marginal likelihood, whereas QB-MGP achieves the best predictive performance. We show that incorporating the bias-variance trade-off in the acquisition functions mitigates unnecessary and expensive data labeling.
Open vs Closed-ended questions in attitudinal surveys -- comparing, combining, and interpreting using natural language processing
May 03, 2022
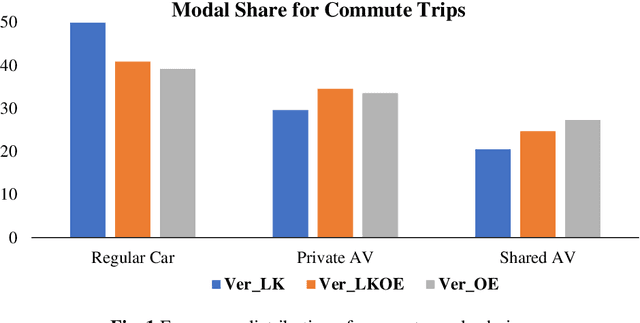
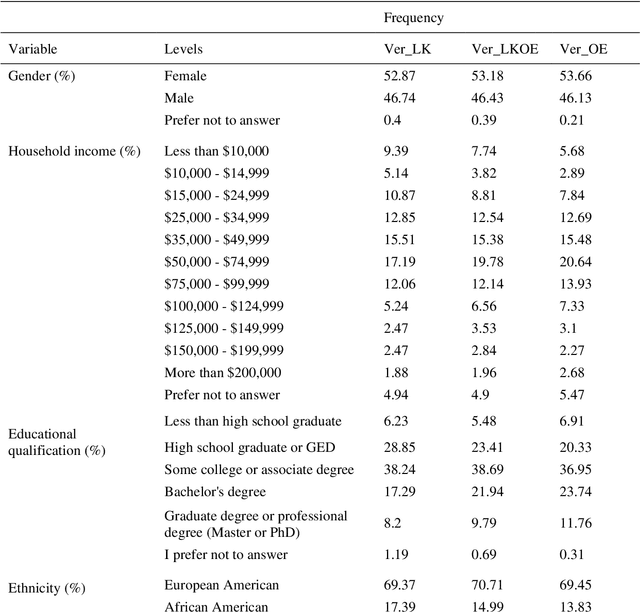
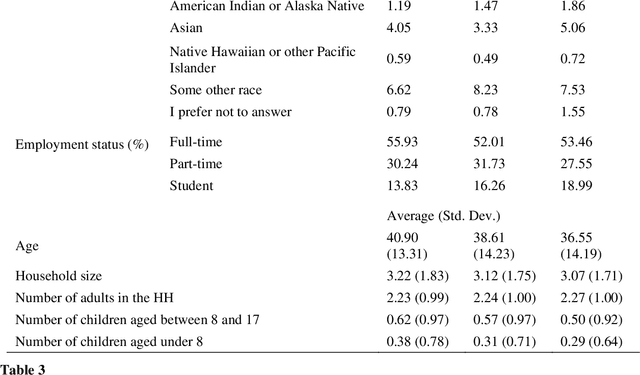
To improve the traveling experience, researchers have been analyzing the role of attitudes in travel behavior modeling. Although most researchers use closed-ended surveys, the appropriate method to measure attitudes is debatable. Topic Modeling could significantly reduce the time to extract information from open-ended responses and eliminate subjective bias, thereby alleviating analyst concerns. Our research uses Topic Modeling to extract information from open-ended questions and compare its performance with closed-ended responses. Furthermore, some respondents might prefer answering questions using their preferred questionnaire type. So, we propose a modeling framework that allows respondents to use their preferred questionnaire type to answer the survey and enable analysts to use the modeling frameworks of their choice to predict behavior. We demonstrate this using a dataset collected from the USA that measures the intention to use Autonomous Vehicles for commute trips. Respondents were presented with alternative questionnaire versions (open- and closed- ended). Since our objective was also to compare the performance of alternative questionnaire versions, the survey was designed to eliminate influences resulting from statements, behavioral framework, and the choice experiment. Results indicate the suitability of using Topic Modeling to extract information from open-ended responses; however, the models estimated using the closed-ended questions perform better compared to them. Besides, the proposed model performs better compared to the models used currently. Furthermore, our proposed framework will allow respondents to choose the questionnaire type to answer, which could be particularly beneficial to them when using voice-based surveys.
Transfer learning for cross-modal demand prediction of bike-share and public transit
Mar 17, 2022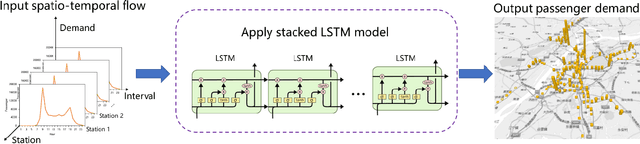
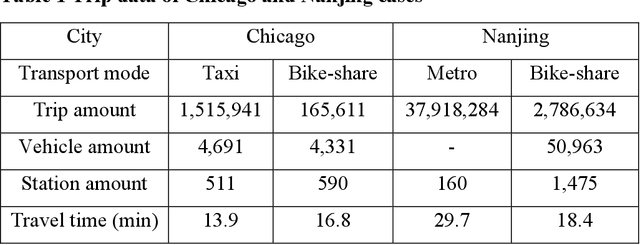
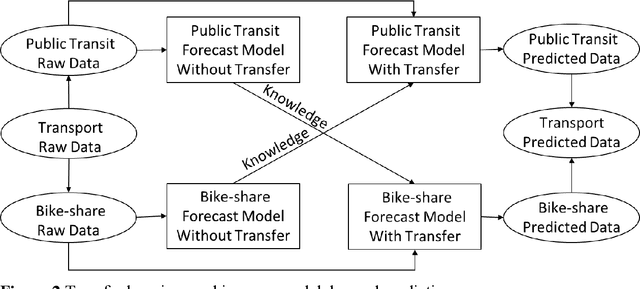
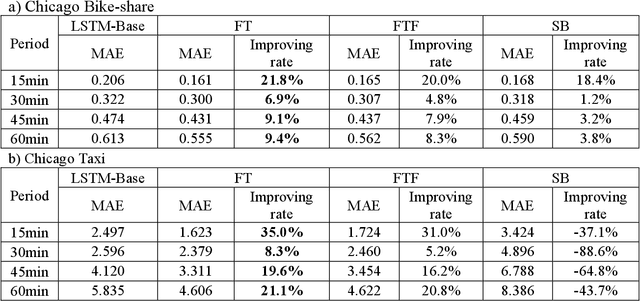
The urban transportation system is a combination of multiple transport modes, and the interdependencies across those modes exist. This means that the travel demand across different travel modes could be correlated as one mode may receive demand from or create demand for another mode, not to mention natural correlations between different demand time series due to general demand flow patterns across the network. It is expectable that cross-modal ripple effects become more prevalent, with Mobility as a Service. Therefore, by propagating demand data across modes, a better demand prediction could be obtained. To this end, this study explores various machine learning models and transfer learning strategies for cross-modal demand prediction. The trip data of bike-share, metro, and taxi are processed as the station-level passenger flows, and then the proposed prediction method is tested in the large-scale case studies of Nanjing and Chicago. The results suggest that prediction models with transfer learning perform better than unimodal prediction models. Furthermore, stacked Long Short-Term Memory model performs particularly well in cross-modal demand prediction. These results verify our combined method's forecasting improvement over existing benchmarks and demonstrate the good transferability for cross-modal demand prediction in multiple cities.
Predictive and Prescriptive Performance of Bike-Sharing Demand Forecasts for Inventory Management
Jul 28, 2021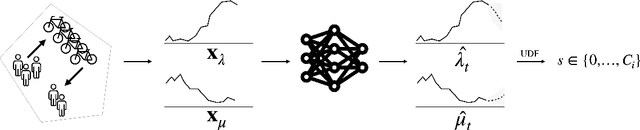
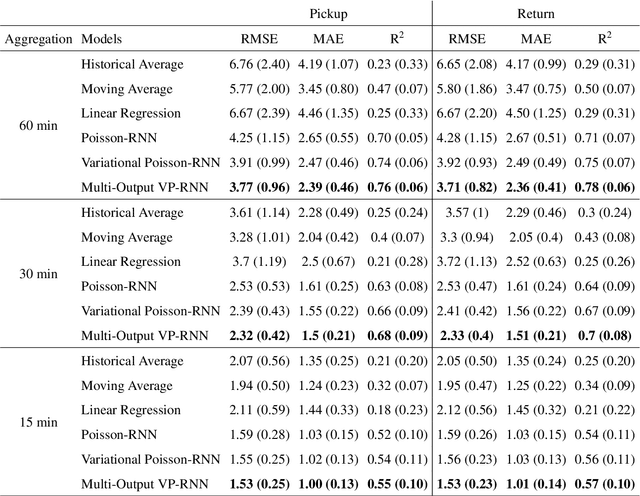
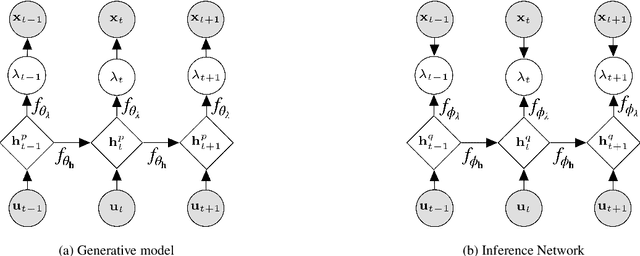

Bike-sharing systems are a rapidly developing mode of transportation and provide an efficient alternative to passive, motorized personal mobility. The asymmetric nature of bike demand causes the need for rebalancing bike stations, which is typically done during night time. To determine the optimal starting inventory level of a station for a given day, a User Dissatisfaction Function (UDF) models user pickups and returns as non-homogeneous Poisson processes with piece-wise linear rates. In this paper, we devise a deep generative model directly applicable in the UDF by introducing a variational Poisson recurrent neural network model (VP-RNN) to forecast future pickup and return rates. We empirically evaluate our approach against both traditional and learning-based forecasting methods on real trip travel data from the city of New York, USA, and show how our model outperforms benchmarks in terms of system efficiency and demand satisfaction. By explicitly focusing on the combination of decision-making algorithms with learning-based forecasting methods, we highlight a number of shortcomings in literature. Crucially, we show how more accurate predictions do not necessarily translate into better inventory decisions. By providing insights into the interplay between forecasts, model assumptions, and decisions, we point out that forecasts and decision models should be carefully evaluated and harmonized to optimally control shared mobility systems.