 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Complex Instruction Following for Large Language Models with Mixture-of-Contexts Fine-tuning
May 17, 2025Large language models (LLMs) exhibit remarkable capabilities in handling natural language tasks; however, they may struggle to consistently follow complex instructions including those involve multiple constraints. Post-training LLMs using supervised fine-tuning (SFT) is a standard approach to improve their ability to follow instructions. In addressing complex instruction following, existing efforts primarily focus on data-driven methods that synthesize complex instruction-output pairs for SFT. However, insufficient attention allocated to crucial sub-contexts may reduce the effectiveness of SFT. In this work, we propose transforming sequentially structured input instruction into multiple parallel instructions containing subcontexts. To support processing this multi-input, we propose MISO (Multi-Input Single-Output), an extension to currently dominant decoder-only transformer-based LLMs. MISO introduces a mixture-of-contexts paradigm that jointly considers the overall instruction-output alignment and the influence of individual sub-contexts to enhance SFT effectiveness. We apply MISO fine-tuning to complex instructionfollowing datasets and evaluate it with standard LLM inference. Empirical results demonstrate the superiority of MISO as a fine-tuning method for LLMs, both in terms of effectiveness in complex instruction-following scenarios and its potential for training efficiency.
FreeGraftor: Training-Free Cross-Image Feature Grafting for Subject-Driven Text-to-Image Generation
Apr 22, 2025Subject-driven image generation aims to synthesize novel scenes that faithfully preserve subject identity from reference images while adhering to textual guidance, yet existing methods struggle with a critical trade-off between fidelity and efficiency. Tuning-based approaches rely on time-consuming and resource-intensive subject-specific optimization, while zero-shot methods fail to maintain adequate subject consistency. In this work, we propose FreeGraftor, a training-free framework that addresses these limitations through cross-image feature grafting. Specifically, FreeGraftor employs semantic matching and position-constrained attention fusion to transfer visual details from reference subjects to the generated image. Additionally, our framework incorporates a novel noise initialization strategy to preserve geometry priors of reference subjects for robust feature matching. Extensive qualitative and quantitative experiments demonstrate that our method enables precise subject identity transfer while maintaining text-aligned scene synthesis. Without requiring model fine-tuning or additional training, FreeGraftor significantly outperforms existing zero-shot and training-free approaches in both subject fidelity and text alignment. Furthermore, our framework can seamlessly extend to multi-subject generation, making it practical for real-world deployment. Our code is available at https://github.com/Nihukat/FreeGraftor.
Controlled Low-Rank Adaptation with Subspace Regularization for Continued Training on Large Language Models
Oct 22, 2024



Large language models (LLMs) exhibit remarkable capabilities in natural language processing but face catastrophic forgetting when learning new tasks, where adaptation to a new domain leads to a substantial decline in performance on previous tasks. In this paper, we propose Controlled LoRA (CLoRA), a subspace regularization method on LoRA structure. Aiming to reduce the scale of output change while introduce minimal constraint on model capacity, CLoRA imposes constraint on the direction of updating matrix null space. Experimental results on commonly used LLM finetuning tasks reveal that CLoRA significantly outperforms existing LoRA subsequent methods on both in-domain and outdomain evaluations, highlighting the superority of CLoRA as a effective parameter-efficient finetuning method with catastrophic forgetting mitigating. Further investigation for model parameters indicates that CLoRA effectively balances the trade-off between model capacity and degree of forgetting.
Domain-Oriented Prefix-Tuning: Towards Efficient and Generalizable Fine-tuning for Zero-Shot Dialogue Summarization
Apr 09, 2022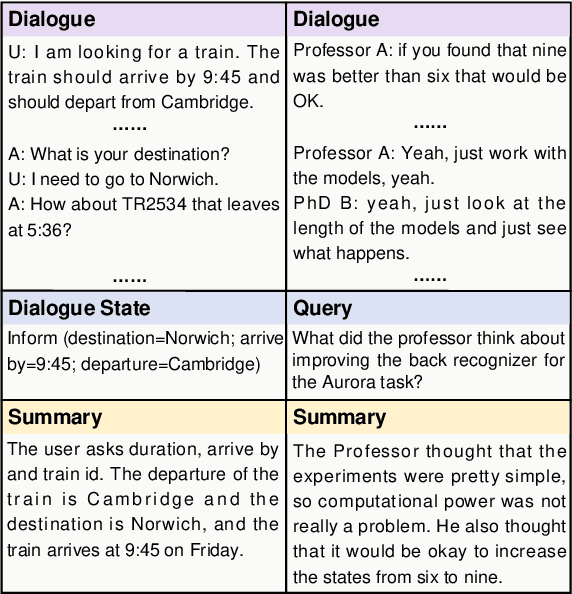
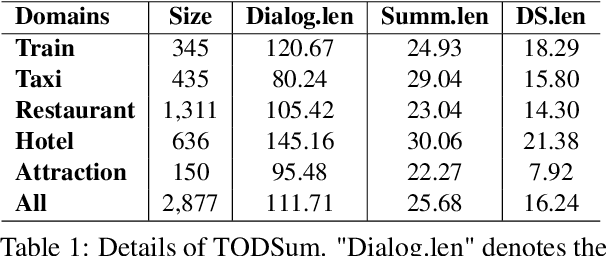
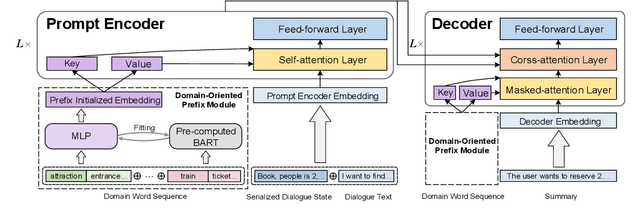
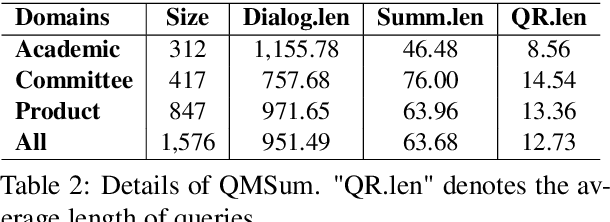
The most advanced abstractive dialogue summarizers lack generalization ability on new domains and the existing researches for domain adaptation in summarization generally rely on large-scale pre-trainings. To explore the lightweight fine-tuning methods for domain adaptation of dialogue summarization, in this paper, we propose an efficient and generalizable Domain-Oriented Prefix-tuning model, which utilizes a domain word initialized prefix module to alleviate domain entanglement and adopts discrete prompts to guide the model to focus on key contents of dialogues and enhance model generalization. We conduct zero-shot experiments and build domain adaptation benchmarks on two multi-domain dialogue summarization datasets, TODSum and QMSum. Adequate experiments and qualitative analysis prove the effectiveness of our methods.
Co-VQA : Answering by Interactive Sub Question Sequence
Apr 02, 2022
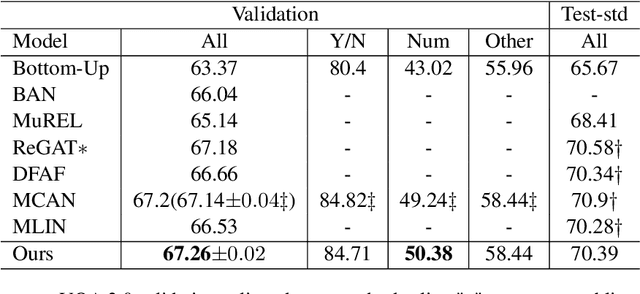
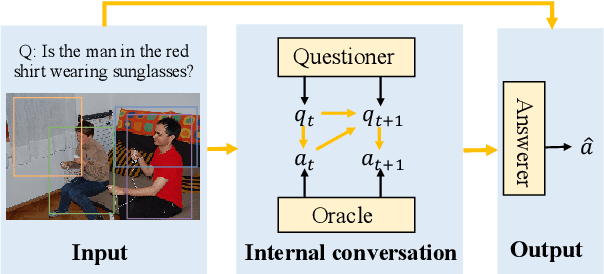
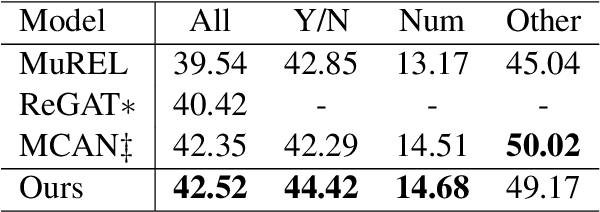
Most existing approaches to Visual Question Answering (VQA) answer questions directly, however, people usually decompose a complex question into a sequence of simple sub questions and finally obtain the answer to the original question after answering the sub question sequence(SQS). By simulating the process, this paper proposes a conversation-based VQA (Co-VQA) framework, which consists of three components: Questioner, Oracle, and Answerer. Questioner raises the sub questions using an extending HRED model, and Oracle answers them one-by-one. An Adaptive Chain Visual Reasoning Model (ACVRM) for Answerer is also proposed, where the question-answer pair is used to update the visual representation sequentially. To perform supervised learning for each model, we introduce a well-designed method to build a SQS for each question on VQA 2.0 and VQA-CP v2 datasets. Experimental results show that our method achieves state-of-the-art on VQA-CP v2. Further analyses show that SQSs help build direct semantic connections between questions and images, provide question-adaptive variable-length reasoning chains, and with explicit interpretability as well as error traceability.
TODSum: Task-Oriented Dialogue Summarization with State Tracking
Oct 25, 2021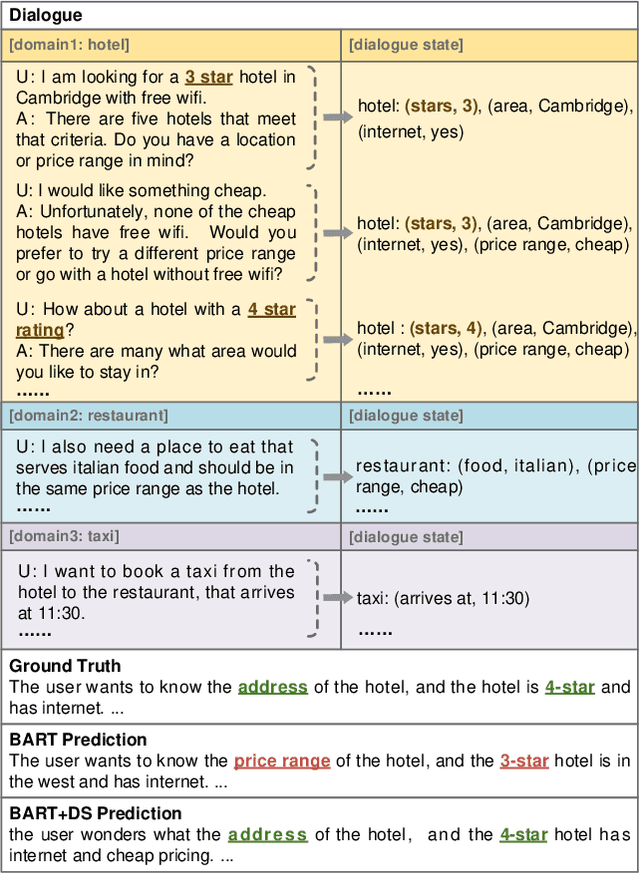
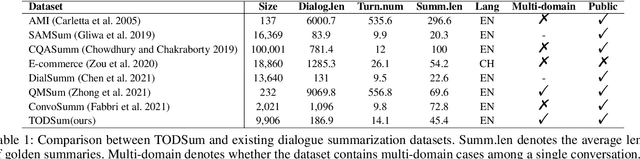

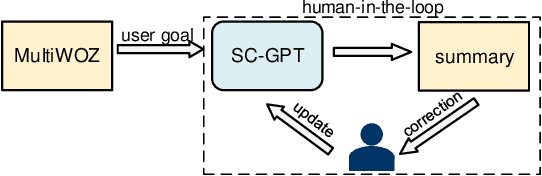
Previous dialogue summarization datasets mainly focus on open-domain chitchat dialogues, while summarization datasets for the broadly used task-oriented dialogue haven't been explored yet. Automatically summarizing such task-oriented dialogues can help a business collect and review needs to improve the service. Besides, previous datasets pay more attention to generate good summaries with higher ROUGE scores, but they hardly understand the structured information of dialogues and ignore the factuality of summaries. In this paper, we introduce a large-scale public Task-Oriented Dialogue Summarization dataset, TODSum, which aims to summarize the key points of the agent completing certain tasks with the user. Compared to existing work, TODSum suffers from severe scattered information issues and requires strict factual consistency, which makes it hard to directly apply recent dialogue summarization models. Therefore, we introduce additional dialogue state knowledge for TODSum to enhance the faithfulness of generated summaries. We hope a better understanding of conversational content helps summarization models generate concise and coherent summaries. Meanwhile, we establish a comprehensive benchmark for TODSum and propose a state-aware structured dialogue summarization model to integrate dialogue state information and dialogue history. Exhaustive experiments and qualitative analysis prove the effectiveness of dialogue structure guidance. Finally, we discuss the current issues of TODSum and potential development directions for future work.
Capturing Event Argument Interaction via A Bi-Directional Entity-Level Recurrent Decoder
Jul 01, 2021
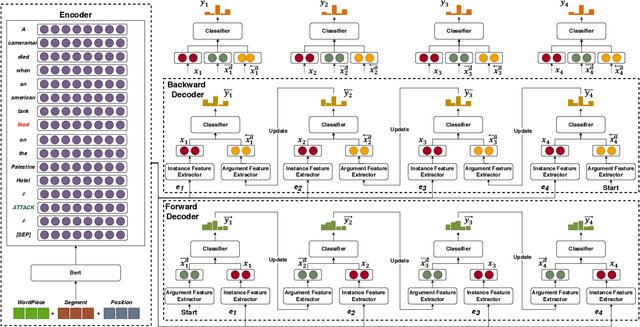
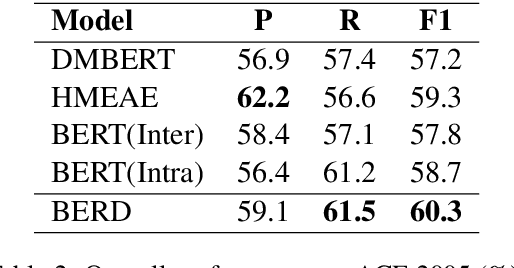
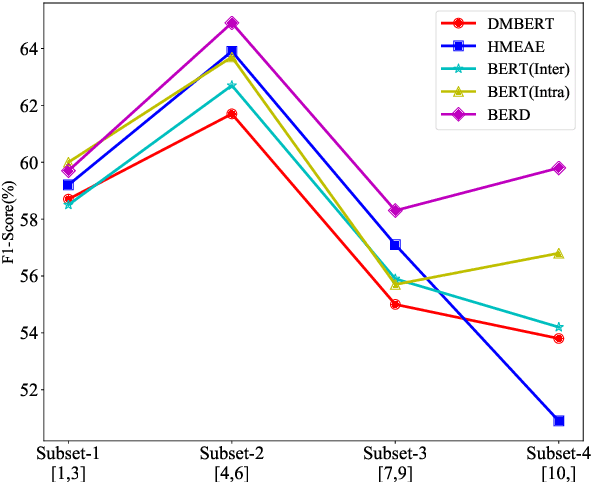
Capturing interactions among event arguments is an essential step towards robust event argument extraction (EAE). However, existing efforts in this direction suffer from two limitations: 1) The argument role type information of contextual entities is mainly utilized as training signals, ignoring the potential merits of directly adopting it as semantically rich input features; 2) The argument-level sequential semantics, which implies the overall distribution pattern of argument roles over an event mention, is not well characterized. To tackle the above two bottlenecks, we formalize EAE as a Seq2Seq-like learning problem for the first time, where a sentence with a specific event trigger is mapped to a sequence of event argument roles. A neural architecture with a novel Bi-directional Entity-level Recurrent Decoder (BERD) is proposed to generate argument roles by incorporating contextual entities' argument role predictions, like a word-by-word text generation process, thereby distinguishing implicit argument distribution patterns within an event more accurately.
Novel Slot Detection: A Benchmark for Discovering Unknown Slot Types in the Task-Oriented Dialogue System
May 29, 2021



Existing slot filling models can only recognize pre-defined in-domain slot types from a limited slot set. In the practical application, a reliable dialogue system should know what it does not know. In this paper, we introduce a new task, Novel Slot Detection (NSD), in the task-oriented dialogue system. NSD aims to discover unknown or out-of-domain slot types to strengthen the capability of a dialogue system based on in-domain training data. Besides, we construct two public NSD datasets, propose several strong NSD baselines, and establish a benchmark for future work. Finally, we conduct exhaustive experiments and qualitative analysis to comprehend key challenges and provide new guidance for future directions.
* Accepted by ACL2021
Modeling Discriminative Representations for Out-of-Domain Detection with Supervised Contrastive Learning
May 29, 2021



Detecting Out-of-Domain (OOD) or unknown intents from user queries is essential in a task-oriented dialog system. A key challenge of OOD detection is to learn discriminative semantic features. Traditional cross-entropy loss only focuses on whether a sample is correctly classified, and does not explicitly distinguish the margins between categories. In this paper, we propose a supervised contrastive learning objective to minimize intra-class variance by pulling together in-domain intents belonging to the same class and maximize inter-class variance by pushing apart samples from different classes. Besides, we employ an adversarial augmentation mechanism to obtain pseudo diverse views of a sample in the latent space. Experiments on two public datasets prove the effectiveness of our method capturing discriminative representations for OOD detection.
* Accepted by ACL2021
Converse, Focus and Guess -- Towards Multi-Document Driven Dialogue
Feb 04, 2021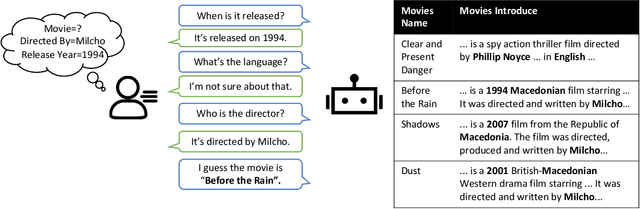


We propose a novel task, Multi-Document Driven Dialogue (MD3), in which an agent can guess the target document that the user is interested in by leading a dialogue. To benchmark progress, we introduce a new dataset of GuessMovie, which contains 16,881 documents, each describing a movie, and associated 13,434 dialogues. Further, we propose the MD3 model. Keeping guessing the target document in mind, it converses with the user conditioned on both document engagement and user feedback. In order to incorporate large-scale external documents into the dialogue, it pretrains a document representation which is sensitive to attributes it talks about an object. Then it tracks dialogue state by detecting evolvement of document belief and attribute belief, and finally optimizes dialogue policy in principle of entropy decreasing and reward increasing, which is expected to successfully guess the user's target in a minimum number of turns. Experiments show that our method significantly outperforms several strong baseline methods and is very close to human's performance.