 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEliciting Knowledge from Pretrained Language Models for Prototypical Prompt Verbalizer
Jan 14, 2022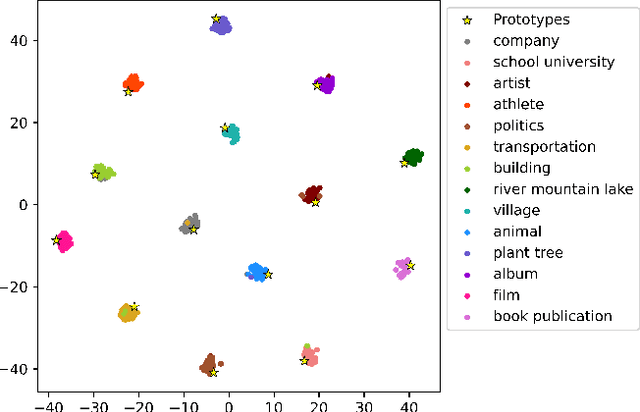
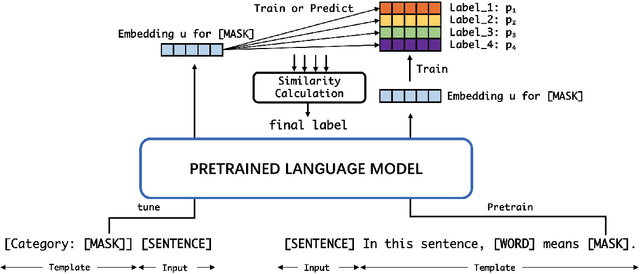
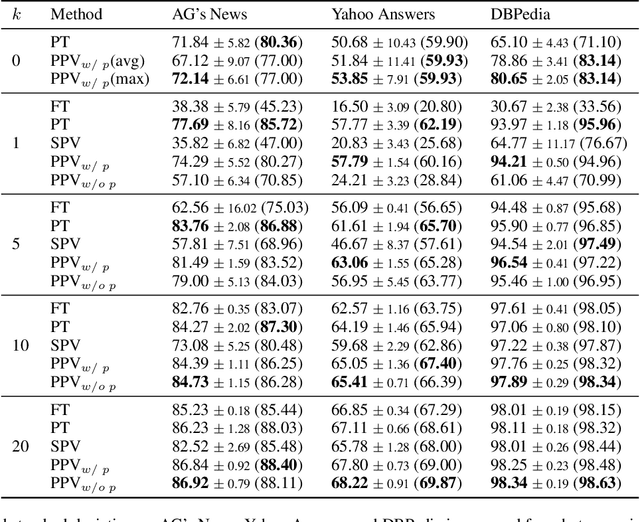
Recent advances on prompt-tuning cast few-shot classification tasks as a masked language modeling problem. By wrapping input into a template and using a verbalizer which constructs a mapping between label space and label word space, prompt-tuning can achieve excellent results in zero-shot and few-shot scenarios. However, typical prompt-tuning needs a manually designed verbalizer which requires domain expertise and human efforts. And the insufficient label space may introduce considerable bias into the results. In this paper, we focus on eliciting knowledge from pretrained language models and propose a prototypical prompt verbalizer for prompt-tuning. Labels are represented by prototypical embeddings in the feature space rather than by discrete words. The distances between the embedding at the masked position of input and prototypical embeddings are used as classification criterion. For zero-shot settings, knowledge is elicited from pretrained language models by a manually designed template to form initial prototypical embeddings. For few-shot settings, models are tuned to learn meaningful and interpretable prototypical embeddings. Our method optimizes models by contrastive learning. Extensive experimental results on several many-class text classification datasets with low-resource settings demonstrate the effectiveness of our approach compared with other verbalizer construction methods. Our implementation is available at https://github.com/Ydongd/prototypical-prompt-verbalizer.