 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Stochastic Vehicle Routing with Time Windows
Feb 10, 2024
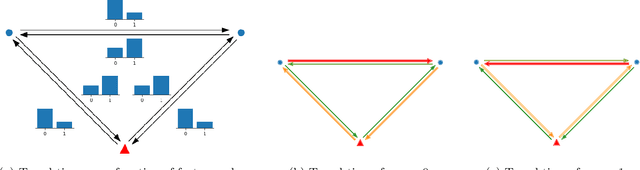
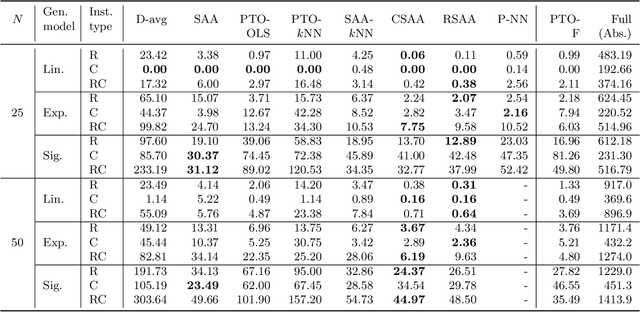
We study the vehicle routing problem with time windows (VRPTW) and stochastic travel times, in which the decision-maker observes related contextual information, represented as feature variables, before making routing decisions. Despite the extensive literature on stochastic VRPs, the integration of feature variables has received limited attention in this context. We introduce the contextual stochastic VRPTW, which minimizes the total transportation cost and expected late arrival penalties conditioned on the observed features. Since the joint distribution of travel times and features is unknown, we present novel data-driven prescriptive models that use historical data to provide an approximate solution to the problem. We distinguish the prescriptive models between point-based approximation, sample average approximation, and penalty-based approximation, each taking a different perspective on dealing with stochastic travel times and features. We develop specialized branch-price-and-cut algorithms to solve these data-driven prescriptive models. In our computational experiments, we compare the out-of-sample cost performance of different methods on instances with up to one hundred customers. Our results show that, surprisingly, a feature-dependent sample average approximation outperforms existing and novel methods in most settings.
Spatial-temporal-demand clustering for solving large-scale vehicle routing problems with time windows
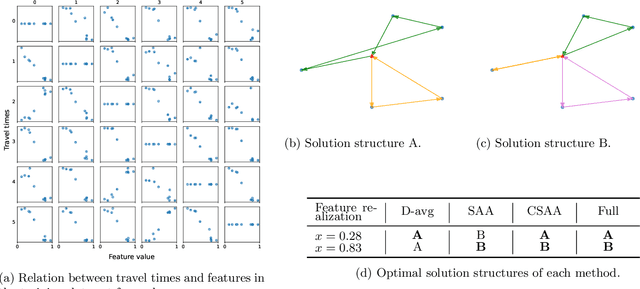
Jan 20, 2024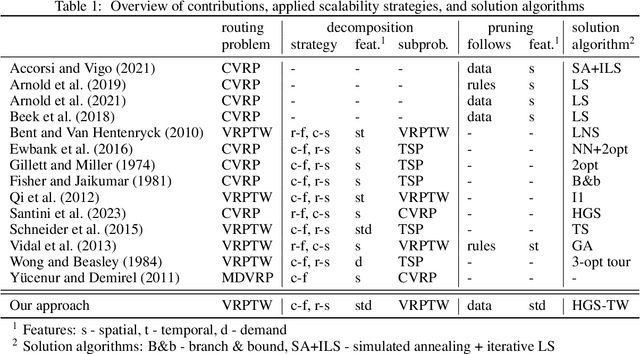
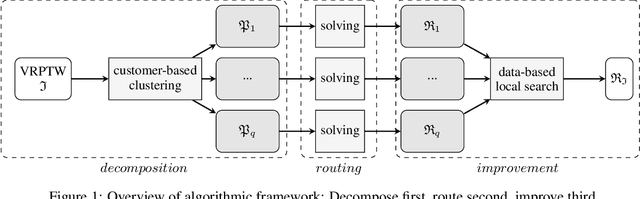

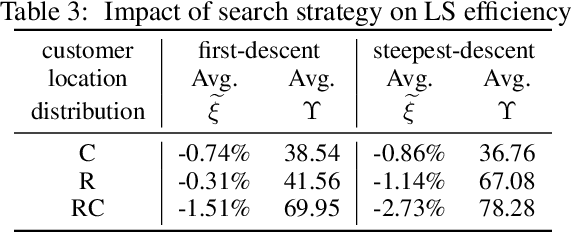
Several metaheuristics use decomposition and pruning strategies to solve large-scale instances of the vehicle routing problem (VRP). Those complexity reduction techniques often rely on simple, problem-specific rules. However, the growth in available data and advances in computer hardware enable data-based approaches that use machine learning (ML) to improve scalability of solution algorithms. We propose a decompose-route-improve (DRI) framework that groups customers using clustering. Its similarity metric incorporates customers' spatial, temporal, and demand data and is formulated to reflect the problem's objective function and constraints. The resulting sub-routing problems can independently be solved using any suitable algorithm. We apply pruned local search (LS) between solved subproblems to improve the overall solution. Pruning is based on customers' similarity information obtained in the decomposition phase. In a computational study, we parameterize and compare existing clustering algorithms and benchmark the DRI against the Hybrid Genetic Search (HGS) of Vidal et al. (2013). Results show that our data-based approach outperforms classic cluster-first, route-second approaches solely based on customers' spatial information. The newly introduced similarity metric forms separate sub-VRPs and improves the selection of LS moves in the improvement phase. Thus, the DRI scales existing metaheuristics to achieve high-quality solutions faster for large-scale VRPs by efficiently reducing complexity. Further, the DRI can be easily adapted to various solution methods and VRP characteristics, such as distribution of customer locations and demands, depot location, and different time window scenarios, making it a generalizable approach to solving routing problems.
Bilevel Optimization for Feature Selection in the Data-Driven Newsvendor Problem
Sep 12, 2022
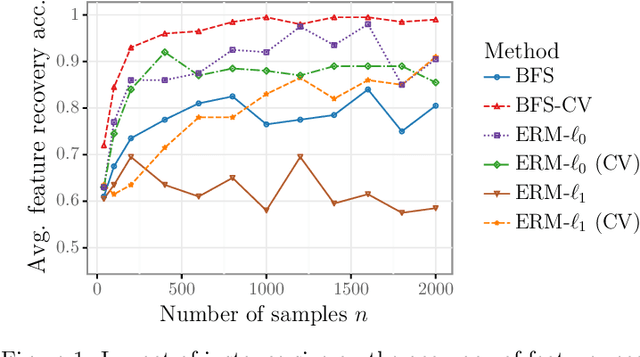
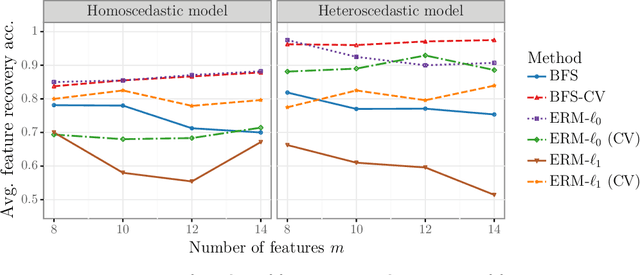
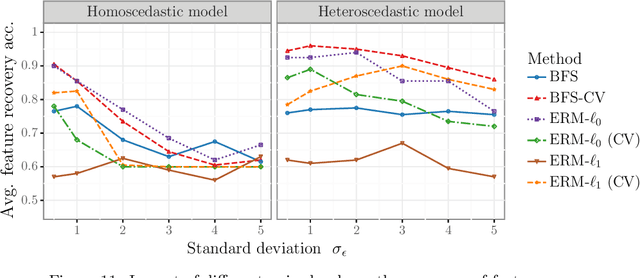
We study the feature-based newsvendor problem, in which a decision-maker has access to historical data consisting of demand observations and exogenous features. In this setting, we investigate feature selection, aiming to derive sparse, explainable models with improved out-of-sample performance. Up to now, state-of-the-art methods utilize regularization, which penalizes the number of selected features or the norm of the solution vector. As an alternative, we introduce a novel bilevel programming formulation. The upper-level problem selects a subset of features that minimizes an estimate of the out-of-sample cost of ordering decisions based on a held-out validation set. The lower-level problem learns the optimal coefficients of the decision function on a training set, using only the features selected by the upper-level. We present a mixed integer linear program reformulation for the bilevel program, which can be solved to optimality with standard optimization solvers. Our computational experiments show that the method accurately recovers ground-truth features already for instances with a sample size of a few hundred observations. In contrast, regularization-based techniques often fail at feature recovery or require thousands of observations to obtain similar accuracy. Regarding out-of-sample generalization, we achieve improved or comparable cost performance.
Predictive and Prescriptive Performance of Bike-Sharing Demand Forecasts for Inventory Management
Jul 28, 2021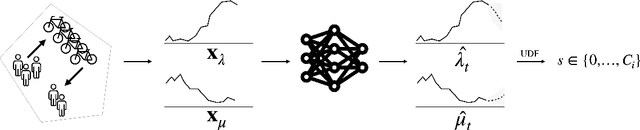
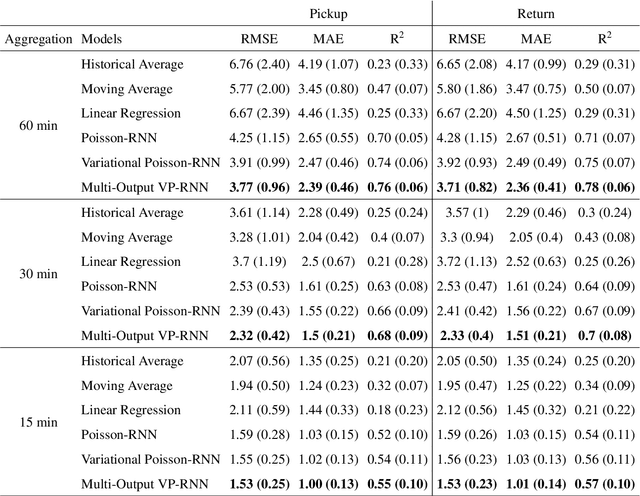
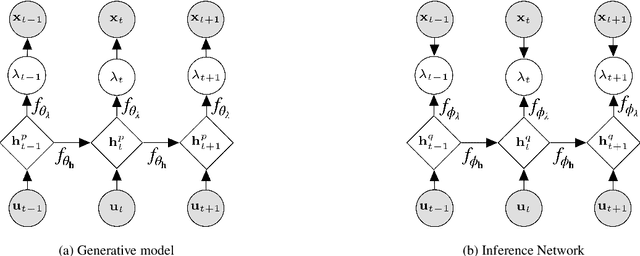

Bike-sharing systems are a rapidly developing mode of transportation and provide an efficient alternative to passive, motorized personal mobility. The asymmetric nature of bike demand causes the need for rebalancing bike stations, which is typically done during night time. To determine the optimal starting inventory level of a station for a given day, a User Dissatisfaction Function (UDF) models user pickups and returns as non-homogeneous Poisson processes with piece-wise linear rates. In this paper, we devise a deep generative model directly applicable in the UDF by introducing a variational Poisson recurrent neural network model (VP-RNN) to forecast future pickup and return rates. We empirically evaluate our approach against both traditional and learning-based forecasting methods on real trip travel data from the city of New York, USA, and show how our model outperforms benchmarks in terms of system efficiency and demand satisfaction. By explicitly focusing on the combination of decision-making algorithms with learning-based forecasting methods, we highlight a number of shortcomings in literature. Crucially, we show how more accurate predictions do not necessarily translate into better inventory decisions. By providing insights into the interplay between forecasts, model assumptions, and decisions, we point out that forecasts and decision models should be carefully evaluated and harmonized to optimally control shared mobility systems.