 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPEX: Probing Neural Networks via Activation Perturbation
Feb 03, 2026Prior work on probing neural networks primarily relies on input-space analysis or parameter perturbation, both of which face fundamental limitations in accessing structural information encoded in intermediate representations. We introduce Activation Perturbation for EXploration (APEX), an inference-time probing paradigm that perturbs hidden activations while keeping both inputs and model parameters fixed. We theoretically show that activation perturbation induces a principled transition from sample-dependent to model-dependent behavior by suppressing input-specific signals and amplifying representation-level structure, and further establish that input perturbation corresponds to a constrained special case of this framework. Through representative case studies, we demonstrate the practical advantages of APEX. In the small-noise regime, APEX provides a lightweight and efficient measure of sample regularity that aligns with established metrics, while also distinguishing structured from randomly labeled models and revealing semantically coherent prediction transitions. In the large-noise regime, APEX exposes training-induced model-level biases, including a pronounced concentration of predictions on the target class in backdoored models. Overall, our results show that APEX offers an effective perspective for exploring, and understanding neural networks beyond what is accessible from input space alone.
AI Meets Brain: Memory Systems from Cognitive Neuroscience to Autonomous Agents
Dec 29, 2025Memory serves as the pivotal nexus bridging past and future, providing both humans and AI systems with invaluable concepts and experience to navigate complex tasks. Recent research on autonomous agents has increasingly focused on designing efficient memory workflows by drawing on cognitive neuroscience. However, constrained by interdisciplinary barriers, existing works struggle to assimilate the essence of human memory mechanisms. To bridge this gap, we systematically synthesizes interdisciplinary knowledge of memory, connecting insights from cognitive neuroscience with LLM-driven agents. Specifically, we first elucidate the definition and function of memory along a progressive trajectory from cognitive neuroscience through LLMs to agents. We then provide a comparative analysis of memory taxonomy, storage mechanisms, and the complete management lifecycle from both biological and artificial perspectives. Subsequently, we review the mainstream benchmarks for evaluating agent memory. Additionally, we explore memory security from dual perspectives of attack and defense. Finally, we envision future research directions, with a focus on multimodal memory systems and skill acquisition.
SCOUT: Teaching Pre-trained Language Models to Enhance Reasoning via Flow Chain-of-Thought
May 30, 2025Chain of Thought (CoT) prompting improves the reasoning performance of large language models (LLMs) by encouraging step by step thinking. However, CoT-based methods depend on intermediate reasoning steps, which limits scalability and generalization. Recent work explores recursive reasoning, where LLMs reuse internal layers across iterations to refine latent representations without explicit CoT supervision. While promising, these approaches often require costly pretraining and lack a principled framework for how reasoning should evolve across iterations. We address this gap by introducing Flow Chain of Thought (Flow CoT), a reasoning paradigm that models recursive inference as a progressive trajectory of latent cognitive states. Flow CoT frames each iteration as a distinct cognitive stage deepening reasoning across iterations without relying on manual supervision. To realize this, we propose SCOUT (Stepwise Cognitive Optimization Using Teachers), a lightweight fine tuning framework that enables Flow CoT style reasoning without the need for pretraining. SCOUT uses progressive distillation to align each iteration with a teacher of appropriate capacity, and a cross attention based retrospective module that integrates outputs from previous iterations while preserving the models original computation flow. Experiments across eight reasoning benchmarks show that SCOUT consistently improves both accuracy and explanation quality, achieving up to 1.8% gains under fine tuning. Qualitative analyses further reveal that SCOUT enables progressively deeper reasoning across iterations refining both belief formation and explanation granularity. These results not only validate the effectiveness of SCOUT, but also demonstrate the practical viability of Flow CoT as a scalable framework for enhancing reasoning in LLMs.
Bridging the Editing Gap in LLMs: FineEdit for Precise and Targeted Text Modifications
Feb 19, 2025Large Language Models (LLMs) have transformed natural language processing, yet they still struggle with direct text editing tasks that demand precise, context-aware modifications. While models like ChatGPT excel in text generation and analysis, their editing abilities often fall short, addressing only superficial issues rather than deeper structural or logical inconsistencies. In this work, we introduce a dual approach to enhance LLMs editing performance. First, we present InstrEditBench, a high-quality benchmark dataset comprising over 20,000 structured editing tasks spanning Wiki articles, LaTeX documents, code, and database Domain-specific Languages (DSL). InstrEditBench is generated using an innovative automated workflow that accurately identifies and evaluates targeted edits, ensuring that modifications adhere strictly to specified instructions without altering unrelated content. Second, we propose FineEdit, a specialized model trained on this curated benchmark. Experimental results demonstrate that FineEdit achieves significant improvements around {10\%} compared with Gemini on direct editing tasks, convincingly validating its effectiveness.
Infant Agent: A Tool-Integrated, Logic-Driven Agent with Cost-Effective API Usage
Nov 02, 2024



Despite the impressive capabilities of large language models (LLMs), they currently exhibit two primary limitations, \textbf{\uppercase\expandafter{\romannumeral 1}}: They struggle to \textbf{autonomously solve the real world engineering problem}. \textbf{\uppercase\expandafter{\romannumeral 2}}: They remain \textbf{challenged in reasoning through complex logic problems}. To address these challenges, we developed the \textsc{Infant Agent}, integrating task-aware functions, operators, a hierarchical management system, and a memory retrieval mechanism. Together, these components enable large language models to sustain extended reasoning processes and handle complex, multi-step tasks efficiently, all while significantly reducing API costs. Using the \textsc{Infant Agent}, GPT-4o's accuracy on the SWE-bench-lite dataset rises from $\mathbf{0.33\%}$ to $\mathbf{30\%}$, and in the AIME-2024 mathematics competition, it increases GPT-4o's accuracy from $\mathbf{13.3\%}$ to $\mathbf{37\%}$.
FLOPS: Forward Learning with OPtimal Sampling
Oct 08, 2024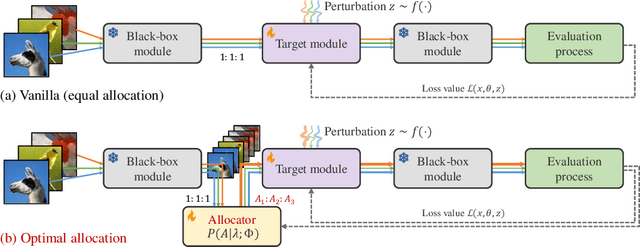
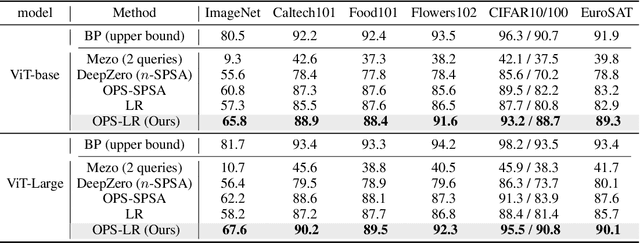
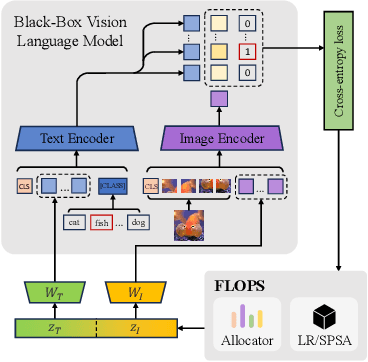
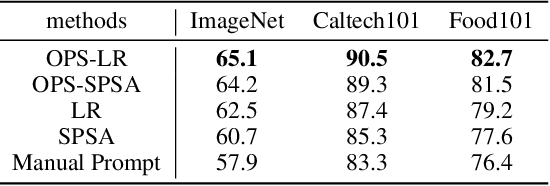
Given the limitations of backpropagation, perturbation-based gradient computation methods have recently gained focus for learning with only forward passes, also referred to as queries. Conventional forward learning consumes enormous queries on each data point for accurate gradient estimation through Monte Carlo sampling, which hinders the scalability of those algorithms. However, not all data points deserve equal queries for gradient estimation. In this paper, we study the problem of improving the forward learning efficiency from a novel perspective: how to reduce the gradient estimation variance with minimum cost? For this, we propose to allocate the optimal number of queries over each data in one batch during training to achieve a good balance between estimation accuracy and computational efficiency. Specifically, with a simplified proxy objective and a reparameterization technique, we derive a novel plug-and-play query allocator with minimal parameters. Theoretical results are carried out to verify its optimality. We conduct extensive experiments for fine-tuning Vision Transformers on various datasets and further deploy the allocator to two black-box applications: prompt tuning and multimodal alignment for foundation models. All findings demonstrate that our proposed allocator significantly enhances the scalability of forward-learning algorithms, paving the way for real-world applications.
Deep Reinforcement Learning for Solving Management Problems: Towards A Large Management Mode
Mar 01, 2024We introduce a deep reinforcement learning (DRL) approach for solving management problems including inventory management, dynamic pricing, and recommendation. This DRL approach has the potential to lead to a large management model based on certain transformer neural network structures, resulting in an artificial general intelligence paradigm for various management tasks. Traditional methods have limitations for solving complex real-world problems, and we demonstrate how DRL can surpass existing heuristic approaches for solving management tasks. We aim to solve the problems in a unified framework, considering the interconnections between different tasks. Central to our methodology is the development of a foundational decision model coordinating decisions across the different domains through generative decision-making. Our experimental results affirm the effectiveness of our DRL-based framework in complex and dynamic business environments. This work opens new pathways for the application of DRL in management problems, highlighting its potential to revolutionize traditional business management.
NID-SLAM: Neural Implicit Representation-based RGB-D SLAM in dynamic environments
Jan 02, 2024Neural implicit representations have been explored to enhance visual SLAM algorithms, especially in providing high-fidelity dense map. Existing methods operate robustly in static scenes but struggle with the disruption caused by moving objects. In this paper we present NID-SLAM, which significantly improves the performance of neural SLAM in dynamic environments. We propose a new approach to enhance inaccurate regions in semantic masks, particularly in marginal areas. Utilizing the geometric information present in depth images, this method enables accurate removal of dynamic objects, thereby reducing the probability of camera drift. Additionally, we introduce a keyframe selection strategy for dynamic scenes, which enhances camera tracking robustness against large-scale objects and improves the efficiency of mapping. Experiments on publicly available RGB-D datasets demonstrate that our method outperforms competitive neural SLAM approaches in tracking accuracy and mapping quality in dynamic environments.
RED: A Systematic Real-Time Scheduling Approach for Robotic Environmental Dynamics
Aug 29, 2023Intelligent robots are designed to effectively navigate dynamic and unpredictable environments laden with moving mechanical elements and objects. Such environment-induced dynamics, including moving obstacles, can readily alter the computational demand (e.g., the creation of new tasks) and the structure of workloads (e.g., precedence constraints among tasks) during runtime, thereby adversely affecting overall system performance. This challenge is amplified when multi-task inference is expected on robots operating under stringent resource and real-time constraints. To address such a challenge, we introduce RED, a systematic real-time scheduling approach designed to support multi-task deep neural network workloads in resource-limited robotic systems. It is designed to adaptively manage the Robotic Environmental Dynamics (RED) while adhering to real-time constraints. At the core of RED lies a deadline-based scheduler that employs an intermediate deadline assignment policy, effectively managing to change workloads and asynchronous inference prompted by complex, unpredictable environments. This scheduling framework also facilitates the flexible deployment of MIMONet (multi-input multi-output neural networks), which are commonly utilized in multi-tasking robotic systems to circumvent memory bottlenecks. Building on this scheduling framework, RED recognizes and leverages a unique characteristic of MIMONet: its weight-shared architecture. To further accommodate and exploit this feature, RED devises a novel and effective workload refinement and reconstruction process. This process ensures the scheduling framework's compatibility with MIMONet and maximizes efficiency.
Deep learning radiomics for assessment of gastroesophageal varices in people with compensated advanced chronic liver disease
Jun 13, 2023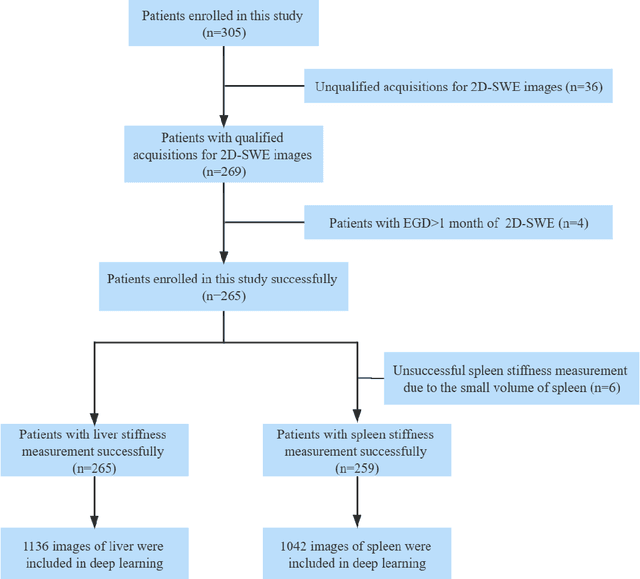
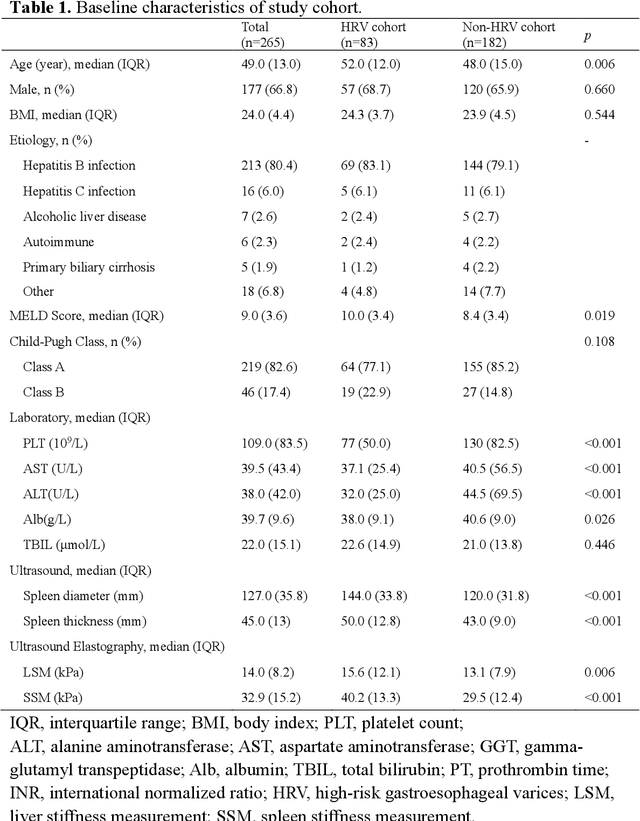
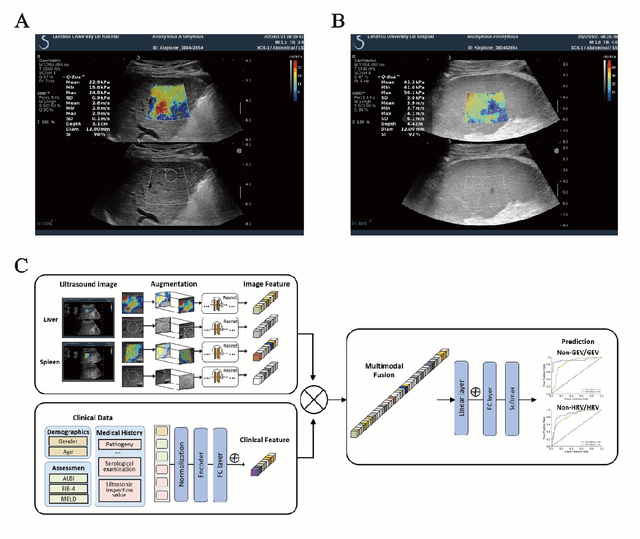
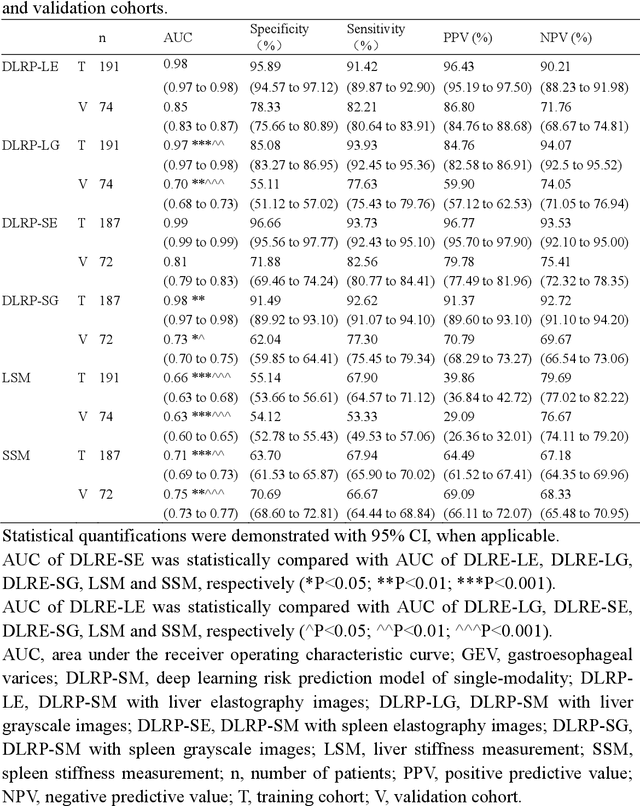
Objective: Bleeding from gastroesophageal varices (GEV) is a medical emergency associated with high mortality. We aim to construct an artificial intelligence-based model of two-dimensional shear wave elastography (2D-SWE) of the liver and spleen to precisely assess the risk of GEV and high-risk gastroesophageal varices (HRV). Design: A prospective multicenter study was conducted in patients with compensated advanced chronic liver disease. 305 patients were enrolled from 12 hospitals, and finally 265 patients were included, with 1136 liver stiffness measurement (LSM) images and 1042 spleen stiffness measurement (SSM) images generated by 2D-SWE. We leveraged deep learning methods to uncover associations between image features and patient risk, and thus conducted models to predict GEV and HRV. Results: A multi-modality Deep Learning Risk Prediction model (DLRP) was constructed to assess GEV and HRV, based on LSM and SSM images, and clinical information. Validation analysis revealed that the AUCs of DLRP were 0.91 for GEV (95% CI 0.90 to 0.93, p < 0.05) and 0.88 for HRV (95% CI 0.86 to 0.89, p < 0.01), which were significantly and robustly better than canonical risk indicators, including the value of LSM and SSM. Moreover, DLPR was better than the model using individual parameters, including LSM and SSM images. In HRV prediction, the 2D-SWE images of SSM outperform LSM (p < 0.01). Conclusion: DLRP shows excellent performance in predicting GEV and HRV over canonical risk indicators LSM and SSM. Additionally, the 2D-SWE images of SSM provided more information for better accuracy in predicting HRV than the LSM.