 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeavySkill: Heavy Thinking as the Inner Skill in Agentic Harness
May 04, 2026Recent advances in agentic harness with orchestration frameworks that coordinate multiple agents with memory, skills, and tool use have achieved remarkable success in complex reasoning tasks. However, the underlying mechanism that truly drives performance remains obscured behind intricate system designs. In this paper, we propose HeavySkill, a perspective that views heavy thinking not only as a minimal execution unit in orchestration harness but also as an inner skill internalized within the model's parameters that drives the orchestrator to solve complex tasks. We identify this skill as a two-stage pipeline, i.e., parallel reasoning then summarization, which can operate beneath any agentic harness. We present a systematic empirical study of HeavySkill across diverse domains. Our results show that this inner skill consistently outperforms traditional Best-of-N (BoN) strategies; notably, stronger LLMs can even approach Pass@N performance. Crucially, we demonstrate that the depth and width of heavy thinking, as a learnable skill, can be further scaled via reinforcement learning, offering a promising path toward self-evolving LLMs that internalize complex reasoning without relying on brittle orchestration layers.
On the Role of Reasoning Patterns in the Generalization Discrepancy of Long Chain-of-Thought Supervised Fine-Tuning
Apr 02, 2026Supervised Fine-Tuning (SFT) on long Chain-of-Thought (CoT) trajectories has become a pivotal phase in building large reasoning models. However, how CoT trajectories from different sources influence the generalization performance of models remains an open question. In this paper, we conduct a comparative study using two sources of verified CoT trajectories generated by two competing models, \texttt{DeepSeek-R1-0528} and \texttt{gpt-oss-120b}, with their problem sets controlled to be identical. Despite their comparable performance, we uncover a striking paradox: lower training loss does not translate to better generalization. SFT on \texttt{DeepSeek-R1-0528} data achieves remarkably lower training loss, yet exhibits significantly worse generalization performance on reasoning benchmarks compared to those trained on \texttt{gpt-oss-120b}. To understand this paradox, we perform a multi-faceted analysis probing token-level SFT loss and step-level reasoning behaviors. Our analysis reveals a difference in reasoning patterns. \texttt{gpt-oss-120b} exhibits highly convergent and deductive trajectories, whereas \texttt{DeepSeek-R1-0528} favors a divergent and branch-heavy exploration pattern. Consequently, models trained with \texttt{DeepSeek-R1} data inherit inefficient exploration behaviors, often getting trapped in redundant exploratory branches that hinder them from reaching correct solutions. Building upon this insight, we propose a simple yet effective remedy of filtering out frequently branching trajectories to improve the generalization of SFT. Experiments show that training on selected \texttt{DeepSeek-R1-0528} subsets surprisingly improves reasoning performance by up to 5.1% on AIME25, 5.5% on BeyondAIME, and on average 3.6% on five benchmarks.
LongCat-Flash-Prover: Advancing Native Formal Reasoning via Agentic Tool-Integrated Reinforcement Learning
Mar 22, 2026We introduce LongCat-Flash-Prover, a flagship 560-billion-parameter open-source Mixture-of- Experts (MoE) model that advances Native Formal Reasoning in Lean4 through agentic tool-integrated reasoning (TIR). We decompose the native formal reasoning task into three independent formal capabilities, i.e., auto-formalization, sketching, and proving. To facilitate these capabilities, we propose a Hybrid-Experts Iteration Framework to expand high-quality task trajectories, including generating a formal statement based on a given informal problem, producing a whole-proof directly from the statement, or a lemma-style sketch. During agentic RL, we present a Hierarchical Importance Sampling Policy Optimization (HisPO) algorithm, which aims to stabilize the MoE model training on such long-horizon tasks. It employs a gradient masking strategy that accounts for the policy staleness and the inherent train-inference engine discrepancies at both sequence and token levels. Additionally, we also incorporate theorem consistency and legality detection mechanisms to eliminate reward hacking issues. Extensive evaluations show that our LongCat-Flash-Prover sets a new state-of-the-art for open-weights models in both auto-formalization and theorem proving. Demonstrating remarkable sample efficiency, it achieves a 97.1% pass rate on MiniF2F-Test using only 72 inference budget per problem. On more challenging benchmarks, it solves 70.8% of ProverBench and 41.5% of PutnamBench with no more than 220 attempts per problem, significantly outperforming existing open-weights baselines.
OPE: Overcoming Information Saturation in Parallel Thinking via Outline-Guided Path Exploration
Feb 09, 2026Parallel thinking has emerged as a new paradigm for large reasoning models (LRMs) in tackling complex problems. Recent methods leverage Reinforcement Learning (RL) to enhance parallel thinking, aiming to address the limitations in computational resources and effectiveness encountered with supervised fine-tuning. However, most existing studies primarily focus on optimizing the aggregation phase, with limited attention to the path exploration stage. In this paper, we theoretically analyze the optimization of parallel thinking under the Reinforcement Learning with Verifiable Rewards (RLVR) setting, and identify that the mutual information bottleneck among exploration paths fundamentally restricts overall performance. To address this, we propose Outline-Guided Path Exploration (OPE), which explicitly partitions the solution space by generating diverse reasoning outlines prior to parallel path reasoning, thereby reducing information redundancy and improving the diversity of information captured across exploration paths. We implement OPE with an iterative RL strategy that optimizes outline planning and outline-guided reasoning independently. Extensive experiments across multiple challenging mathematical benchmarks demonstrate that OPE effectively improves reasoning performance in different aggregation strategies, enabling LRMs to more reliably discover correct solutions.
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
Autoformalizer with Tool Feedback
Oct 08, 2025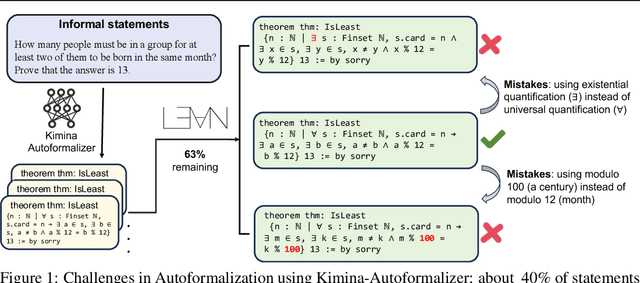

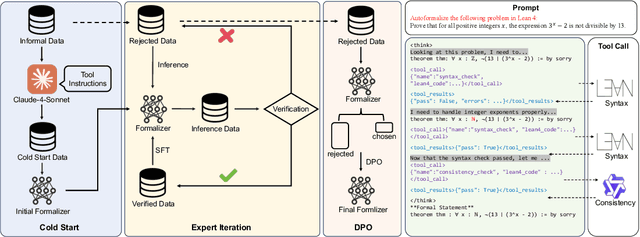
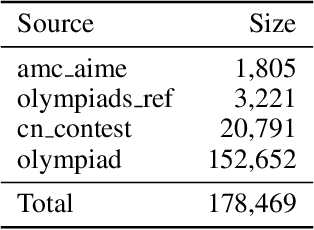
Autoformalization addresses the scarcity of data for Automated Theorem Proving (ATP) by translating mathematical problems from natural language into formal statements. Efforts in recent work shift from directly prompting large language models to training an end-to-end formalizer model from scratch, achieving remarkable advancements. However, existing formalizer still struggles to consistently generate valid statements that meet syntactic validity and semantic consistency. To address this issue, we propose the Autoformalizer with Tool Feedback (ATF), a novel approach that incorporates syntactic and consistency information as tools into the formalization process. By integrating Lean 4 compilers for syntax corrections and employing a multi-LLMs-as-judge approach for consistency validation, the model is able to adaptively refine generated statements according to the tool feedback, enhancing both syntactic validity and semantic consistency. The training of ATF involves a cold-start phase on synthetic tool-calling data, an expert iteration phase to improve formalization capabilities, and Direct Preference Optimization to alleviate ineffective revisions. Experimental results show that ATF markedly outperforms a range of baseline formalizer models, with its superior performance further validated by human evaluations. Subsequent analysis reveals that ATF demonstrates excellent inference scaling properties. Moreover, we open-source Numina-ATF, a dataset containing 750K synthetic formal statements to facilitate advancements in autoformalization and ATP research.
Enhancing Efficiency and Exploration in Reinforcement Learning for LLMs
May 24, 2025Reasoning large language models (LLMs) excel in complex tasks, which has drawn significant attention to reinforcement learning (RL) for LLMs. However, existing approaches allocate an equal number of rollouts to all questions during the RL process, which is inefficient. This inefficiency stems from the fact that training on simple questions yields limited gains, whereas more rollouts are needed for challenging questions to sample correct answers. Furthermore, while RL improves response precision, it limits the model's exploration ability, potentially resulting in a performance cap below that of the base model prior to RL. To address these issues, we propose a mechanism for dynamically allocating rollout budgets based on the difficulty of the problems, enabling more efficient RL training. Additionally, we introduce an adaptive dynamic temperature adjustment strategy to maintain the entropy at a stable level, thereby encouraging sufficient exploration. This enables LLMs to improve response precision while preserving their exploratory ability to uncover potential correct pathways. The code and data is available on: https://github.com/LiaoMengqi/E3-RL4LLMs
Rethinking the Sampling Criteria in Reinforcement Learning for LLM Reasoning: A Competence-Difficulty Alignment Perspective
May 23, 2025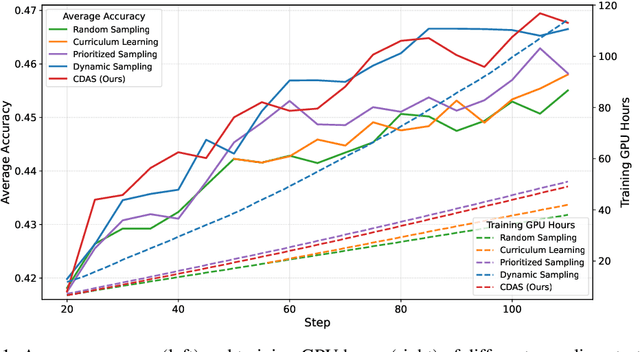
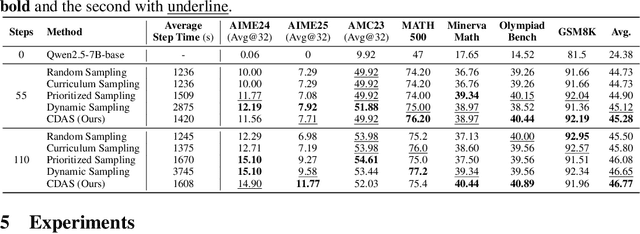
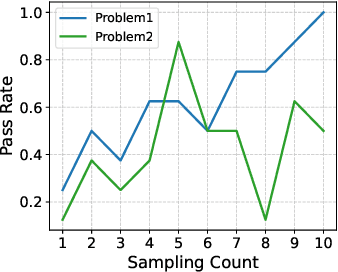
Reinforcement learning exhibits potential in enhancing the reasoning abilities of large language models, yet it is hard to scale for the low sample efficiency during the rollout phase. Existing methods attempt to improve efficiency by scheduling problems based on problem difficulties. However, these approaches suffer from unstable and biased estimations of problem difficulty and fail to capture the alignment between model competence and problem difficulty in RL training, leading to suboptimal results. To tackle these limitations, this paper introduces \textbf{C}ompetence-\textbf{D}ifficulty \textbf{A}lignment \textbf{S}ampling (\textbf{CDAS}), which enables accurate and stable estimation of problem difficulties by aggregating historical performance discrepancies of problems. Then the model competence is quantified to adaptively select problems whose difficulty is in alignment with the model's current competence using a fixed-point system. Experimental results across a range of challenging mathematical benchmarks show that CDAS achieves great improvements in both accuracy and efficiency. CDAS attains the highest average accuracy against baselines and exhibits significant speed advantages compared to Dynamic Sampling, a competitive strategy in DAPO, which is \textbf{2.33} times slower than CDAS.
SampleMix: A Sample-wise Pre-training Data Mixing Strategey by Coordinating Data Quality and Diversity
Mar 03, 2025Existing pretraining data mixing methods for large language models (LLMs) typically follow a domain-wise methodology, a top-down process that first determines domain weights and then performs uniform data sampling across each domain. However, these approaches neglect significant inter-domain overlaps and commonalities, failing to control the global diversity of the constructed training dataset. Further, uniform sampling within domains ignores fine-grained sample-specific features, potentially leading to suboptimal data distribution. To address these shortcomings, we propose a novel sample-wise data mixture approach based on a bottom-up paradigm. This method performs global cross-domain sampling by systematically evaluating the quality and diversity of each sample, thereby dynamically determining the optimal domain distribution. Comprehensive experiments across multiple downstream tasks and perplexity assessments demonstrate that SampleMix surpasses existing domain-based methods. Meanwhile, SampleMix requires 1.4x to 2.1x training steps to achieves the baselines' performance, highlighting the substantial potential of SampleMix to optimize pre-training data.
Dialog-to-Actions: Building Task-Oriented Dialogue System via Action-Level Generation
Apr 03, 2023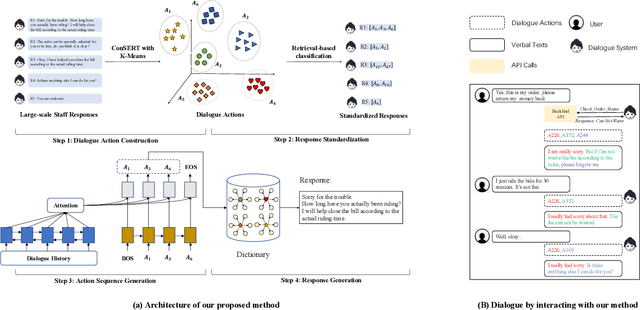

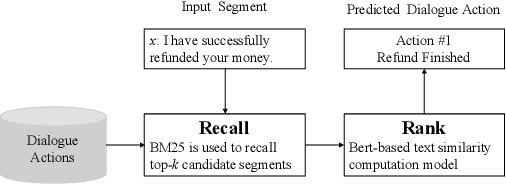
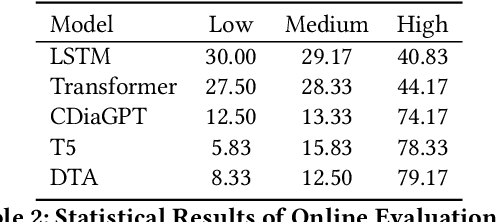
End-to-end generation-based approaches have been investigated and applied in task-oriented dialogue systems. However, in industrial scenarios, existing methods face the bottlenecks of controllability (e.g., domain-inconsistent responses, repetition problem, etc) and efficiency (e.g., long computation time, etc). In this paper, we propose a task-oriented dialogue system via action-level generation. Specifically, we first construct dialogue actions from large-scale dialogues and represent each natural language (NL) response as a sequence of dialogue actions. Further, we train a Sequence-to-Sequence model which takes the dialogue history as input and outputs sequence of dialogue actions. The generated dialogue actions are transformed into verbal responses. Experimental results show that our light-weighted method achieves competitive performance, and has the advantage of controllability and efficiency.