 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Language Model Integration for Transducer based Speech Recognition
Mar 31, 2022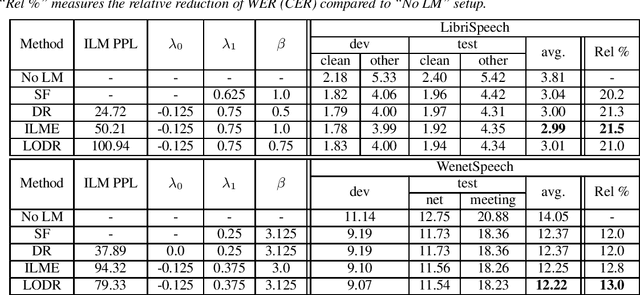
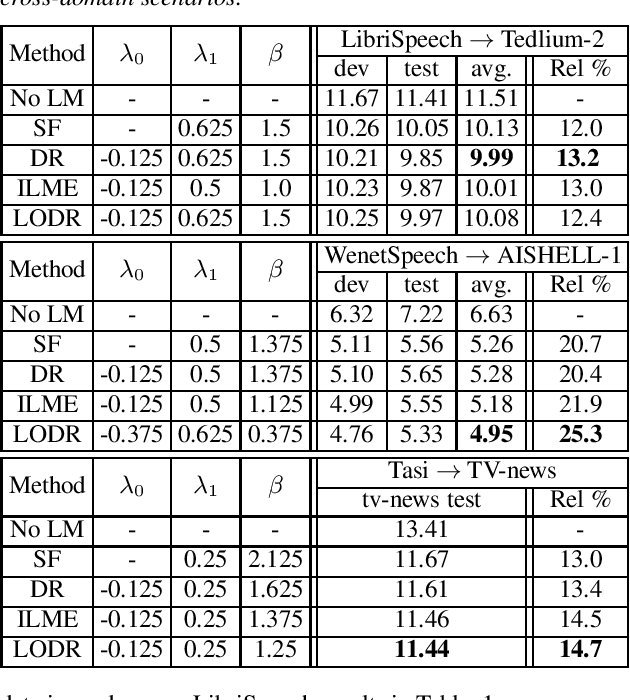
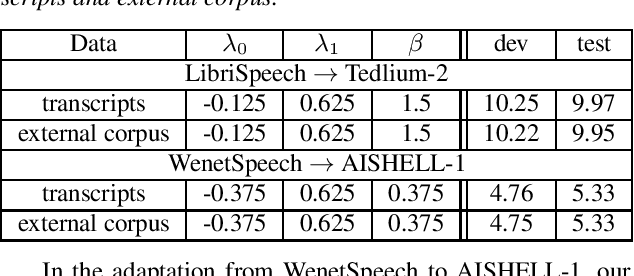
Utilizing text-only data with an external language model (LM) in end-to-end RNN-Transducer (RNN-T) for speech recognition is challenging. Recently, a class of methods such as density ratio (DR) and ILM estimation (ILME) have been developed, outperforming the classic shallow fusion (SF) method. The basic idea behind these methods is that RNN-T posterior should first subtract the implicitly learned ILM prior, in order to integrate the external LM. While recent studies suggest that RNN-T only learns some low-order language model information, the DR method uses a well-trained ILM. We hypothesize that this setting is appropriate and may deteriorate the performance of the DR method, and propose a low-order density ratio method (LODR) by training a low-order weak ILM for DR. Extensive empirical experiments are conducted on both in-domain and cross-domain scenarios on English LibriSpeech & Tedlium-2 and Chinese WenetSpeech & AISHELL-1 datasets. It is shown that LODR consistently outperforms SF in all tasks, while performing generally close to ILME and better than DR in most tests.
CUSIDE: Chunking, Simulating Future Context and Decoding for Streaming ASR
Mar 31, 2022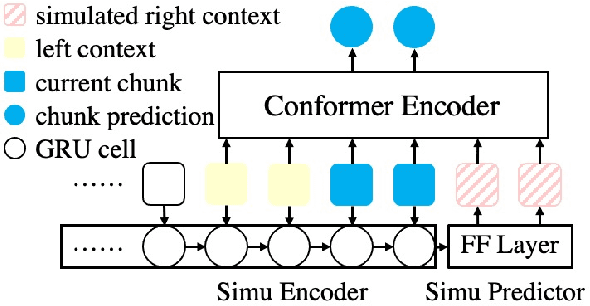
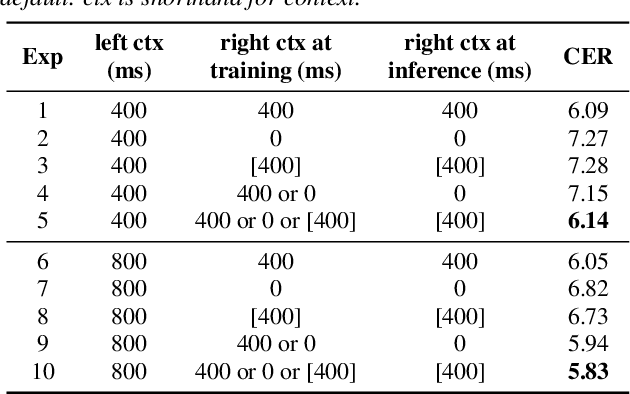

History and future contextual information are known to be important for accurate acoustic modeling. However, acquiring future context brings latency for streaming ASR. In this paper, we propose a new framework - Chunking, Simulating Future Context and Decoding (CUSIDE) for streaming speech recognition. A new simulation module is introduced to recursively simulate the future contextual frames, without waiting for future context. The simulation module is jointly trained with the ASR model using a self-supervised loss; the ASR model is optimized with the usual ASR loss, e.g., CTC-CRF as used in our experiments. Experiments show that, compared to using real future frames as right context, using simulated future context can drastically reduce latency while maintaining recognition accuracy. With CUSIDE, we obtain new state-of-the-art streaming ASR results on the AISHELL-1 dataset.
Multilingual and crosslingual speech recognition using phonological-vector based phone embeddings
Jul 11, 2021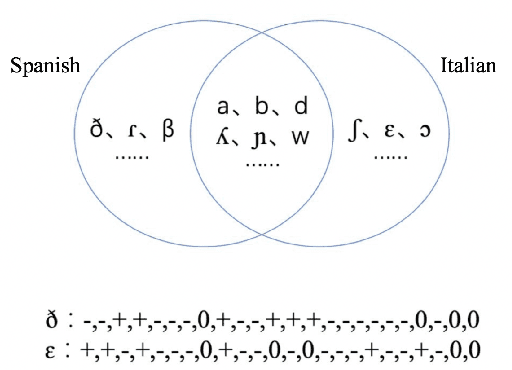
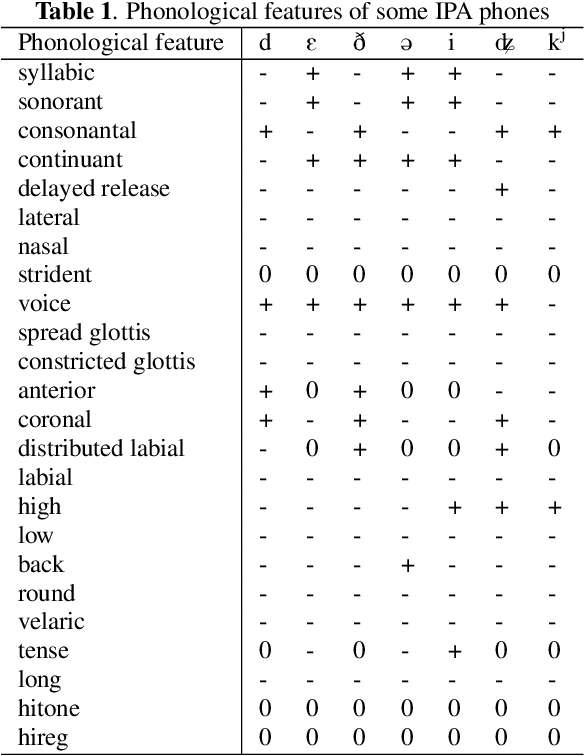
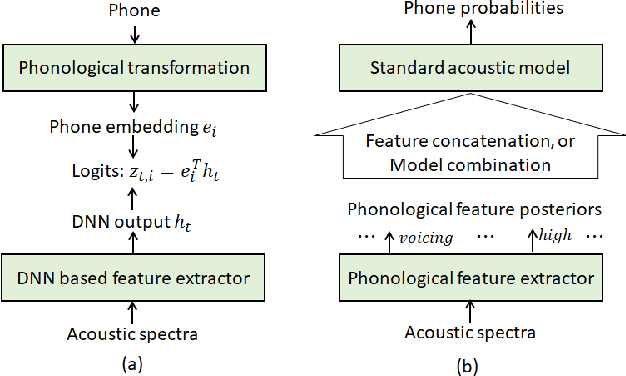
The use of phonological features (PFs) potentially allows language-specific phones to remain linked in training, which is highly desirable for information sharing for multilingual and crosslingual speech recognition methods for low-resourced languages. A drawback suffered by previous methods in using phonological features is that the acoustic-to-PF extraction in a bottom-up way is itself difficult. In this paper, we propose to join phonology driven phone embedding (top-down) and deep neural network (DNN) based acoustic feature extraction (bottom-up) to calculate phone probabilities. The new method is called JoinAP (Joining of Acoustics and Phonology). Remarkably, no inversion from acoustics to phonological features is required for speech recognition. For each phone in the IPA (International Phonetic Alphabet) table, we encode its phonological features to a phonological-vector, and then apply linear or nonlinear transformation of the phonological-vector to obtain the phone embedding. A series of multilingual and crosslingual (both zero-shot and few-shot) speech recognition experiments are conducted on the CommonVoice dataset (German, French, Spanish and Italian) and the AISHLL-1 dataset (Mandarin), and demonstrate the superiority of JoinAP with nonlinear phone embeddings over both JoinAP with linear phone embeddings and the traditional method with flat phone embeddings.
Advancing CTC-CRF Based End-to-End Speech Recognition with Wordpieces and Conformers
Jul 08, 2021
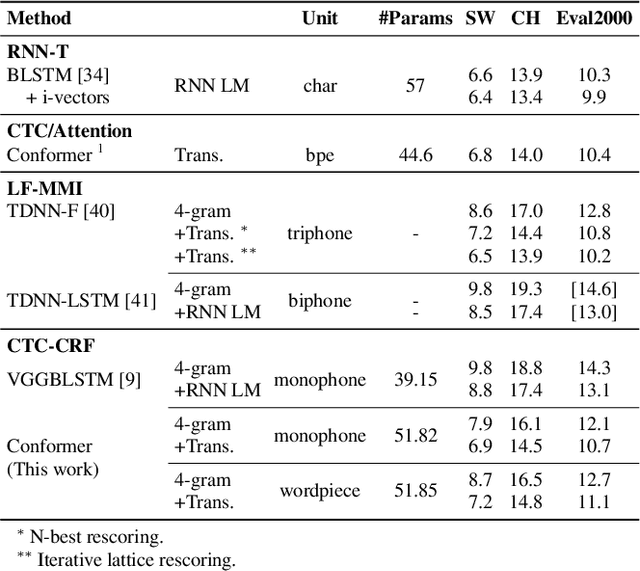

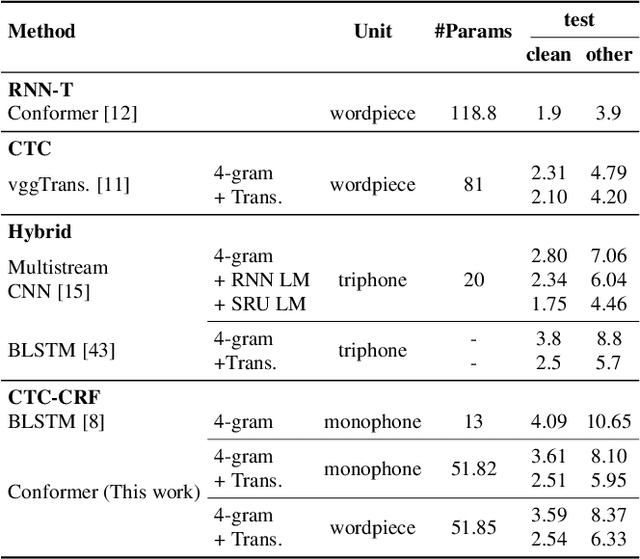
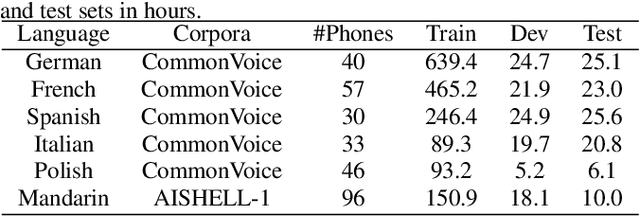
Automatic speech recognition systems have been largely improved in the past few decades and current systems are mainly hybrid-based and end-to-end-based. The recently proposed CTC-CRF framework inherits the data-efficiency of the hybrid approach and the simplicity of the end-to-end approach. In this paper, we further advance CTC-CRF based ASR technique with explorations on modeling units and neural architectures. Specifically, we investigate techniques to enable the recently developed wordpiece modeling units and Conformer neural networks to be succesfully applied in CTC-CRFs. Experiments are conducted on two English datasets (Switchboard, Librispeech) and a German dataset from CommonVoice. Experimental results suggest that (i) Conformer can improve the recognition performance significantly; (ii) Wordpiece-based systems perform slightly worse compared with phone-based systems for the target language with a low degree of grapheme-phoneme correspondence (e.g. English), while the two systems can perform equally strong when such degree of correspondence is high for the target language (e.g. German).
Efficient Neural Architecture Search for End-to-end Speech Recognition via Straight-Through Gradients
Nov 11, 2020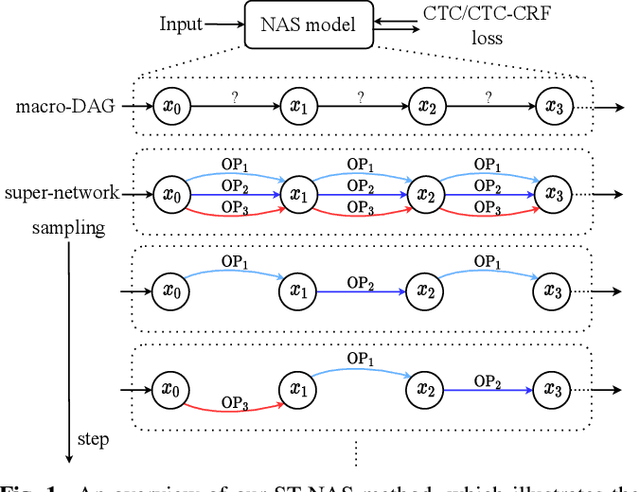
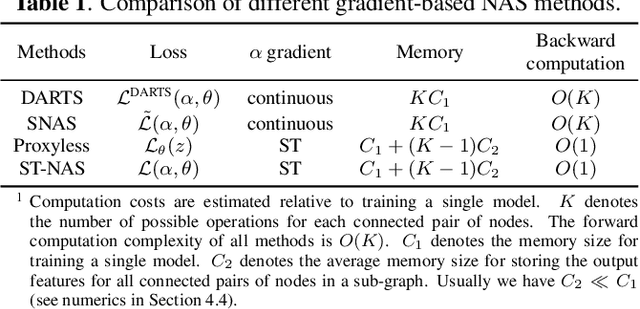
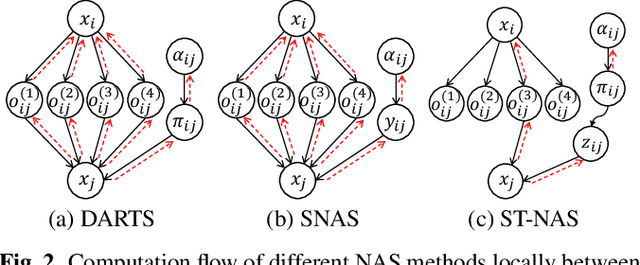
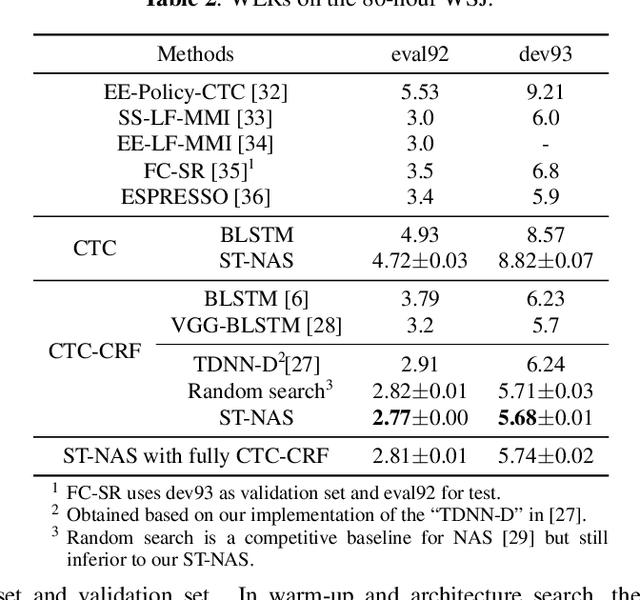
Neural Architecture Search (NAS), the process of automating architecture engineering, is an appealing next step to advancing end-to-end Automatic Speech Recognition (ASR), replacing expert-designed networks with learned, task-specific architectures. In contrast to early computational-demanding NAS methods, recent gradient-based NAS methods, e.g., DARTS (Differentiable ARchiTecture Search), SNAS (Stochastic NAS) and ProxylessNAS, significantly improve the NAS efficiency. In this paper, we make two contributions. First, we rigorously develop an efficient NAS method via Straight-Through (ST) gradients, called ST-NAS. Basically, ST-NAS uses the loss from SNAS but uses ST to back-propagate gradients through discrete variables to optimize the loss, which is not revealed in ProxylessNAS. Using ST gradients to support sub-graph sampling is a core element to achieve efficient NAS beyond DARTS and SNAS. Second, we successfully apply ST-NAS to end-to-end ASR. Experiments over the widely benchmarked 80-hour WSJ and 300-hour Switchboard datasets show that the ST-NAS induced architectures significantly outperform the human-designed architecture across the two datasets. Strengths of ST-NAS such as architecture transferability and low computation cost in memory and time are also reported.
An empirical study of domain-agnostic semi-supervised learning via energy-based models: joint-training and pre-training
Oct 25, 2020
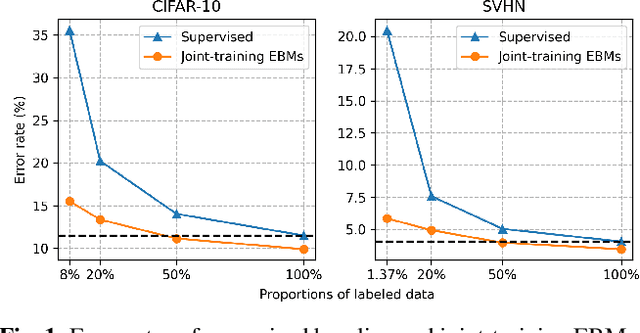

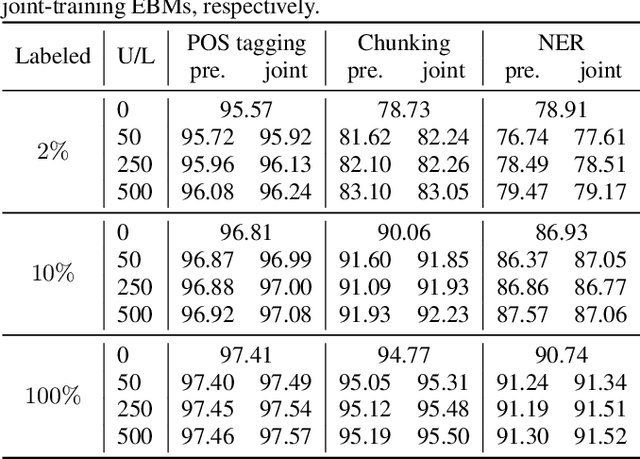
A class of recent semi-supervised learning (SSL) methods heavily rely on domain-specific data augmentations. In contrast, generative SSL methods involve unsupervised learning based on generative models by either joint-training or pre-training, and are more appealing from the perspective of being domain-agnostic, since they do not inherently require data augmentations. Joint-training estimates the joint distribution of observations and labels, while pre-training is taken over observations only. Recently, energy-based models (EBMs) have achieved promising results for generative modeling. Joint-training via EBMs for SSL has been explored with encouraging results across different data modalities. In this paper, we make two contributions. First, we explore pre-training via EBMs for SSL and compare it to joint-training. Second, a suite of experiments are conducted over domains of image classification and natural language labeling to give a realistic whole picture of the performances of EBM based SSL methods. It is found that joint-training EBMs outperform pre-training EBMs marginally but nearly consistently.