 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowAD: Ego-Scene Interactive Modeling for Autonomous Driving
Mar 11, 2026Effective environment modeling is the foundation for autonomous driving, underpinning tasks from perception to planning. However, current paradigms often inadequately consider the feedback of ego motion to the observation, which leads to an incomplete understanding of the driving process and consequently limits the planning capability. To address this issue, we introduce a novel ego-scene interactive modeling paradigm. Inspired by human recognition, the paradigm represents ego-scene interaction as the scene flow relative to the ego-vehicle. This conceptualization allows for modeling ego-motion feedback within a feature learning pattern, advantageously utilizing existing log-replay datasets rather than relying on scenario simulations. We specifically propose FlowAD, a general flow-based framework for autonomous driving. Within it, an ego-guided scene partition first constructs basic flow units to quantify scene flow. The ego-vehicle's forward direction and steering velocity directly shape the partition, which reflects ego motion. Then, based on flow units, spatial and temporal flow predictions are performed to model dynamics of scene flow, encompassing both spatial displacement and temporal variation. The final task-aware enhancement exploits learned spatio-temporal flow dynamics to benefit diverse tasks through object and region-level strategies. We also propose a novel Frames before Correct Planning (FCP) metric to assess the scene understanding capability. Experiments in both open and closed-loop evaluations demonstrate FlowAD's generality and effectiveness across perception, end-to-end planning, and VLM analysis. Notably, FlowAD reduces 19% collision rate over SparseDrive with FCP improvements of 1.39 frames (60%) on nuScenes, and achieves an impressive driving score of 51.77 on Bench2Drive, proving the superiority. Code, model, and configurations will be released here.
DriVerse: Navigation World Model for Driving Simulation via Multimodal Trajectory Prompting and Motion Alignment
Apr 22, 2025



This paper presents DriVerse, a generative model for simulating navigation-driven driving scenes from a single image and a future trajectory. Previous autonomous driving world models either directly feed the trajectory or discrete control signals into the generation pipeline, leading to poor alignment between the control inputs and the implicit features of the 2D base generative model, which results in low-fidelity video outputs. Some methods use coarse textual commands or discrete vehicle control signals, which lack the precision to guide fine-grained, trajectory-specific video generation, making them unsuitable for evaluating actual autonomous driving algorithms. DriVerse introduces explicit trajectory guidance in two complementary forms: it tokenizes trajectories into textual prompts using a predefined trend vocabulary for seamless language integration, and converts 3D trajectories into 2D spatial motion priors to enhance control over static content within the driving scene. To better handle dynamic objects, we further introduce a lightweight motion alignment module, which focuses on the inter-frame consistency of dynamic pixels, significantly enhancing the temporal coherence of moving elements over long sequences. With minimal training and no need for additional data, DriVerse outperforms specialized models on future video generation tasks across both the nuScenes and Waymo datasets. The code and models will be released to the public.
3Deformer: A Common Framework for Image-Guided Mesh Deformation
Jul 19, 2023We propose 3Deformer, a general-purpose framework for interactive 3D shape editing. Given a source 3D mesh with semantic materials, and a user-specified semantic image, 3Deformer can accurately edit the source mesh following the shape guidance of the semantic image, while preserving the source topology as rigid as possible. Recent studies of 3D shape editing mostly focus on learning neural networks to predict 3D shapes, which requires high-cost 3D training datasets and is limited to handling objects involved in the datasets. Unlike these studies, our 3Deformer is a non-training and common framework, which only requires supervision of readily-available semantic images, and is compatible with editing various objects unlimited by datasets. In 3Deformer, the source mesh is deformed utilizing the differentiable renderer technique, according to the correspondences between semantic images and mesh materials. However, guiding complex 3D shapes with a simple 2D image incurs extra challenges, that is, the deform accuracy, surface smoothness, geometric rigidity, and global synchronization of the edited mesh should be guaranteed. To address these challenges, we propose a hierarchical optimization architecture to balance the global and local shape features, and propose further various strategies and losses to improve properties of accuracy, smoothness, rigidity, and so on. Extensive experiments show that our 3Deformer is able to produce impressive results and reaches the state-of-the-art level.
CAPE: Camera View Position Embedding for Multi-View 3D Object Detection
Mar 17, 2023In this paper, we address the problem of detecting 3D objects from multi-view images. Current query-based methods rely on global 3D position embeddings (PE) to learn the geometric correspondence between images and 3D space. We claim that directly interacting 2D image features with global 3D PE could increase the difficulty of learning view transformation due to the variation of camera extrinsics. Thus we propose a novel method based on CAmera view Position Embedding, called CAPE. We form the 3D position embeddings under the local camera-view coordinate system instead of the global coordinate system, such that 3D position embedding is free of encoding camera extrinsic parameters. Furthermore, we extend our CAPE to temporal modeling by exploiting the object queries of previous frames and encoding the ego-motion for boosting 3D object detection. CAPE achieves state-of-the-art performance (61.0% NDS and 52.5% mAP) among all LiDAR-free methods on nuScenes dataset. Codes and models are available on \href{https://github.com/PaddlePaddle/Paddle3D}{Paddle3D} and \href{https://github.com/kaixinbear/CAPE}{PyTorch Implementation}.
Vectorization of Raster Manga by Deep Reinforcement Learning
Oct 10, 2021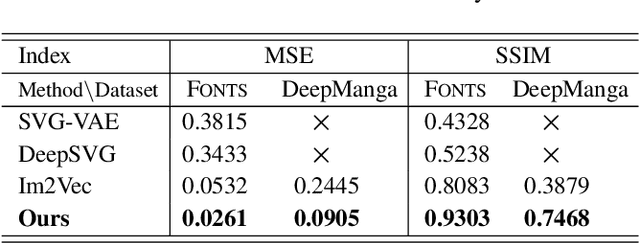
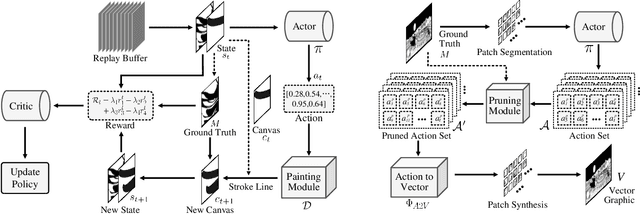
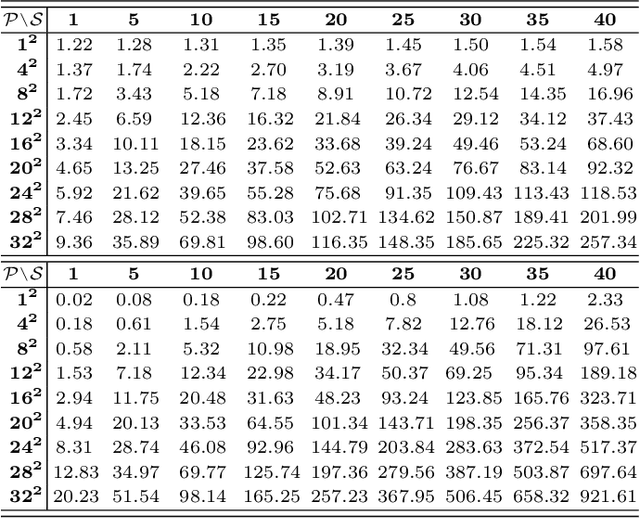
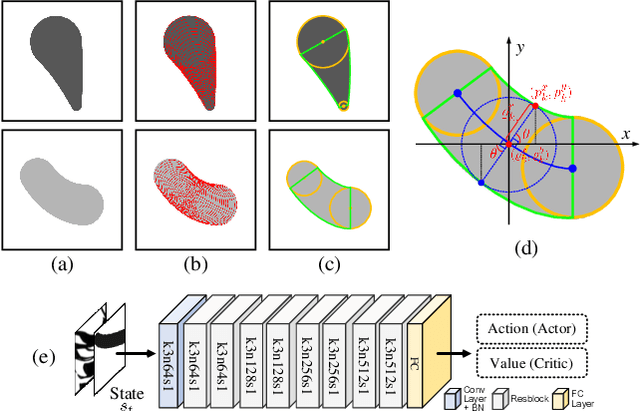
Manga is a popular Japanese-style comic form that consists of black-and-white stroke lines. Compared with images of real-world scenarios, the simpler textures and fewer color gradients of mangas are the extra natures that can be vectorized. In this paper, we propose Mang2Vec, the first approach for vectorizing raster mangas using Deep Reinforcement Learning (DRL). Unlike existing learning-based works of image vectorization, we present a new view that considers an entire manga as a collection of basic primitives "stroke line", and the sequence of strokes lines can be deep decomposed for further vectorization. We train a designed DRL agent to produce the most suitable sequence of stroke lines, which is constrained to follow the visual feature of the target manga. Next, the control parameters of strokes are collected to translated to vector format. To improve our performances on visual quality and storage size, we further propose an SA reward to generate accurate stokes, and a pruning mechanism to avoid producing error and redundant strokes. Quantitative and qualitative experiments demonstrate that our Mang2Vec can produce impressive results and reaches the state-of-the-art level.
An End-to-end Method for Producing Scanning-robust Stylized QR Codes
Nov 16, 2020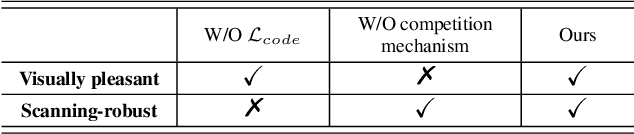

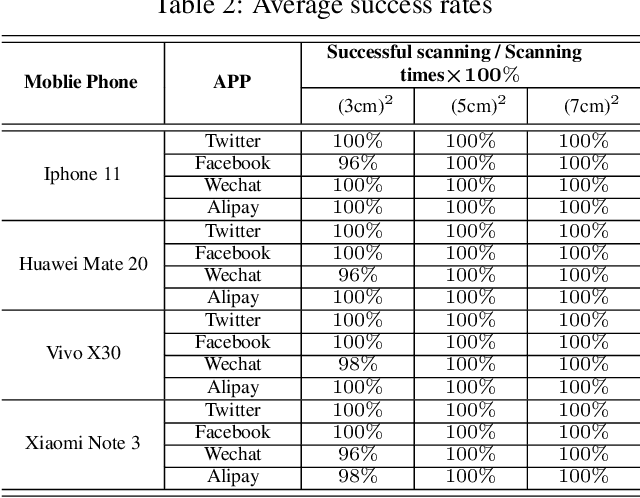
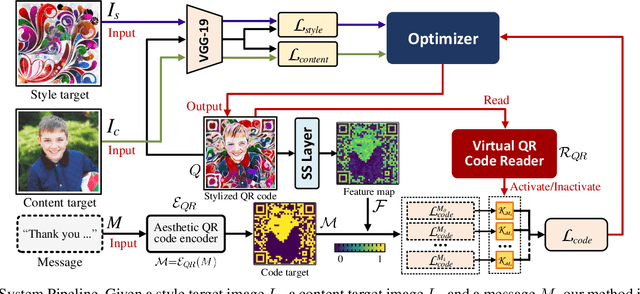
Quick Response (QR) code is one of the most worldwide used two-dimensional codes.~Traditional QR codes appear as random collections of black-and-white modules that lack visual semantics and aesthetic elements, which inspires the recent works to beautify the appearances of QR codes. However, these works adopt fixed generation algorithms and therefore can only generate QR codes with a pre-defined style. In this paper, combining the Neural Style Transfer technique, we propose a novel end-to-end method, named ArtCoder, to generate the stylized QR codes that are personalized, diverse, attractive, and scanning-robust.~To guarantee that the generated stylized QR codes are still scanning-robust, we propose a Sampling-Simulation layer, a module-based code loss, and a competition mechanism. The experimental results show that our stylized QR codes have high-quality in both the visual effect and the scanning-robustness, and they are able to support the real-world application.
Unpaired Photo-to-manga Translation Based on The Methodology of Manga Drawing
Apr 22, 2020
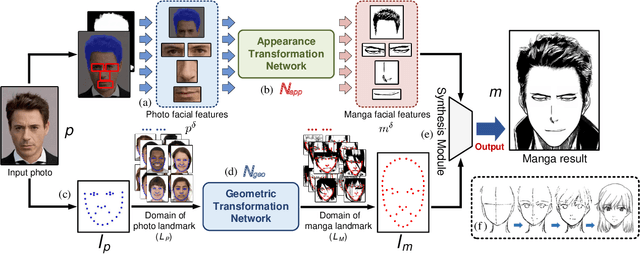
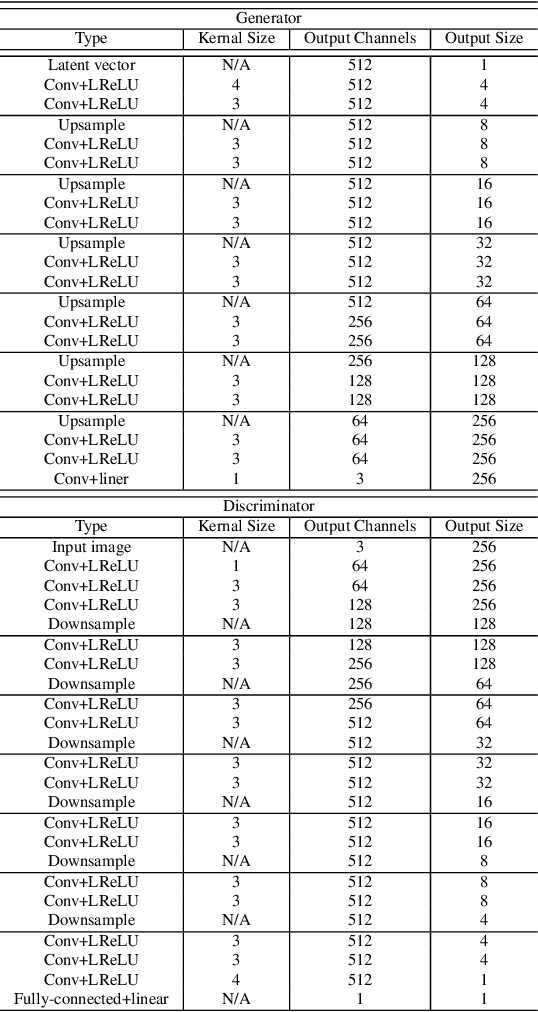
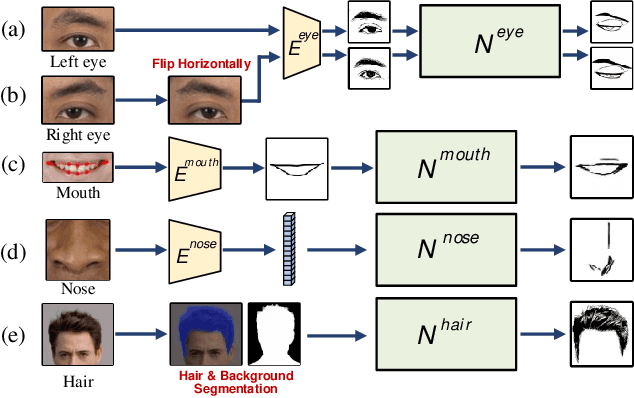
Manga is a world popular comic form originated in Japan, which typically employs black-and-white stroke lines and geometric exaggeration to describe humans' appearances, poses, and actions. In this paper, we propose MangaGAN, the first method based on Generative Adversarial Network (GAN) for unpaired photo-to-manga translation. Inspired by how experienced manga artists draw manga, MangaGAN generates the geometric features of manga face by a designed GAN model and delicately translates each facial region into the manga domain by a tailored multi-GANs architecture. For training MangaGAN, we construct a new dataset collected from a popular manga work, containing manga facial features, landmarks, bodies, and so on. Moreover, to produce high-quality manga faces, we further propose a structural smoothing loss to smooth stroke-lines and avoid noisy pixels, and a similarity preserving module to improve the similarity between domains of photo and manga. Extensive experiments show that MangaGAN can produce high-quality manga faces which preserve both the facial similarity and a popular manga style, and outperforms other related state-of-the-art methods.
Multi-View 3D Object Detection Network for Autonomous Driving
Jun 22, 2017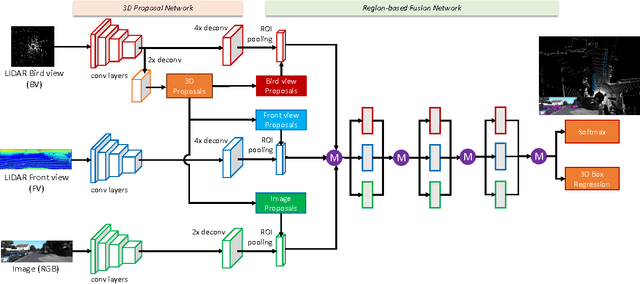
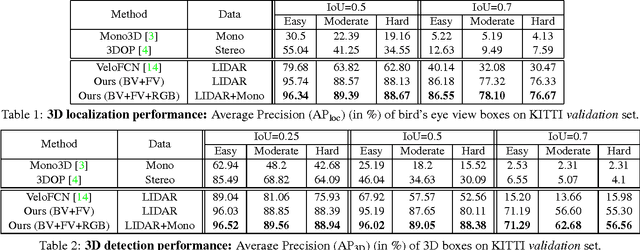

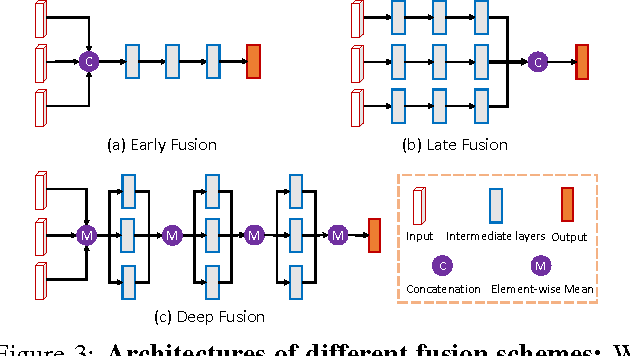
This paper aims at high-accuracy 3D object detection in autonomous driving scenario. We propose Multi-View 3D networks (MV3D), a sensory-fusion framework that takes both LIDAR point cloud and RGB images as input and predicts oriented 3D bounding boxes. We encode the sparse 3D point cloud with a compact multi-view representation. The network is composed of two subnetworks: one for 3D object proposal generation and another for multi-view feature fusion. The proposal network generates 3D candidate boxes efficiently from the bird's eye view representation of 3D point cloud. We design a deep fusion scheme to combine region-wise features from multiple views and enable interactions between intermediate layers of different paths. Experiments on the challenging KITTI benchmark show that our approach outperforms the state-of-the-art by around 25% and 30% AP on the tasks of 3D localization and 3D detection. In addition, for 2D detection, our approach obtains 10.3% higher AP than the state-of-the-art on the hard data among the LIDAR-based methods.