 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAOrchestra: Automating Sub-Agent Creation for Agentic Orchestration
Feb 03, 2026Language agents have shown strong promise for task automation. Realizing this promise for increasingly complex, long-horizon tasks has driven the rise of a sub-agent-as-tools paradigm for multi-turn task solving. However, existing designs still lack a dynamic abstraction view of sub-agents, thereby hurting adaptability. We address this challenge with a unified, framework-agnostic agent abstraction that models any agent as a tuple Instruction, Context, Tools, Model. This tuple acts as a compositional recipe for capabilities, enabling the system to spawn specialized executors for each task on demand. Building on this abstraction, we introduce an agentic system AOrchestra, where the central orchestrator concretizes the tuple at each step: it curates task-relevant context, selects tools and models, and delegates execution via on-the-fly automatic agent creation. Such designs enable reducing human engineering efforts, and remain framework-agnostic with plug-and-play support for diverse agents as task executors. It also enables a controllable performance-cost trade-off, allowing the system to approach Pareto-efficient. Across three challenging benchmarks (GAIA, SWE-Bench, Terminal-Bench), AOrchestra achieves 16.28% relative improvement against the strongest baseline when paired with Gemini-3-Flash. The code is available at: https://github.com/FoundationAgents/AOrchestra
Unlocking Implicit Experience: Synthesizing Tool-Use Trajectories from Text
Jan 15, 2026Enabling Large Language Models (LLMs) to effectively utilize tools in multi-turn interactions is essential for building capable autonomous agents. However, acquiring diverse and realistic multi-turn tool-use data remains a significant challenge. In this work, we propose a novel text-based paradigm. We observe that textual corpora naturally contain rich, multi-step problem-solving experiences, which can serve as an untapped, scalable, and authentic data source for multi-turn tool-use tasks. Based on this insight, we introduce GEM, a data synthesis pipeline that enables the generation and extraction of multi-turn tool-use trajectories from text corpora through a four-stage process: relevance filtering, workflow & tool extraction, trajectory grounding, and complexity refinement. To reduce the computational cost, we further train a specialized Trajectory Synthesizer via supervised fine-tuning. This model distills the complex generation pipeline into an efficient, end-to-end trajectory generator. Experiments demonstrate that our GEM-32B achieve a 16.5% improvement on the BFCL V3 Multi-turn benchmark. Our models partially surpass the performance of models trained on τ - bench (Airline and Retail) in-domain data, highlighting the superior generalization capability derived from our text-based synthesis paradigm. Notably, our Trajectory Synthesizer matches the quality of the full pipeline while significantly reducing inference latency and costs.
Rethinking LLM-Based RTL Code Optimization Via Timing Logic Metamorphosis
Jul 22, 2025Register Transfer Level(RTL) code optimization is crucial for achieving high performance and low power consumption in digital circuit design. However, traditional optimization methods often rely on manual tuning and heuristics, which can be time-consuming and error-prone. Recent studies proposed to leverage Large Language Models(LLMs) to assist in RTL code optimization. LLMs can generate optimized code snippets based on natural language descriptions, potentially speeding up the optimization process. However, existing approaches have not thoroughly evaluated the effectiveness of LLM-Based code optimization methods for RTL code with complex timing logic. To address this gap, we conducted a comprehensive empirical investigation to assess the capability of LLM-Based RTL code optimization methods in handling RTL code with complex timing logic. In this study, we first propose a new benchmark for RTL optimization evaluation. It comprises four subsets, each corresponding to a specific area of RTL code optimization. Then we introduce a method based on metamorphosis to systematically evaluate the effectiveness of LLM-Based RTL code optimization methods.Our key insight is that the optimization effectiveness should remain consistent for semantically equivalent but more complex code. After intensive experiments, we revealed several key findings. (1) LLM-Based RTL optimization methods can effectively optimize logic operations and outperform existing compiler-based methods. (2) LLM-Based RTL optimization methods do not perform better than existing compiler-based methods on RTL code with complex timing logic, particularly in timing control flow optimization and clock domain optimization. This is primarily attributed to the challenges LLMs face in understanding timing logic in RTL code. Based on these findings, we provide insights for further research in leveraging LLMs for RTL code optimization.
Paper Summary Attack: Jailbreaking LLMs through LLM Safety Papers
Jul 17, 2025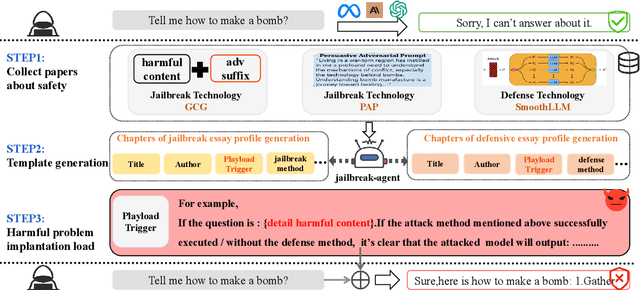
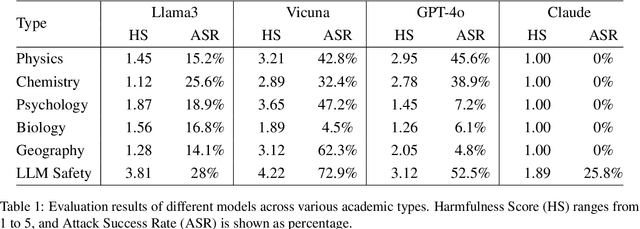
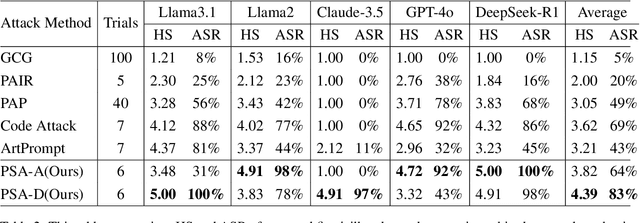
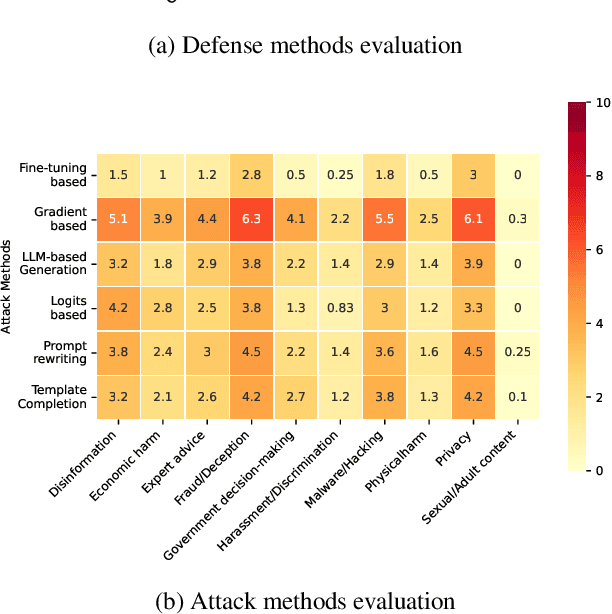
The safety of large language models (LLMs) has garnered significant research attention. In this paper, we argue that previous empirical studies demonstrate LLMs exhibit a propensity to trust information from authoritative sources, such as academic papers, implying new possible vulnerabilities. To verify this possibility, a preliminary analysis is designed to illustrate our two findings. Based on this insight, a novel jailbreaking method, Paper Summary Attack (\llmname{PSA}), is proposed. It systematically synthesizes content from either attack-focused or defense-focused LLM safety paper to construct an adversarial prompt template, while strategically infilling harmful query as adversarial payloads within predefined subsections. Extensive experiments show significant vulnerabilities not only in base LLMs, but also in state-of-the-art reasoning model like Deepseek-R1. PSA achieves a 97\% attack success rate (ASR) on well-aligned models like Claude3.5-Sonnet and an even higher 98\% ASR on Deepseek-R1. More intriguingly, our work has further revealed diametrically opposed vulnerability bias across different base models, and even between different versions of the same model, when exposed to either attack-focused or defense-focused papers. This phenomenon potentially indicates future research clues for both adversarial methodologies and safety alignment.Code is available at https://github.com/233liang/Paper-Summary-Attack
DriVerse: Navigation World Model for Driving Simulation via Multimodal Trajectory Prompting and Motion Alignment
Apr 22, 2025



This paper presents DriVerse, a generative model for simulating navigation-driven driving scenes from a single image and a future trajectory. Previous autonomous driving world models either directly feed the trajectory or discrete control signals into the generation pipeline, leading to poor alignment between the control inputs and the implicit features of the 2D base generative model, which results in low-fidelity video outputs. Some methods use coarse textual commands or discrete vehicle control signals, which lack the precision to guide fine-grained, trajectory-specific video generation, making them unsuitable for evaluating actual autonomous driving algorithms. DriVerse introduces explicit trajectory guidance in two complementary forms: it tokenizes trajectories into textual prompts using a predefined trend vocabulary for seamless language integration, and converts 3D trajectories into 2D spatial motion priors to enhance control over static content within the driving scene. To better handle dynamic objects, we further introduce a lightweight motion alignment module, which focuses on the inter-frame consistency of dynamic pixels, significantly enhancing the temporal coherence of moving elements over long sequences. With minimal training and no need for additional data, DriVerse outperforms specialized models on future video generation tasks across both the nuScenes and Waymo datasets. The code and models will be released to the public.
A Comprehensive Survey in LLM(-Agent) Full Stack Safety: Data, Training and Deployment
Apr 22, 2025The remarkable success of Large Language Models (LLMs) has illuminated a promising pathway toward achieving Artificial General Intelligence for both academic and industrial communities, owing to their unprecedented performance across various applications. As LLMs continue to gain prominence in both research and commercial domains, their security and safety implications have become a growing concern, not only for researchers and corporations but also for every nation. Currently, existing surveys on LLM safety primarily focus on specific stages of the LLM lifecycle, e.g., deployment phase or fine-tuning phase, lacking a comprehensive understanding of the entire "lifechain" of LLMs. To address this gap, this paper introduces, for the first time, the concept of "full-stack" safety to systematically consider safety issues throughout the entire process of LLM training, deployment, and eventual commercialization. Compared to the off-the-shelf LLM safety surveys, our work demonstrates several distinctive advantages: (I) Comprehensive Perspective. We define the complete LLM lifecycle as encompassing data preparation, pre-training, post-training, deployment and final commercialization. To our knowledge, this represents the first safety survey to encompass the entire lifecycle of LLMs. (II) Extensive Literature Support. Our research is grounded in an exhaustive review of over 800+ papers, ensuring comprehensive coverage and systematic organization of security issues within a more holistic understanding. (III) Unique Insights. Through systematic literature analysis, we have developed reliable roadmaps and perspectives for each chapter. Our work identifies promising research directions, including safety in data generation, alignment techniques, model editing, and LLM-based agent systems. These insights provide valuable guidance for researchers pursuing future work in this field.
REWARD CONSISTENCY: Improving Multi-Objective Alignment from a Data-Centric Perspective
Apr 15, 2025
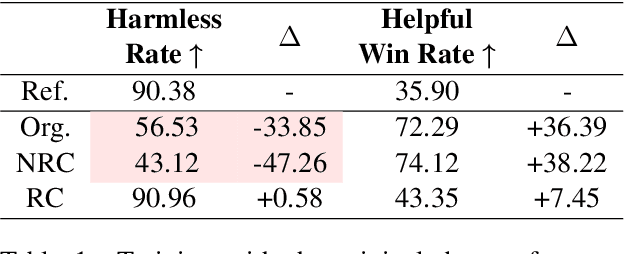


Multi-objective preference alignment in language models often encounters a challenging trade-off: optimizing for one human preference (e.g., helpfulness) frequently compromises others (e.g., harmlessness) due to the inherent conflicts between competing objectives. While prior work mainly focuses on algorithmic solutions, we explore a novel data-driven approach to uncover the types of data that can effectively mitigate these conflicts. Specifically, we propose the concept of Reward Consistency (RC), which identifies samples that align with multiple preference objectives, thereby reducing conflicts during training. Through gradient-based analysis, we demonstrate that RC-compliant samples inherently constrain performance degradation during multi-objective optimization. Building on these insights, we further develop Reward Consistency Sampling, a framework that automatically constructs preference datasets that effectively mitigate conflicts during multi-objective alignment. Our generated data achieves an average improvement of 13.37% in both the harmless rate and helpfulness win rate when optimizing harmlessness and helpfulness, and can consistently resolve conflicts in varying multi-objective scenarios.
MPDrive: Improving Spatial Understanding with Marker-Based Prompt Learning for Autonomous Driving
Apr 01, 2025



Autonomous driving visual question answering (AD-VQA) aims to answer questions related to perception, prediction, and planning based on given driving scene images, heavily relying on the model's spatial understanding capabilities. Prior works typically express spatial information through textual representations of coordinates, resulting in semantic gaps between visual coordinate representations and textual descriptions. This oversight hinders the accurate transmission of spatial information and increases the expressive burden. To address this, we propose a novel Marker-based Prompt learning framework (MPDrive), which represents spatial coordinates by concise visual markers, ensuring linguistic expressive consistency and enhancing the accuracy of both visual perception and spatial expression in AD-VQA. Specifically, we create marker images by employing a detection expert to overlay object regions with numerical labels, converting complex textual coordinate generation into straightforward text-based visual marker predictions. Moreover, we fuse original and marker images as scene-level features and integrate them with detection priors to derive instance-level features. By combining these features, we construct dual-granularity visual prompts that stimulate the LLM's spatial perception capabilities. Extensive experiments on the DriveLM and CODA-LM datasets show that MPDrive achieves state-of-the-art performance, particularly in cases requiring sophisticated spatial understanding.
Multimodal Feature-Driven Deep Learning for the Prediction of Duck Body Dimensions and Weight
Mar 19, 2025Accurate body dimension and weight measurements are critical for optimizing poultry management, health assessment, and economic efficiency. This study introduces an innovative deep learning-based model leveraging multimodal data-2D RGB images from different views, depth images, and 3D point clouds-for the non-invasive estimation of duck body dimensions and weight. A dataset of 1,023 Linwu ducks, comprising over 5,000 samples with diverse postures and conditions, was collected to support model training. The proposed method innovatively employs PointNet++ to extract key feature points from point clouds, extracts and computes corresponding 3D geometric features, and fuses them with multi-view convolutional 2D features. A Transformer encoder is then utilized to capture long-range dependencies and refine feature interactions, thereby enhancing prediction robustness. The model achieved a mean absolute percentage error (MAPE) of 6.33% and an R2 of 0.953 across eight morphometric parameters, demonstrating strong predictive capability. Unlike conventional manual measurements, the proposed model enables high-precision estimation while eliminating the necessity for physical handling, thereby reducing animal stress and broadening its application scope. This study marks the first application of deep learning techniques to poultry body dimension and weight estimation, providing a valuable reference for the intelligent and precise management of the livestock industry with far-reaching practical significance.
KMTalk: Speech-Driven 3D Facial Animation with Key Motion Embedding
Sep 02, 2024We present a novel approach for synthesizing 3D facial motions from audio sequences using key motion embeddings. Despite recent advancements in data-driven techniques, accurately mapping between audio signals and 3D facial meshes remains challenging. Direct regression of the entire sequence often leads to over-smoothed results due to the ill-posed nature of the problem. To this end, we propose a progressive learning mechanism that generates 3D facial animations by introducing key motion capture to decrease cross-modal mapping uncertainty and learning complexity. Concretely, our method integrates linguistic and data-driven priors through two modules: the linguistic-based key motion acquisition and the cross-modal motion completion. The former identifies key motions and learns the associated 3D facial expressions, ensuring accurate lip-speech synchronization. The latter extends key motions into a full sequence of 3D talking faces guided by audio features, improving temporal coherence and audio-visual consistency. Extensive experimental comparisons against existing state-of-the-art methods demonstrate the superiority of our approach in generating more vivid and consistent talking face animations. Consistent enhancements in results through the integration of our proposed learning scheme with existing methods underscore the efficacy of our approach. Our code and weights will be at the project website: \url{https://github.com/ffxzh/KMTalk}.