 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximated Likelihood Ratio: A Forward-Only and Parallel Framework for Boosting Neural Network Training
Paper and Code
Mar 18, 2024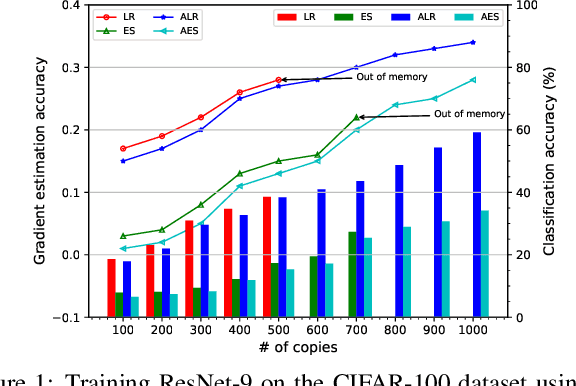

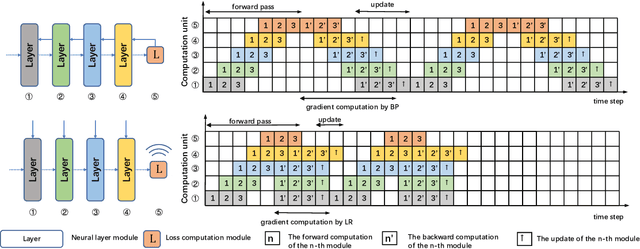

Efficient and biologically plausible alternatives to backpropagation in neural network training remain a challenge due to issues such as high computational complexity and additional assumptions about neural networks, which limit scalability to deeper networks. The likelihood ratio method offers a promising gradient estimation strategy but is constrained by significant memory consumption, especially when deploying multiple copies of data to reduce estimation variance. In this paper, we introduce an approximation technique for the likelihood ratio (LR) method to alleviate computational and memory demands in gradient estimation. By exploiting the natural parallelism during the backward pass using LR, we further provide a high-performance training strategy, which pipelines both the forward and backward pass, to make it more suitable for the computation on specialized hardware. Extensive experiments demonstrate the effectiveness of the approximation technique in neural network training. This work underscores the potential of the likelihood ratio method in achieving high-performance neural network training, suggesting avenues for further exploration.