 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSACRED: A Faithful Annotated Multimedia Multimodal Multilingual Dataset for Classifying Connectedness Types in Online Spirituality
Mar 28, 2026In religion and theology studies, spirituality has garnered significant research attention for the reason that it not only transcends culture but offers unique experience to each individual. However, social scientists often rely on limited datasets, which are basically unavailable online. In this study, we collaborated with social scientists to develop a high-quality multimedia multi-modal datasets, \textbf{SACRED}, in which the faithfulness of classification is guaranteed. Using \textbf{SACRED}, we evaluated the performance of 13 popular LLMs as well as traditional rule-based and fine-tuned approaches. The result suggests DeepSeek-V3 model performs well in classifying such abstract concepts (i.e., 79.19\% accuracy in the Quora test set), and the GPT-4o-mini model surpassed the other models in the vision tasks (63.99\% F1 score). Purportedly, this is the first annotated multi-modal dataset from online spirituality communication. Our study also found a new type of connectedness which is valuable for communication science studies.
Optimal low-rank stochastic gradient estimation for LLM training
Mar 21, 2026Large language model (LLM) training is often bottlenecked by memory constraints and stochastic gradient noise in extremely high-dimensional parameter spaces. Motivated by empirical evidence that many LLM gradient matrices are effectively low-rank during training, we present an unbiased, memory-efficient, low-rank matrix estimator with the lowest variance that is applicable across common stochastic gradient estimation paradigms. The core idea is to project a high-dimensional stochastic gradient estimator onto a random low-dimensional subspace and lift it back, reducing memory while keeping the estimator unbiased and controlling mean-squared error via an optimally designed projection distribution, including Haar--Stiefel projections. The projection distribution is derived by solving a constrained functional optimization problem, yielding an optimal random projector that guides algorithm design. Empirically, the resulting low-rank gradient estimators deliver both practical memory savings and improved training behavior. In RoBERTa-large fine-tuning, our method attains the lowest peak GPU memory among compared methods (e.g., 3.83GB versus 16.7GB for full BP) while remaining competitive in accuracy; in autoregressive LLM pretraining (LLaMA-20M/60M/100M), our method outperforms the traditional methods, supporting the benefit of the proposed optimal projection strategy.
Nonparametric Bayesian Optimization for General Rewards
Feb 07, 2026This work focuses on Bayesian optimization (BO) under reward model uncertainty. We propose the first BO algorithm that achieves no-regret guarantee in a general reward setting, requiring only Lipschitz continuity of the objective function and accommodating a broad class of measurement noise. The core of our approach is a novel surrogate model, termed as infinite Gaussian process ($\infty$-GP). It is a Bayesian nonparametric model that places a prior on the space of reward distributions, enabling it to represent a substantially broader class of reward models than classical Gaussian process (GP). The $\infty$-GP is used in combination with Thompson Sampling (TS) to enable effective exploration and exploitation. Correspondingly, we develop a new TS regret analysis framework for general rewards, which relates the regret to the total variation distance between the surrogate model and the true reward distribution. Furthermore, with a truncated Gibbs sampling procedure, our method is computationally scalable, incurring minimal additional memory and computational complexities compared to classical GP. Empirical results demonstrate state-of-the-art performance, particularly in settings with non-stationary, heavy-tailed, or other ill-conditioned rewards.
LLM-Inspired Pretrain-Then-Finetune for Small-Data, Large-Scale Optimization
Feb 03, 2026We consider small-data, large-scale decision problems in which a firm must make many operational decisions simultaneously (e.g., across a large product portfolio) while observing only a few, potentially noisy, data points per instance. Inspired by the success of large language models (LLMs), we propose a pretrain-then-finetune approach built on a designed Transformer model to address this challenge. The model is first pretrained on large-scale, domain-informed synthetic data that encode managerial knowledge and structural features of the decision environment, and is then fine-tuned on real observations. This new pipeline offers two complementary advantages: pretraining injects domain knowledge into the learning process and enables the training of high-capacity models using abundant synthetic data, while finetuning adapts the pretrained model to the operational environment and improves alignment with the true data-generating regime. While we have leveraged the Transformer's state-of-the-art representational capacity, particularly its attention mechanism, to efficiently extract cross-task structure, our approach is not an off-the-shelf application. Instead, it relies on problem-specific architectural design and a tailored training procedure to match the decision setting. Theoretically, we develop the first comprehensive error analysis regarding Transformer learning in relevant contexts, establishing nonasymptotic guarantees that validate the method's effectiveness. Critically, our analysis reveals how pretraining and fine-tuning jointly determine performance, with the dominant contribution governed by whichever is more favorable. In particular, finetuning exhibits an economies-of-scale effect, whereby transfer learning becomes increasingly effective as the number of instances grows.
FLOPS: Forward Learning with OPtimal Sampling
Oct 08, 2024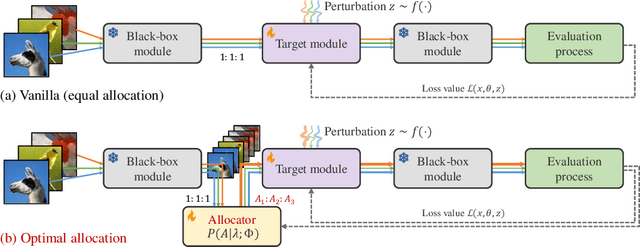
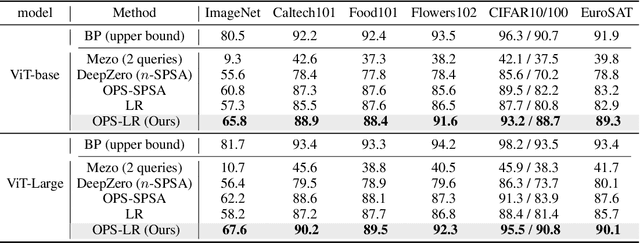
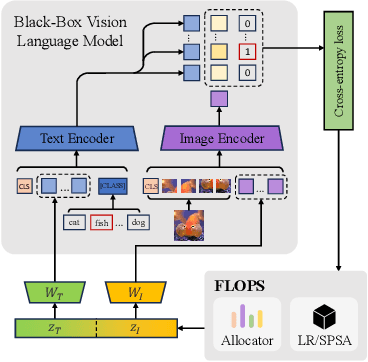
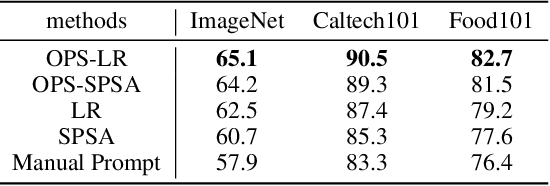
Given the limitations of backpropagation, perturbation-based gradient computation methods have recently gained focus for learning with only forward passes, also referred to as queries. Conventional forward learning consumes enormous queries on each data point for accurate gradient estimation through Monte Carlo sampling, which hinders the scalability of those algorithms. However, not all data points deserve equal queries for gradient estimation. In this paper, we study the problem of improving the forward learning efficiency from a novel perspective: how to reduce the gradient estimation variance with minimum cost? For this, we propose to allocate the optimal number of queries over each data in one batch during training to achieve a good balance between estimation accuracy and computational efficiency. Specifically, with a simplified proxy objective and a reparameterization technique, we derive a novel plug-and-play query allocator with minimal parameters. Theoretical results are carried out to verify its optimality. We conduct extensive experiments for fine-tuning Vision Transformers on various datasets and further deploy the allocator to two black-box applications: prompt tuning and multimodal alignment for foundation models. All findings demonstrate that our proposed allocator significantly enhances the scalability of forward-learning algorithms, paving the way for real-world applications.
Sample-Efficient Clustering and Conquer Procedures for Parallel Large-Scale Ranking and Selection
Feb 13, 2024



We propose novel "clustering and conquer" procedures for the parallel large-scale ranking and selection (R&S) problem, which leverage correlation information for clustering to break the bottleneck of sample efficiency. In parallel computing environments, correlation-based clustering can achieve an $\mathcal{O}(p)$ sample complexity reduction rate, which is the optimal reduction rate theoretically attainable. Our proposed framework is versatile, allowing for seamless integration of various prevalent R&S methods under both fixed-budget and fixed-precision paradigms. It can achieve improvements without the necessity of highly accurate correlation estimation and precise clustering. In large-scale AI applications such as neural architecture search, a screening-free version of our procedure surprisingly surpasses fully-sequential benchmarks in terms of sample efficiency. This suggests that leveraging valuable structural information, such as correlation, is a viable path to bypassing the traditional need for screening via pairwise comparison--a step previously deemed essential for high sample efficiency but problematic for parallelization. Additionally, we propose a parallel few-shot clustering algorithm tailored for large-scale problems.