 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Hierarchical and Geometry-Aware Graph Representations for Text-to-CAD
Apr 11, 2026Text-to-CAD code generation is a long-horizon task that translates textual instructions into long sequences of interdependent operations. Existing methods typically decode text directly into executable code (e.g., bpy) without explicitly modeling assembly hierarchy or geometric constraints, which enlarges the search space, accumulates local errors, and often causes cascading failures in complex assemblies. To address this issue, we propose a hierarchical and geometry-aware graph as an intermediate representation. The graph models multi-level parts and components as nodes and encodes explicit geometric constraints as edges. Instead of mapping text directly to code, our framework first predicts structure and constraints, then conditions action sequencing and code generation, thereby improving geometric fidelity and constraint satisfaction. We further introduce a structure-aware progressive curriculum learning strategy that constructs graded tasks through controlled structural edits, explores the model's capability boundary, and synthesizes boundary examples for iterative training. In addition, we build a 12K dataset with instructions, decomposition graphs, action sequences, and bpy code, together with graph- and constraint-oriented evaluation metrics. Extensive experiments show that our method consistently outperforms existing approaches in both geometric fidelity and accurate satisfaction of geometric constraints.
MPDrive: Improving Spatial Understanding with Marker-Based Prompt Learning for Autonomous Driving
Apr 01, 2025



Autonomous driving visual question answering (AD-VQA) aims to answer questions related to perception, prediction, and planning based on given driving scene images, heavily relying on the model's spatial understanding capabilities. Prior works typically express spatial information through textual representations of coordinates, resulting in semantic gaps between visual coordinate representations and textual descriptions. This oversight hinders the accurate transmission of spatial information and increases the expressive burden. To address this, we propose a novel Marker-based Prompt learning framework (MPDrive), which represents spatial coordinates by concise visual markers, ensuring linguistic expressive consistency and enhancing the accuracy of both visual perception and spatial expression in AD-VQA. Specifically, we create marker images by employing a detection expert to overlay object regions with numerical labels, converting complex textual coordinate generation into straightforward text-based visual marker predictions. Moreover, we fuse original and marker images as scene-level features and integrate them with detection priors to derive instance-level features. By combining these features, we construct dual-granularity visual prompts that stimulate the LLM's spatial perception capabilities. Extensive experiments on the DriveLM and CODA-LM datasets show that MPDrive achieves state-of-the-art performance, particularly in cases requiring sophisticated spatial understanding.
Globally Correlation-Aware Hard Negative Generation
Nov 20, 2024Hard negative generation aims to generate informative negative samples that help to determine the decision boundaries and thus facilitate advancing deep metric learning. Current works select pair/triplet samples, learn their correlations, and fuse them to generate hard negatives. However, these works merely consider the local correlations of selected samples, ignoring global sample correlations that would provide more significant information to generate more informative negatives. In this work, we propose a Globally Correlation-Aware Hard Negative Generation (GCA-HNG) framework, which first learns sample correlations from a global perspective and exploits these correlations to guide generating hardness-adaptive and diverse negatives. Specifically, this approach begins by constructing a structured graph to model sample correlations, where each node represents a specific sample and each edge represents the correlations between corresponding samples. Then, we introduce an iterative graph message propagation to propagate the messages of node and edge through the whole graph and thus learn the sample correlations globally. Finally, with the guidance of the learned global correlations, we propose a channel-adaptive manner to combine an anchor and multiple negatives for HNG. Compared to current methods, GCA-HNG allows perceiving sample correlations with numerous negatives from a global and comprehensive perspective and generates the negatives with better hardness and diversity. Extensive experiment results demonstrate that the proposed GCA-HNG is superior to related methods on four image retrieval benchmark datasets. Codes and trained models are available at \url{https://github.com/PWenJay/GCA-HNG}.
Advancing CTC-CRF Based End-to-End Speech Recognition with Wordpieces and Conformers
Jul 08, 2021
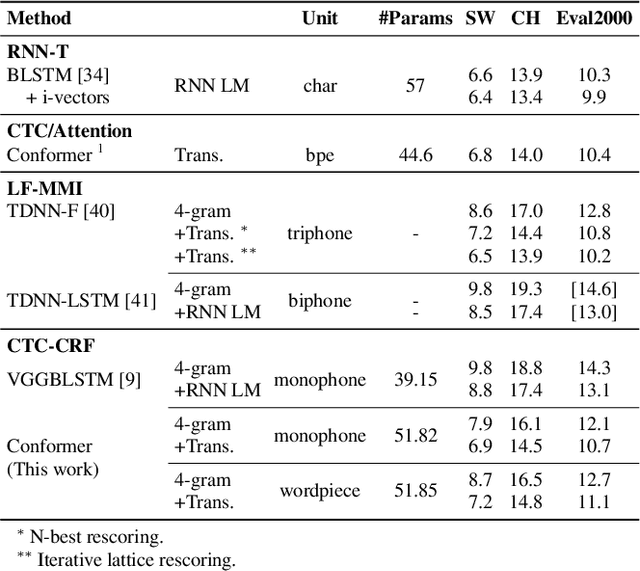

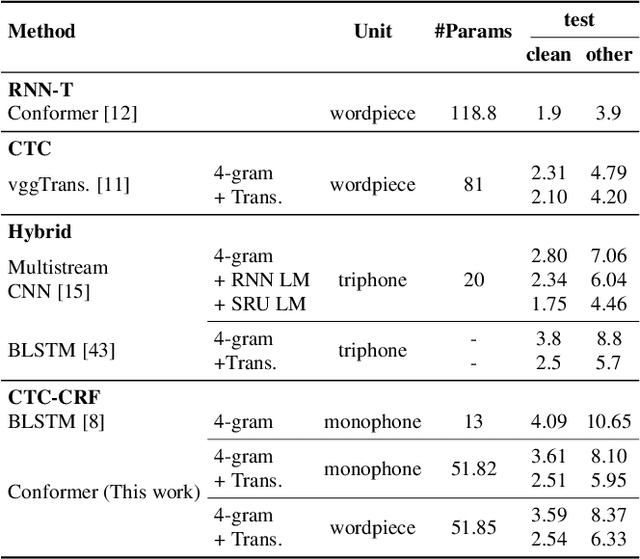
Automatic speech recognition systems have been largely improved in the past few decades and current systems are mainly hybrid-based and end-to-end-based. The recently proposed CTC-CRF framework inherits the data-efficiency of the hybrid approach and the simplicity of the end-to-end approach. In this paper, we further advance CTC-CRF based ASR technique with explorations on modeling units and neural architectures. Specifically, we investigate techniques to enable the recently developed wordpiece modeling units and Conformer neural networks to be succesfully applied in CTC-CRFs. Experiments are conducted on two English datasets (Switchboard, Librispeech) and a German dataset from CommonVoice. Experimental results suggest that (i) Conformer can improve the recognition performance significantly; (ii) Wordpiece-based systems perform slightly worse compared with phone-based systems for the target language with a low degree of grapheme-phoneme correspondence (e.g. English), while the two systems can perform equally strong when such degree of correspondence is high for the target language (e.g. German).