 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Pseudo Future Contexts for Emotion Recognition in Conversations
Jun 27, 2023With the extensive accumulation of conversational data on the Internet, emotion recognition in conversations (ERC) has received increasing attention. Previous efforts of this task mainly focus on leveraging contextual and speaker-specific features, or integrating heterogeneous external commonsense knowledge. Among them, some heavily rely on future contexts, which, however, are not always available in real-life scenarios. This fact inspires us to generate pseudo future contexts to improve ERC. Specifically, for an utterance, we generate its future context with pre-trained language models, potentially containing extra beneficial knowledge in a conversational form homogeneous with the historical ones. These characteristics make pseudo future contexts easily fused with historical contexts and historical speaker-specific contexts, yielding a conceptually simple framework systematically integrating multi-contexts. Experimental results on four ERC datasets demonstrate our method's superiority. Further in-depth analyses reveal that pseudo future contexts can rival real ones to some extent, especially in relatively context-independent conversations.
Eliciting Knowledge from Pretrained Language Models for Prototypical Prompt Verbalizer
Jan 14, 2022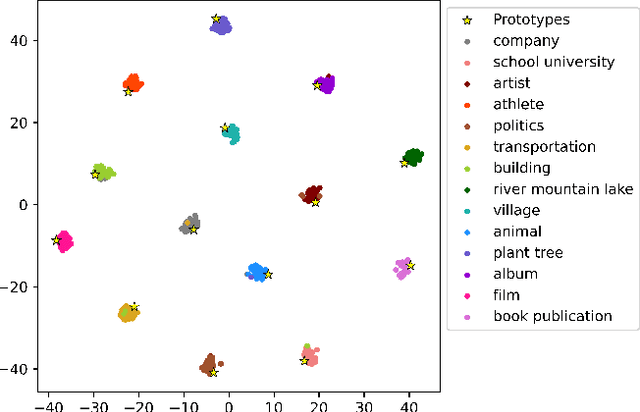
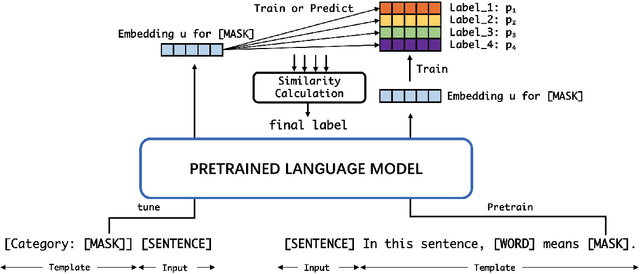
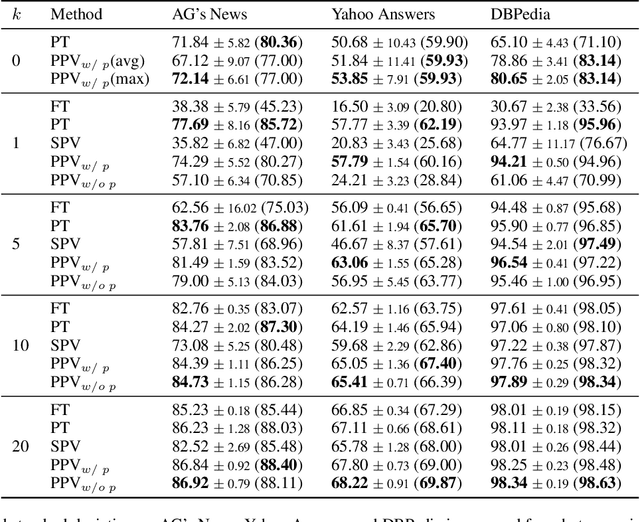
Recent advances on prompt-tuning cast few-shot classification tasks as a masked language modeling problem. By wrapping input into a template and using a verbalizer which constructs a mapping between label space and label word space, prompt-tuning can achieve excellent results in zero-shot and few-shot scenarios. However, typical prompt-tuning needs a manually designed verbalizer which requires domain expertise and human efforts. And the insufficient label space may introduce considerable bias into the results. In this paper, we focus on eliciting knowledge from pretrained language models and propose a prototypical prompt verbalizer for prompt-tuning. Labels are represented by prototypical embeddings in the feature space rather than by discrete words. The distances between the embedding at the masked position of input and prototypical embeddings are used as classification criterion. For zero-shot settings, knowledge is elicited from pretrained language models by a manually designed template to form initial prototypical embeddings. For few-shot settings, models are tuned to learn meaningful and interpretable prototypical embeddings. Our method optimizes models by contrastive learning. Extensive experimental results on several many-class text classification datasets with low-resource settings demonstrate the effectiveness of our approach compared with other verbalizer construction methods. Our implementation is available at https://github.com/Ydongd/prototypical-prompt-verbalizer.