 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYingSound: Video-Guided Sound Effects Generation with Multi-modal Chain-of-Thought Controls
Dec 12, 2024



Generating sound effects for product-level videos, where only a small amount of labeled data is available for diverse scenes, requires the production of high-quality sounds in few-shot settings. To tackle the challenge of limited labeled data in real-world scenes, we introduce YingSound, a foundation model designed for video-guided sound generation that supports high-quality audio generation in few-shot settings. Specifically, YingSound consists of two major modules. The first module uses a conditional flow matching transformer to achieve effective semantic alignment in sound generation across audio and visual modalities. This module aims to build a learnable audio-visual aggregator (AVA) that integrates high-resolution visual features with corresponding audio features at multiple stages. The second module is developed with a proposed multi-modal visual-audio chain-of-thought (CoT) approach to generate finer sound effects in few-shot settings. Finally, an industry-standard video-to-audio (V2A) dataset that encompasses various real-world scenarios is presented. We show that YingSound effectively generates high-quality synchronized sounds across diverse conditional inputs through automated evaluations and human studies. Project Page: \url{https://giantailab.github.io/yingsound/}
Bailing-TTS: Chinese Dialectal Speech Synthesis Towards Human-like Spontaneous Representation
Aug 01, 2024



Large-scale text-to-speech (TTS) models have made significant progress recently.However, they still fall short in the generation of Chinese dialectal speech. Toaddress this, we propose Bailing-TTS, a family of large-scale TTS models capable of generating high-quality Chinese dialectal speech. Bailing-TTS serves as a foundation model for Chinese dialectal speech generation. First, continual semi-supervised learning is proposed to facilitate the alignment of text tokens and speech tokens. Second, the Chinese dialectal representation learning is developed using a specific transformer architecture and multi-stage training processes. With the proposed design of novel network architecture and corresponding strategy, Bailing-TTS is able to generate Chinese dialectal speech from text effectively and efficiently. Experiments demonstrate that Bailing-TTS generates Chinese dialectal speech towards human-like spontaneous representation. Readers are encouraged to listen to demos at \url{https://c9412600.github.io/bltts_tech_report/index.html}.
Deep learning radiomics for assessment of gastroesophageal varices in people with compensated advanced chronic liver disease
Jun 13, 2023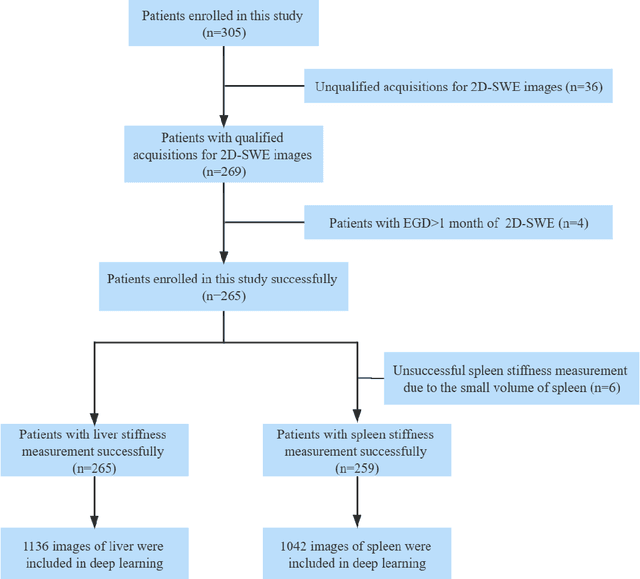
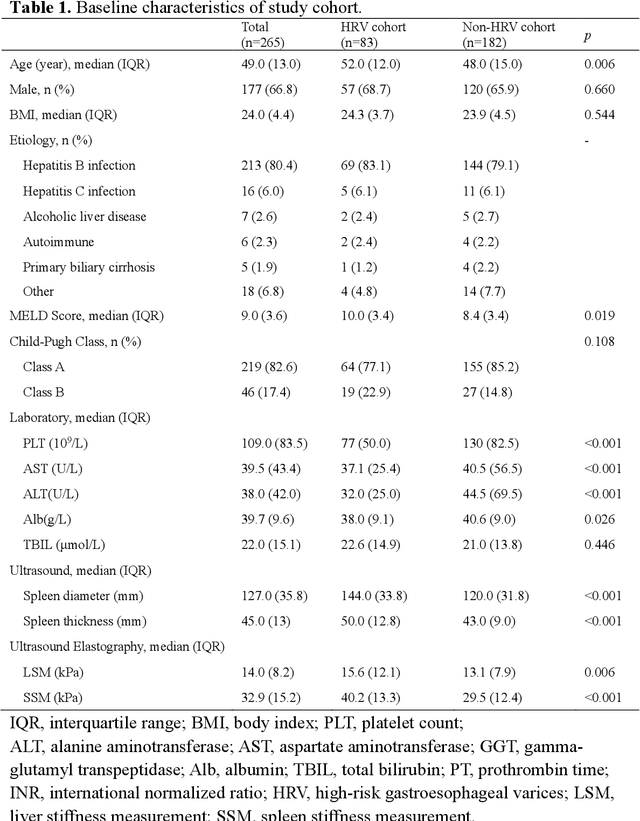
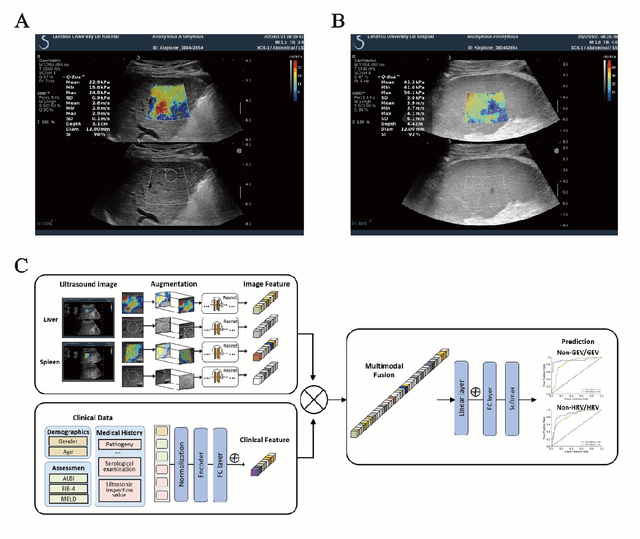
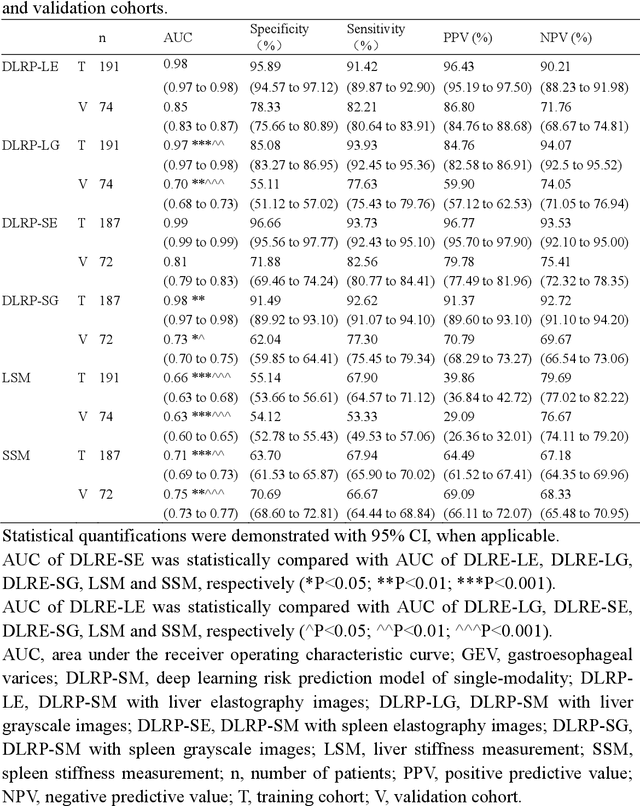
Objective: Bleeding from gastroesophageal varices (GEV) is a medical emergency associated with high mortality. We aim to construct an artificial intelligence-based model of two-dimensional shear wave elastography (2D-SWE) of the liver and spleen to precisely assess the risk of GEV and high-risk gastroesophageal varices (HRV). Design: A prospective multicenter study was conducted in patients with compensated advanced chronic liver disease. 305 patients were enrolled from 12 hospitals, and finally 265 patients were included, with 1136 liver stiffness measurement (LSM) images and 1042 spleen stiffness measurement (SSM) images generated by 2D-SWE. We leveraged deep learning methods to uncover associations between image features and patient risk, and thus conducted models to predict GEV and HRV. Results: A multi-modality Deep Learning Risk Prediction model (DLRP) was constructed to assess GEV and HRV, based on LSM and SSM images, and clinical information. Validation analysis revealed that the AUCs of DLRP were 0.91 for GEV (95% CI 0.90 to 0.93, p < 0.05) and 0.88 for HRV (95% CI 0.86 to 0.89, p < 0.01), which were significantly and robustly better than canonical risk indicators, including the value of LSM and SSM. Moreover, DLPR was better than the model using individual parameters, including LSM and SSM images. In HRV prediction, the 2D-SWE images of SSM outperform LSM (p < 0.01). Conclusion: DLRP shows excellent performance in predicting GEV and HRV over canonical risk indicators LSM and SSM. Additionally, the 2D-SWE images of SSM provided more information for better accuracy in predicting HRV than the LSM.
Predictive and Prescriptive Performance of Bike-Sharing Demand Forecasts for Inventory Management
Jul 28, 2021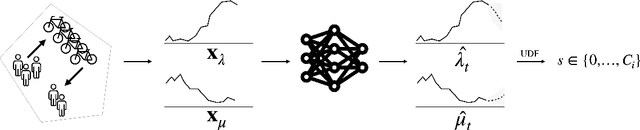
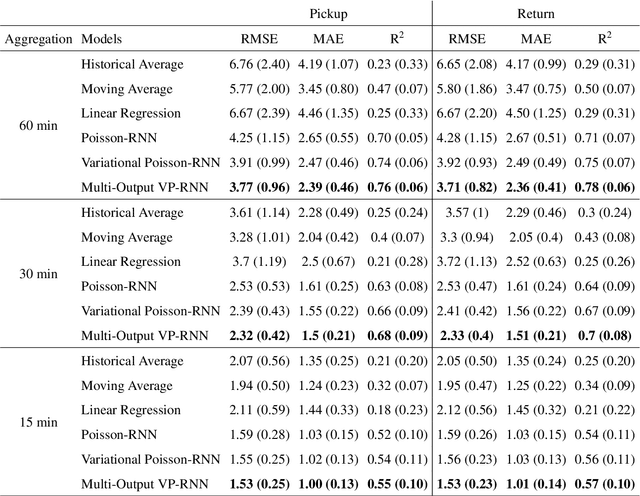
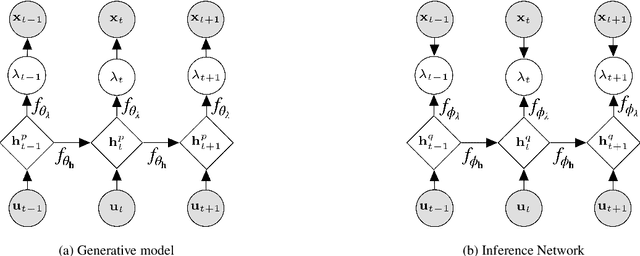

Bike-sharing systems are a rapidly developing mode of transportation and provide an efficient alternative to passive, motorized personal mobility. The asymmetric nature of bike demand causes the need for rebalancing bike stations, which is typically done during night time. To determine the optimal starting inventory level of a station for a given day, a User Dissatisfaction Function (UDF) models user pickups and returns as non-homogeneous Poisson processes with piece-wise linear rates. In this paper, we devise a deep generative model directly applicable in the UDF by introducing a variational Poisson recurrent neural network model (VP-RNN) to forecast future pickup and return rates. We empirically evaluate our approach against both traditional and learning-based forecasting methods on real trip travel data from the city of New York, USA, and show how our model outperforms benchmarks in terms of system efficiency and demand satisfaction. By explicitly focusing on the combination of decision-making algorithms with learning-based forecasting methods, we highlight a number of shortcomings in literature. Crucially, we show how more accurate predictions do not necessarily translate into better inventory decisions. By providing insights into the interplay between forecasts, model assumptions, and decisions, we point out that forecasts and decision models should be carefully evaluated and harmonized to optimally control shared mobility systems.