 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoAlign: Geometric Feature Realignment for MLLM Spatial Reasoning
Apr 14, 2026Multimodal large language models (MLLMs) have exhibited remarkable performance in various visual tasks, yet still struggle with spatial reasoning. Recent efforts mitigate this by injecting geometric features from 3D foundation models, but rely on static single-layer extractions. We identify that such an approach induces a task misalignment bias: the geometric features naturally evolve towards 3D pretraining objectives, which may contradict the heterogeneous spatial demands of MLLMs, rendering any single layer fundamentally insufficient. To resolve this, we propose GeoAlign, a novel framework that dynamically aggregates multi-layer geometric features to realign with the actual demands. GeoAlign constructs a hierarchical geometric feature bank and leverages the MLLM's original visual tokens as content-aware queries to perform layer-wise sparse routing, adaptively fetching the suitable geometric features for each patch. Extensive experiments on VSI-Bench, ScanQA, and SQA3D demonstrate that our compact 4B model effectively achieves state-of-the-art performance, even outperforming larger existing MLLMs.
LongCat-AudioDiT: High-Fidelity Diffusion Text-to-Speech in the Waveform Latent Space
Mar 31, 2026We present LongCat-AudioDiT, a novel, non-autoregressive diffusion-based text-to-speech (TTS) model that achieves state-of-the-art (SOTA) performance. Unlike previous methods that rely on intermediate acoustic representations such as mel-spectrograms, the core innovation of LongCat-AudioDiT lies in operating directly within the waveform latent space. This approach effectively mitigates compounding errors and drastically simplifies the TTS pipeline, requiring only a waveform variational autoencoder (Wav-VAE) and a diffusion backbone. Furthermore, we introduce two critical improvements to the inference process: first, we identify and rectify a long-standing training-inference mismatch; second, we replace traditional classifier-free guidance with adaptive projection guidance to elevate generation quality. Experimental results demonstrate that, despite the absence of complex multi-stage training pipelines or high-quality human-annotated datasets, LongCat-AudioDiT achieves SOTA zero-shot voice cloning performance on the Seed benchmark while maintaining competitive intelligibility. Specifically, our largest variant, LongCat-AudioDiT-3.5B, outperforms the previous SOTA model (Seed-TTS), improving the speaker similarity (SIM) scores from 0.809 to 0.818 on Seed-ZH, and from 0.776 to 0.797 on Seed-Hard. Finally, through comprehensive ablation studies and systematic analysis, we validate the effectiveness of our proposed modules. Notably, we investigate the interplay between the Wav-VAE and the TTS backbone, revealing the counterintuitive finding that superior reconstruction fidelity in the Wav-VAE does not necessarily lead to better overall TTS performance. Code and model weights are released to foster further research within the speech community.
Audio Turing Test: Benchmarking the Human-likeness of Large Language Model-based Text-to-Speech Systems in Chinese
May 16, 2025Recent advances in large language models (LLMs) have significantly improved text-to-speech (TTS) systems, enhancing control over speech style, naturalness, and emotional expression, which brings TTS Systems closer to human-level performance. Although the Mean Opinion Score (MOS) remains the standard for TTS System evaluation, it suffers from subjectivity, environmental inconsistencies, and limited interpretability. Existing evaluation datasets also lack a multi-dimensional design, often neglecting factors such as speaking styles, context diversity, and trap utterances, which is particularly evident in Chinese TTS evaluation. To address these challenges, we introduce the Audio Turing Test (ATT), a multi-dimensional Chinese corpus dataset ATT-Corpus paired with a simple, Turing-Test-inspired evaluation protocol. Instead of relying on complex MOS scales or direct model comparisons, ATT asks evaluators to judge whether a voice sounds human. This simplification reduces rating bias and improves evaluation robustness. To further support rapid model development, we also finetune Qwen2-Audio-Instruct with human judgment data as Auto-ATT for automatic evaluation. Experimental results show that ATT effectively differentiates models across specific capability dimensions using its multi-dimensional design. Auto-ATT also demonstrates strong alignment with human evaluations, confirming its value as a fast and reliable assessment tool. The white-box ATT-Corpus and Auto-ATT can be found in ATT Hugging Face Collection (https://huggingface.co/collections/meituan/audio-turing-test-682446320368164faeaf38a4).
AS-Speech: Adaptive Style For Speech Synthesis
Sep 09, 2024



In recent years, there has been significant progress in Text-to-Speech (TTS) synthesis technology, enabling the high-quality synthesis of voices in common scenarios. In unseen situations, adaptive TTS requires a strong generalization capability to speaker style characteristics. However, the existing adaptive methods can only extract and integrate coarse-grained timbre or mixed rhythm attributes separately. In this paper, we propose AS-Speech, an adaptive style methodology that integrates the speaker timbre characteristics and rhythmic attributes into a unified framework for text-to-speech synthesis. Specifically, AS-Speech can accurately simulate style characteristics through fine-grained text-based timbre features and global rhythm information, and achieve high-fidelity speech synthesis through the diffusion model. Experiments show that the proposed model produces voices with higher naturalness and similarity in terms of timbre and rhythm compared to a series of adaptive TTS models.
MSR-86K: An Evolving, Multilingual Corpus with 86,300 Hours of Transcribed Audio for Speech Recognition Research
Jun 26, 2024
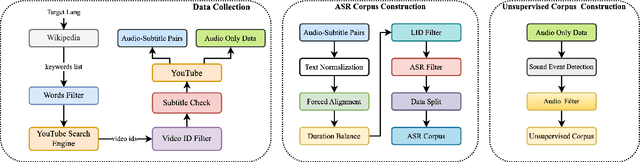


Recently, multilingual artificial intelligence assistants, exemplified by ChatGPT, have gained immense popularity. As a crucial gateway to human-computer interaction, multilingual automatic speech recognition (ASR) has also garnered significant attention, as evidenced by systems like Whisper. However, the proprietary nature of the training data has impeded researchers' efforts to study multilingual ASR. This paper introduces MSR-86K, an evolving, large-scale multilingual corpus for speech recognition research. The corpus is derived from publicly accessible videos on YouTube, comprising 15 languages and a total of 86,300 hours of transcribed ASR data. We also introduce how to use the MSR-86K corpus and other open-source corpora to train a robust multilingual ASR model that is competitive with Whisper. MSR-86K will be publicly released on HuggingFace, and we believe that such a large corpus will pave new avenues for research in multilingual ASR.
CLAQ: Pushing the Limits of Low-Bit Post-Training Quantization for LLMs
May 27, 2024Parameter quantization for Large Language Models (LLMs) has attracted increasing attentions recently in reducing memory costs and improving computational efficiency. Early approaches have been widely adopted. However, the existing methods suffer from poor performance in low-bit (such as 2 to 3 bits) scenarios. In this paper, we present a novel and effective Column-Level Adaptive weight Quantization (CLAQ) framework by introducing three different types of adaptive strategies for LLM quantization. Firstly, a K-Means clustering based algorithm is proposed that allows dynamic generation of quantization centroids for each column of a parameter matrix. Secondly, we design an outlier-guided adaptive precision search strategy which can dynamically assign varying bit-widths to different columns. Finally, a dynamic outlier reservation scheme is developed to retain some parameters in their original float point precision, in trade off of boosted model performance. Experiments on various mainstream open source LLMs including LLaMA-1, LLaMA-2 and Yi demonstrate that our methods achieve the state-of-the-art results across different bit settings, especially in extremely low-bit scenarios. Code will be released soon.
Learning or Self-aligning? Rethinking Instruction Fine-tuning
Mar 02, 2024



Instruction Fine-tuning~(IFT) is a critical phase in building large language models~(LLMs). Previous works mainly focus on the IFT's role in the transfer of behavioral norms and the learning of additional world knowledge. However, the understanding of the underlying mechanisms of IFT remains significantly limited. In this paper, we design a knowledge intervention framework to decouple the potential underlying factors of IFT, thereby enabling individual analysis of different factors. Surprisingly, our experiments reveal that attempting to learn additional world knowledge through IFT often struggles to yield positive impacts and can even lead to markedly negative effects. Further, we discover that maintaining internal knowledge consistency before and after IFT is a critical factor for achieving successful IFT. Our findings reveal the underlying mechanisms of IFT and provide robust support for some very recent and potential future works.
A Task-oriented Dialog Model with Task-progressive and Policy-aware Pre-training
Oct 01, 2023Pre-trained conversation models (PCMs) have achieved promising progress in recent years. However, existing PCMs for Task-oriented dialog (TOD) are insufficient for capturing the sequential nature of the TOD-related tasks, as well as for learning dialog policy information. To alleviate these problems, this paper proposes a task-progressive PCM with two policy-aware pre-training tasks. The model is pre-trained through three stages where TOD-related tasks are progressively employed according to the task logic of the TOD system. A global policy consistency task is designed to capture the multi-turn dialog policy sequential relation, and an act-based contrastive learning task is designed to capture similarities among samples with the same dialog policy. Our model achieves better results on both MultiWOZ and In-Car end-to-end dialog modeling benchmarks with only 18\% parameters and 25\% pre-training data compared to the previous state-of-the-art PCM, GALAXY.
CPPF: A contextual and post-processing-free model for automatic speech recognition
Sep 21, 2023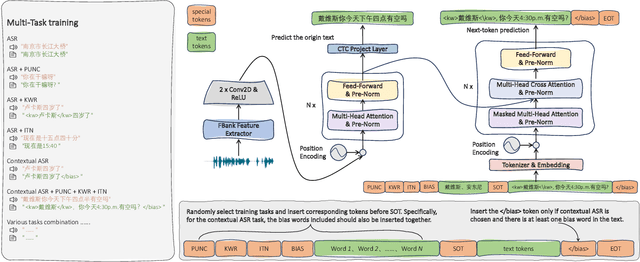
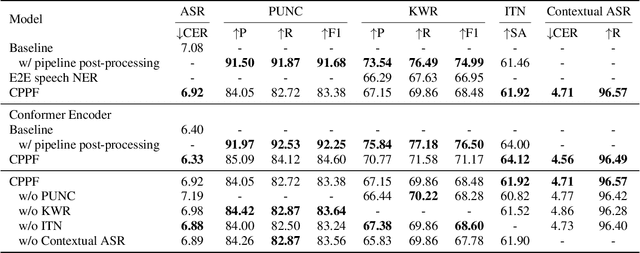

ASR systems have become increasingly widespread in recent years. However, their textual outputs often require post-processing tasks before they can be practically utilized. To address this issue, we draw inspiration from the multifaceted capabilities of LLMs and Whisper, and focus on integrating multiple ASR text processing tasks related to speech recognition into the ASR model. This integration not only shortens the multi-stage pipeline, but also prevents the propagation of cascading errors, resulting in direct generation of post-processed text. In this study, we focus on ASR-related processing tasks, including Contextual ASR and multiple ASR post processing tasks. To achieve this objective, we introduce the CPPF model, which offers a versatile and highly effective alternative to ASR processing. CPPF seamlessly integrates these tasks without any significant loss in recognition performance.
Enhancing Multilingual Speech Recognition through Language Prompt Tuning and Frame-Level Language Adapter
Sep 19, 2023
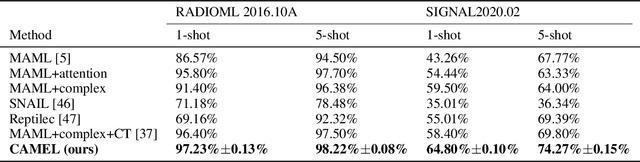

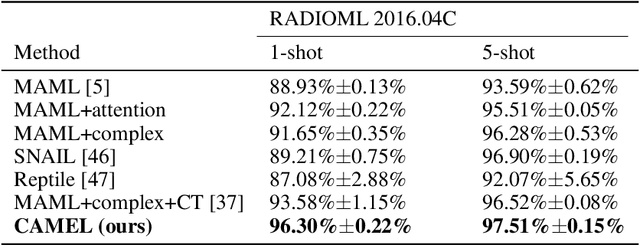
Multilingual intelligent assistants, such as ChatGPT, have recently gained popularity. To further expand the applications of multilingual artificial intelligence assistants and facilitate international communication, it is essential to enhance the performance of multilingual speech recognition, which is a crucial component of speech interaction. In this paper, we propose two simple and parameter-efficient methods: language prompt tuning and frame-level language adapter, to respectively enhance language-configurable and language-agnostic multilingual speech recognition. Additionally, we explore the feasibility of integrating these two approaches using parameter-efficient fine-tuning methods. Our experiments demonstrate significant performance improvements across seven languages using our proposed methods.