 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Language Model Integration for Transducer based Speech Recognition
Paper and Code
Mar 31, 2022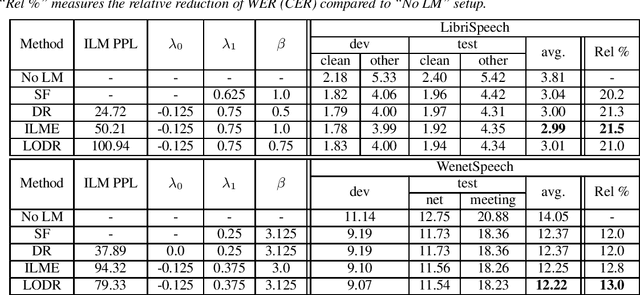
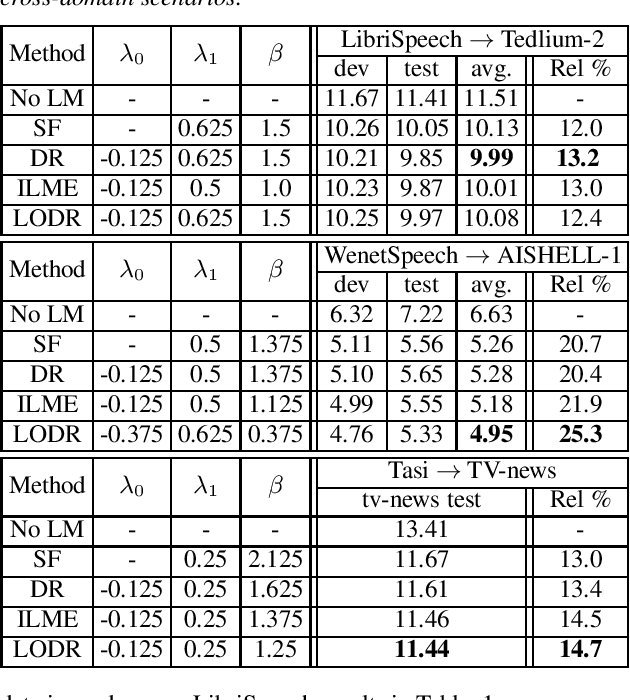
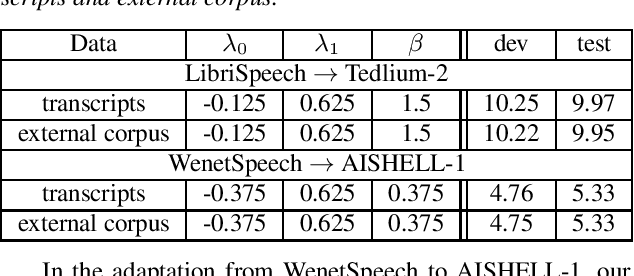
Utilizing text-only data with an external language model (LM) in end-to-end RNN-Transducer (RNN-T) for speech recognition is challenging. Recently, a class of methods such as density ratio (DR) and ILM estimation (ILME) have been developed, outperforming the classic shallow fusion (SF) method. The basic idea behind these methods is that RNN-T posterior should first subtract the implicitly learned ILM prior, in order to integrate the external LM. While recent studies suggest that RNN-T only learns some low-order language model information, the DR method uses a well-trained ILM. We hypothesize that this setting is appropriate and may deteriorate the performance of the DR method, and propose a low-order density ratio method (LODR) by training a low-order weak ILM for DR. Extensive empirical experiments are conducted on both in-domain and cross-domain scenarios on English LibriSpeech & Tedlium-2 and Chinese WenetSpeech & AISHELL-1 datasets. It is shown that LODR consistently outperforms SF in all tasks, while performing generally close to ILME and better than DR in most tests.