 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Robust Estimator for Multi-Agent Reinforcement Learning
Mar 23, 2026Multi-agent collaboration has emerged as a powerful paradigm for enhancing the reasoning capabilities of large language models, yet it suffers from interaction-level ambiguity that blurs generation, critique, and revision, making credit assignment across agents difficult. Moreover, policy optimization in this setting is vulnerable to heavy-tailed and noisy rewards, which can bias advantage estimation and trigger unstable or even divergent training. To address both issues, we propose a robust multi-agent reinforcement learning framework for collaborative reasoning, consisting of two components: Dual-Agent Answer-Critique-Rewrite (DACR) and an Adaptive Robust Estimator (ARE). DACR decomposes reasoning into a structured three-stage pipeline: answer, critique, and rewrite, while enabling explicit attribution of each agent's marginal contribution to its partner's performance. ARE provides robust estimation of batch experience means during multi-agent policy optimization. Across mathematical reasoning and embodied intelligence benchmarks, even under noisy rewards, our method consistently outperforms the baseline in both homogeneous and heterogeneous settings. These results indicate stronger robustness to reward noise and more stable training dynamics, effectively preventing optimization failures caused by noisy reward signals.
Stochastic Approximation Methods for Distortion Risk Measure Optimization
Oct 06, 2025Distortion Risk Measures (DRMs) capture risk preferences in decision-making and serve as general criteria for managing uncertainty. This paper proposes gradient descent algorithms for DRM optimization based on two dual representations: the Distortion-Measure (DM) form and Quantile-Function (QF) form. The DM-form employs a three-timescale algorithm to track quantiles, compute their gradients, and update decision variables, utilizing the Generalized Likelihood Ratio and kernel-based density estimation. The QF-form provides a simpler two-timescale approach that avoids the need for complex quantile gradient estimation. A hybrid form integrates both approaches, applying the DM-form for robust performance around distortion function jumps and the QF-form for efficiency in smooth regions. Proofs of strong convergence and convergence rates for the proposed algorithms are provided. In particular, the DM-form achieves an optimal rate of $O(k^{-4/7})$, while the QF-form attains a faster rate of $O(k^{-2/3})$. Numerical experiments confirm their effectiveness and demonstrate substantial improvements over baselines in robust portfolio selection tasks. The method's scalability is further illustrated through integration into deep reinforcement learning. Specifically, a DRM-based Proximal Policy Optimization algorithm is developed and applied to multi-echelon dynamic inventory management, showcasing its practical applicability.
Closing the Loop: Coordinating Inventory and Recommendation via Deep Reinforcement Learning on Multiple Timescales
Oct 05, 2025Effective cross-functional coordination is essential for enhancing firm-wide profitability, particularly in the face of growing organizational complexity and scale. Recent advances in artificial intelligence, especially in reinforcement learning (RL), offer promising avenues to address this fundamental challenge. This paper proposes a unified multi-agent RL framework tailored for joint optimization across distinct functional modules, exemplified via coordinating inventory replenishment and personalized product recommendation. We first develop an integrated theoretical model to capture the intricate interplay between these functions and derive analytical benchmarks that characterize optimal coordination. The analysis reveals synchronized adjustment patterns across products and over time, highlighting the importance of coordinated decision-making. Leveraging these insights, we design a novel multi-timescale multi-agent RL architecture that decomposes policy components according to departmental functions and assigns distinct learning speeds based on task complexity and responsiveness. Our model-free multi-agent design improves scalability and deployment flexibility, while multi-timescale updates enhance convergence stability and adaptability across heterogeneous decisions. We further establish the asymptotic convergence of the proposed algorithm. Extensive simulation experiments demonstrate that the proposed approach significantly improves profitability relative to siloed decision-making frameworks, while the behaviors of the trained RL agents align closely with the managerial insights from our theoretical model. Taken together, this work provides a scalable, interpretable RL-based solution to enable effective cross-functional coordination in complex business settings.
Forward Learning with Differential Privacy
Apr 01, 2025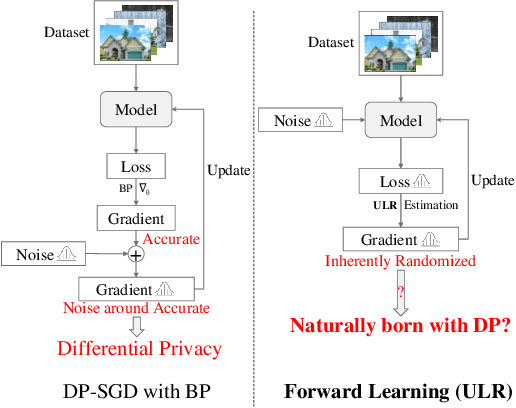
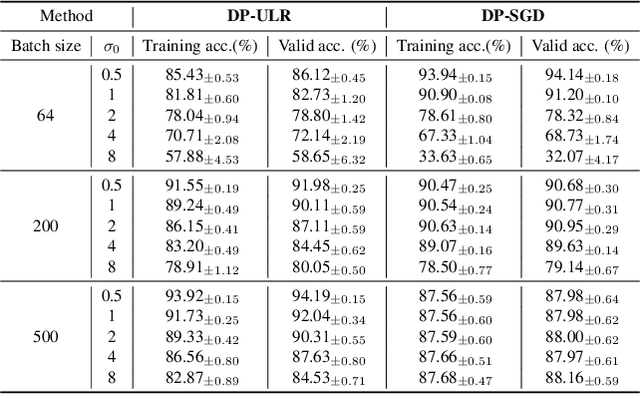
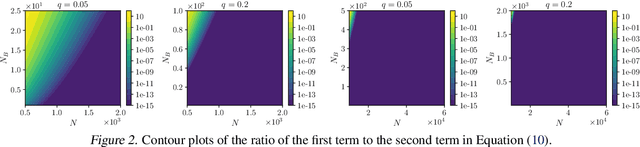
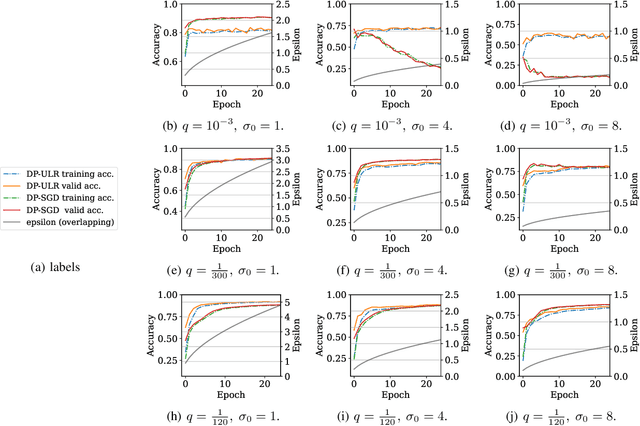
Differential privacy (DP) in deep learning is a critical concern as it ensures the confidentiality of training data while maintaining model utility. Existing DP training algorithms provide privacy guarantees by clipping and then injecting external noise into sample gradients computed by the backpropagation algorithm. Different from backpropagation, forward-learning algorithms based on perturbation inherently add noise during the forward pass and utilize randomness to estimate the gradients. Although these algorithms are non-privatized, the introduction of noise during the forward pass indirectly provides internal randomness protection to the model parameters and their gradients, suggesting the potential for naturally providing differential privacy. In this paper, we propose a \blue{privatized} forward-learning algorithm, Differential Private Unified Likelihood Ratio (DP-ULR), and demonstrate its differential privacy guarantees. DP-ULR features a novel batch sampling operation with rejection, of which we provide theoretical analysis in conjunction with classic differential privacy mechanisms. DP-ULR is also underpinned by a theoretically guided privacy controller that dynamically adjusts noise levels to manage privacy costs in each training step. Our experiments indicate that DP-ULR achieves competitive performance compared to traditional differential privacy training algorithms based on backpropagation, maintaining nearly the same privacy loss limits.
CoNNect: A Swiss-Army-Knife Regularizer for Pruning of Neural Networks
Feb 02, 2025
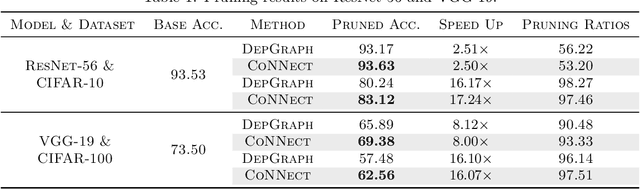
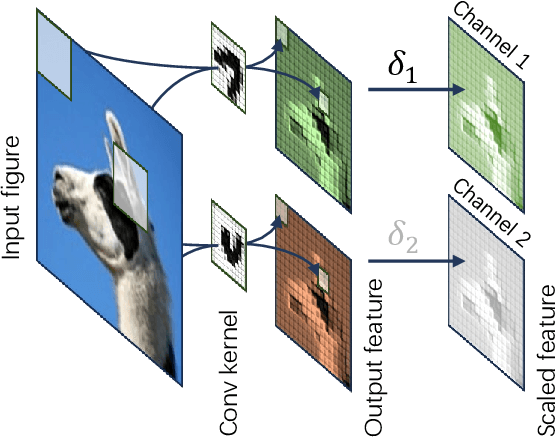
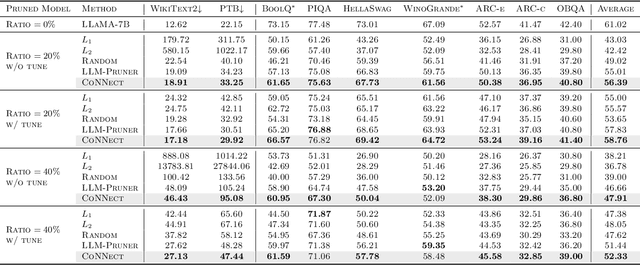
Pruning encompasses a range of techniques aimed at increasing the sparsity of neural networks (NNs). These techniques can generally be framed as minimizing a loss function subject to an $L_0$-norm constraint. This paper introduces CoNNect, a novel differentiable regularizer for sparse NN training that ensures connectivity between input and output layers. CoNNect integrates with established pruning strategies and supports both structured and unstructured pruning. We proof that CoNNect approximates $L_0$-regularization, guaranteeing maximally connected network structures while avoiding issues like layer collapse. Numerical experiments demonstrate that CoNNect improves classical pruning strategies and enhances state-of-the-art one-shot pruners, such as DepGraph and LLM-pruner.
Integrated Offline and Online Learning to Solve a Large Class of Scheduling Problems
Jan 08, 2025In this paper, we develop a unified machine learning (ML) approach to predict high-quality solutions for single-machine scheduling problems with a non-decreasing min-sum objective function with or without release times. Our ML approach is novel in three major aspects. First, our approach is developed for the entire class of the aforementioned problems. To achieve this, we exploit the fact that the entire class of the problems considered can be formulated as a time-indexed formulation in a unified manner. We develop a deep neural network (DNN) which uses the cost parameters in the time-indexed formulation as the inputs to effectively predict a continuous solution to this formulation, based on which a feasible discrete solution is easily constructed. The second novel aspect of our approach lies in how the DNN model is trained. In view of the NP-hard nature of the problems, labels (i.e., optimal solutions) are hard to generate for training. To overcome this difficulty, we generate and utilize a set of special instances, for which optimal solutions can be found with little computational effort, to train the ML model offline. The third novel idea we employ in our approach is that we develop an online single-instance learning approach to fine tune the parameters in the DNN for a given online instance, with the goal of generating an improved solution for the given instance. To this end, we develop a feasibility surrogate that approximates the objective value of a given instance as a continuous function of the outputs of the DNN, which then enables us to derive gradients and update the learnable parameters in the DNN. Numerical results show that our approach can efficiently generate high-quality solutions for a variety of single-machine scheduling min-sum problems with up to 1000 jobs.
A Parameter-Efficient Quantum Anomaly Detection Method on a Superconducting Quantum Processor
Dec 22, 2024



Quantum machine learning has gained attention for its potential to address computational challenges. However, whether those algorithms can effectively solve practical problems and outperform their classical counterparts, especially on current quantum hardware, remains a critical question. In this work, we propose a novel quantum machine learning method, called Quantum Support Vector Data Description (QSVDD), for practical anomaly detection, which aims to achieve both parameter efficiency and superior accuracy compared to classical models. Emulation results indicate that QSVDD demonstrates favourable recognition capabilities compared to classical baselines, achieving an average accuracy of over 90% on benchmarks with significantly fewer trainable parameters. Theoretical analysis confirms that QSVDD has a comparable expressivity to classical counterparts while requiring only a fraction of the parameters. Furthermore, we demonstrate the first implementation of a quantum machine learning method for anomaly detection on a superconducting quantum processor. Specifically, we achieve an accuracy of over 80% with only 16 parameters on the device, providing initial evidence of QSVDD's practical viability in the noisy intermediate-scale quantum era and highlighting its significant reduction in parameter requirements.
FLOPS: Forward Learning with OPtimal Sampling
Oct 08, 2024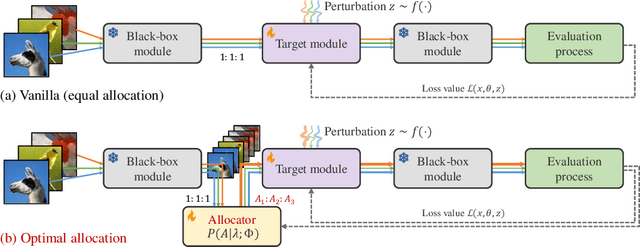
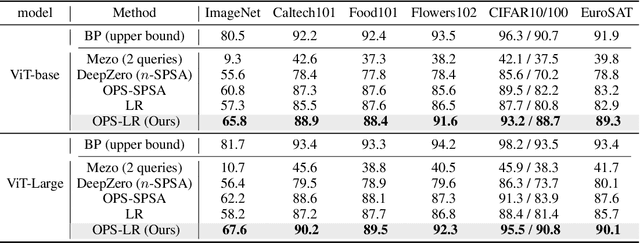
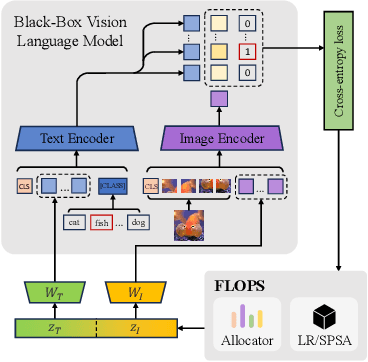
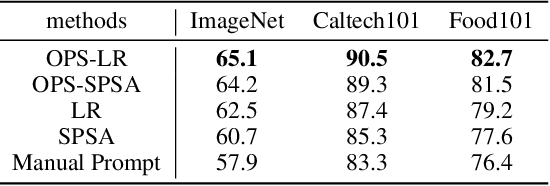
Given the limitations of backpropagation, perturbation-based gradient computation methods have recently gained focus for learning with only forward passes, also referred to as queries. Conventional forward learning consumes enormous queries on each data point for accurate gradient estimation through Monte Carlo sampling, which hinders the scalability of those algorithms. However, not all data points deserve equal queries for gradient estimation. In this paper, we study the problem of improving the forward learning efficiency from a novel perspective: how to reduce the gradient estimation variance with minimum cost? For this, we propose to allocate the optimal number of queries over each data in one batch during training to achieve a good balance between estimation accuracy and computational efficiency. Specifically, with a simplified proxy objective and a reparameterization technique, we derive a novel plug-and-play query allocator with minimal parameters. Theoretical results are carried out to verify its optimality. We conduct extensive experiments for fine-tuning Vision Transformers on various datasets and further deploy the allocator to two black-box applications: prompt tuning and multimodal alignment for foundation models. All findings demonstrate that our proposed allocator significantly enhances the scalability of forward-learning algorithms, paving the way for real-world applications.
Forward Learning for Gradient-based Black-box Saliency Map Generation
Mar 22, 2024

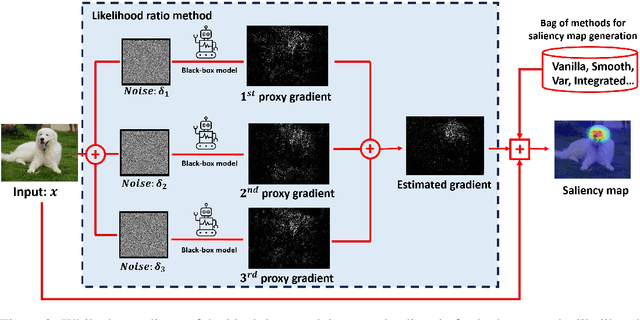

Gradient-based saliency maps are widely used to explain deep neural network decisions. However, as models become deeper and more black-box, such as in closed-source APIs like ChatGPT, computing gradients become challenging, hindering conventional explanation methods. In this work, we introduce a novel unified framework for estimating gradients in black-box settings and generating saliency maps to interpret model decisions. We employ the likelihood ratio method to estimate output-to-input gradients and utilize them for saliency map generation. Additionally, we propose blockwise computation techniques to enhance estimation accuracy. Extensive experiments in black-box settings validate the effectiveness of our method, demonstrating accurate gradient estimation and explainability of generated saliency maps. Furthermore, we showcase the scalability of our approach by applying it to explain GPT-Vision, revealing the continued relevance of gradient-based explanation methods in the era of large, closed-source, and black-box models.
Approximated Likelihood Ratio: A Forward-Only and Parallel Framework for Boosting Neural Network Training
Mar 18, 2024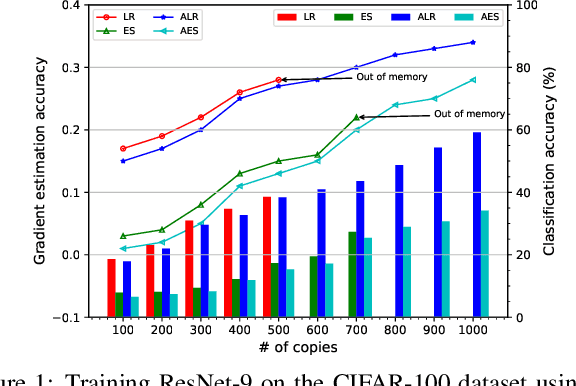

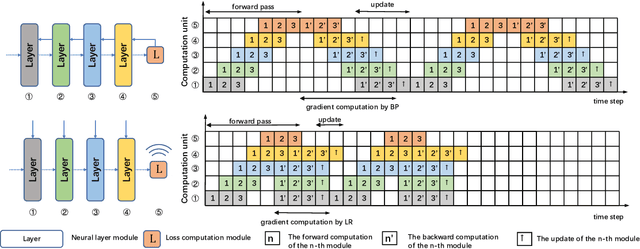

Efficient and biologically plausible alternatives to backpropagation in neural network training remain a challenge due to issues such as high computational complexity and additional assumptions about neural networks, which limit scalability to deeper networks. The likelihood ratio method offers a promising gradient estimation strategy but is constrained by significant memory consumption, especially when deploying multiple copies of data to reduce estimation variance. In this paper, we introduce an approximation technique for the likelihood ratio (LR) method to alleviate computational and memory demands in gradient estimation. By exploiting the natural parallelism during the backward pass using LR, we further provide a high-performance training strategy, which pipelines both the forward and backward pass, to make it more suitable for the computation on specialized hardware. Extensive experiments demonstrate the effectiveness of the approximation technique in neural network training. This work underscores the potential of the likelihood ratio method in achieving high-performance neural network training, suggesting avenues for further exploration.