 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Approximation Methods for Distortion Risk Measure Optimization
Oct 06, 2025Distortion Risk Measures (DRMs) capture risk preferences in decision-making and serve as general criteria for managing uncertainty. This paper proposes gradient descent algorithms for DRM optimization based on two dual representations: the Distortion-Measure (DM) form and Quantile-Function (QF) form. The DM-form employs a three-timescale algorithm to track quantiles, compute their gradients, and update decision variables, utilizing the Generalized Likelihood Ratio and kernel-based density estimation. The QF-form provides a simpler two-timescale approach that avoids the need for complex quantile gradient estimation. A hybrid form integrates both approaches, applying the DM-form for robust performance around distortion function jumps and the QF-form for efficiency in smooth regions. Proofs of strong convergence and convergence rates for the proposed algorithms are provided. In particular, the DM-form achieves an optimal rate of $O(k^{-4/7})$, while the QF-form attains a faster rate of $O(k^{-2/3})$. Numerical experiments confirm their effectiveness and demonstrate substantial improvements over baselines in robust portfolio selection tasks. The method's scalability is further illustrated through integration into deep reinforcement learning. Specifically, a DRM-based Proximal Policy Optimization algorithm is developed and applied to multi-echelon dynamic inventory management, showcasing its practical applicability.
Quantile-Based Deep Reinforcement Learning using Two-Timescale Policy Gradient Algorithms
May 12, 2023



Classical reinforcement learning (RL) aims to optimize the expected cumulative reward. In this work, we consider the RL setting where the goal is to optimize the quantile of the cumulative reward. We parameterize the policy controlling actions by neural networks, and propose a novel policy gradient algorithm called Quantile-Based Policy Optimization (QPO) and its variant Quantile-Based Proximal Policy Optimization (QPPO) for solving deep RL problems with quantile objectives. QPO uses two coupled iterations running at different timescales for simultaneously updating quantiles and policy parameters, whereas QPPO is an off-policy version of QPO that allows multiple updates of parameters during one simulation episode, leading to improved algorithm efficiency. Our numerical results indicate that the proposed algorithms outperform the existing baseline algorithms under the quantile criterion.
Quantile-Based Policy Optimization for Reinforcement Learning
Feb 16, 2022
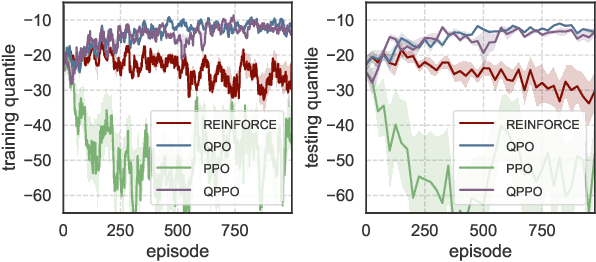
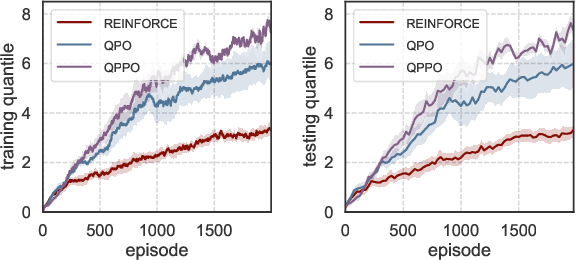
Classical reinforcement learning (RL) aims to optimize the expected cumulative rewards. In this work, we consider the RL setting where the goal is to optimize the quantile of the cumulative rewards. We parameterize the policy controlling actions by neural networks and propose a novel policy gradient algorithm called Quantile-Based Policy Optimization (QPO) and its variant Quantile-Based Proximal Policy Optimization (QPPO) to solve deep RL problems with quantile objectives. QPO uses two coupled iterations running at different time scales for simultaneously estimating quantiles and policy parameters and is shown to converge to the global optimal policy under certain conditions. Our numerical results demonstrate that the proposed algorithms outperform the existing baseline algorithms under the quantile criterion.