 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMAR: Soft Modality-Aware Routing Strategy for MoE-based Multimodal Large Language Models Preserving Language Capabilities
Jun 06, 2025Mixture of Experts (MoE) architectures have become a key approach for scaling large language models, with growing interest in extending them to multimodal tasks. Existing methods to build multimodal MoE models either incur high training costs or suffer from degraded language capabilities when adapting pretrained models. To address this, we propose Soft ModalityAware Routing (SMAR), a novel regularization technique that uses Kullback Leibler divergence to control routing probability distributions across modalities, encouraging expert specialization without modifying model architecture or heavily relying on textual data. Experiments on visual instruction tuning show that SMAR preserves language ability at 86.6% retention with only 2.5% pure text, outperforming baselines while maintaining strong multimodal performance. Our approach offers a practical and efficient solution to balance modality differentiation and language capabilities in multimodal MoE models.
FreeGraftor: Training-Free Cross-Image Feature Grafting for Subject-Driven Text-to-Image Generation
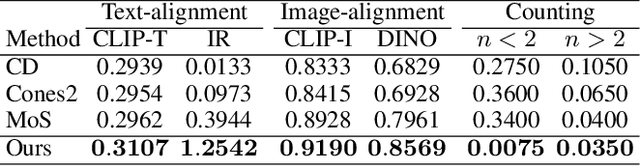
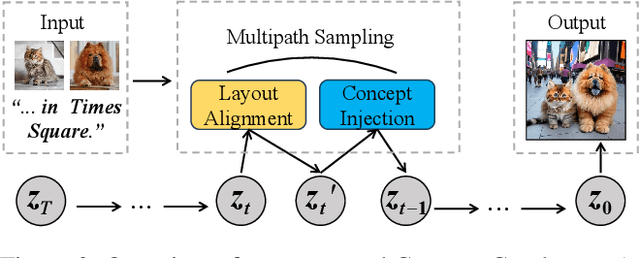
Apr 22, 2025Subject-driven image generation aims to synthesize novel scenes that faithfully preserve subject identity from reference images while adhering to textual guidance, yet existing methods struggle with a critical trade-off between fidelity and efficiency. Tuning-based approaches rely on time-consuming and resource-intensive subject-specific optimization, while zero-shot methods fail to maintain adequate subject consistency. In this work, we propose FreeGraftor, a training-free framework that addresses these limitations through cross-image feature grafting. Specifically, FreeGraftor employs semantic matching and position-constrained attention fusion to transfer visual details from reference subjects to the generated image. Additionally, our framework incorporates a novel noise initialization strategy to preserve geometry priors of reference subjects for robust feature matching. Extensive qualitative and quantitative experiments demonstrate that our method enables precise subject identity transfer while maintaining text-aligned scene synthesis. Without requiring model fine-tuning or additional training, FreeGraftor significantly outperforms existing zero-shot and training-free approaches in both subject fidelity and text alignment. Furthermore, our framework can seamlessly extend to multi-subject generation, making it practical for real-world deployment. Our code is available at https://github.com/Nihukat/FreeGraftor.
Infinity-MM: Scaling Multimodal Performance with Large-Scale and High-Quality Instruction Data
Oct 24, 2024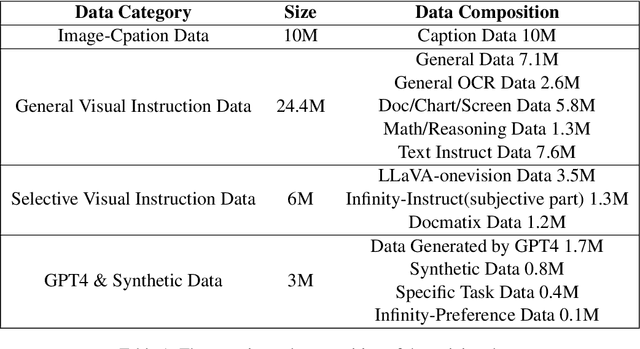
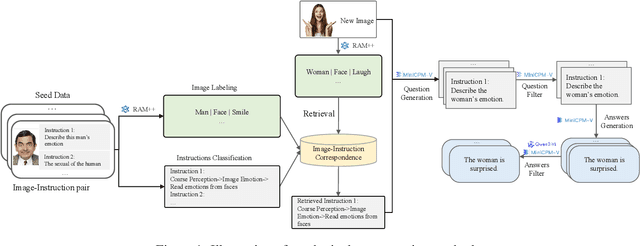
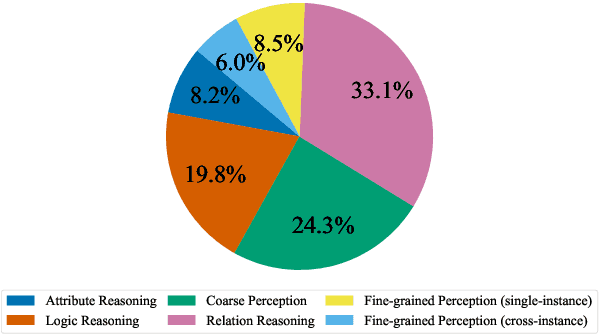
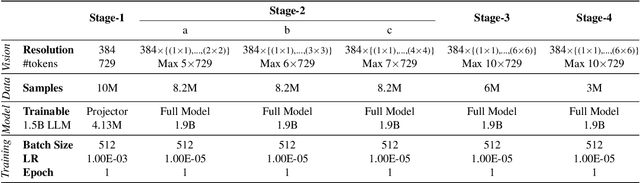
Vision-Language Models (VLMs) have recently made significant progress, but the limited scale and quality of open-source instruction data hinder their performance compared to closed-source models. In this work, we address this limitation by introducing Infinity-MM, a large-scale multimodal instruction dataset with 40 million samples, enhanced through rigorous quality filtering and deduplication. We also propose a synthetic instruction generation method based on open-source VLMs, using detailed image annotations and diverse question generation. Using this data, we trained a 2-billion-parameter VLM, Aquila-VL-2B, achieving state-of-the-art (SOTA) performance for models of similar scale. This demonstrates that expanding instruction data and generating synthetic data can significantly improve the performance of open-source models.
Concept Conductor: Orchestrating Multiple Personalized Concepts in Text-to-Image Synthesis
Aug 07, 2024
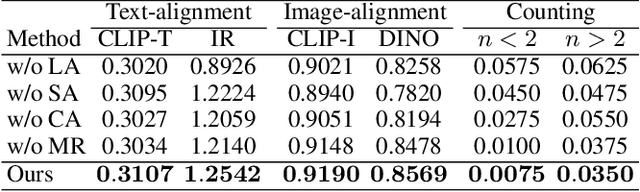
The customization of text-to-image models has seen significant advancements, yet generating multiple personalized concepts remains a challenging task. Current methods struggle with attribute leakage and layout confusion when handling multiple concepts, leading to reduced concept fidelity and semantic consistency. In this work, we introduce a novel training-free framework, Concept Conductor, designed to ensure visual fidelity and correct layout in multi-concept customization. Concept Conductor isolates the sampling processes of multiple custom models to prevent attribute leakage between different concepts and corrects erroneous layouts through self-attention-based spatial guidance. Additionally, we present a concept injection technique that employs shape-aware masks to specify the generation area for each concept. This technique injects the structure and appearance of personalized concepts through feature fusion in the attention layers, ensuring harmony in the final image. Extensive qualitative and quantitative experiments demonstrate that Concept Conductor can consistently generate composite images with accurate layouts while preserving the visual details of each concept. Compared to existing baselines, Concept Conductor shows significant performance improvements. Our method supports the combination of any number of concepts and maintains high fidelity even when dealing with visually similar concepts. The code and models are available at https://github.com/Nihukat/Concept-Conductor.
DiffHarmony: Latent Diffusion Model Meets Image Harmonization
Apr 09, 2024



Image harmonization, which involves adjusting the foreground of a composite image to attain a unified visual consistency with the background, can be conceptualized as an image-to-image translation task. Diffusion models have recently promoted the rapid development of image-to-image translation tasks . However, training diffusion models from scratch is computationally intensive. Fine-tuning pre-trained latent diffusion models entails dealing with the reconstruction error induced by the image compression autoencoder, making it unsuitable for image generation tasks that involve pixel-level evaluation metrics. To deal with these issues, in this paper, we first adapt a pre-trained latent diffusion model to the image harmonization task to generate the harmonious but potentially blurry initial images. Then we implement two strategies: utilizing higher-resolution images during inference and incorporating an additional refinement stage, to further enhance the clarity of the initially harmonized images. Extensive experiments on iHarmony4 datasets demonstrate the superiority of our proposed method. The code and model will be made publicly available at https://github.com/nicecv/DiffHarmony .
Whether you can locate or not? Interactive Referring Expression Generation
Aug 19, 2023



Referring Expression Generation (REG) aims to generate unambiguous Referring Expressions (REs) for objects in a visual scene, with a dual task of Referring Expression Comprehension (REC) to locate the referred object. Existing methods construct REG models independently by using only the REs as ground truth for model training, without considering the potential interaction between REG and REC models. In this paper, we propose an Interactive REG (IREG) model that can interact with a real REC model, utilizing signals indicating whether the object is located and the visual region located by the REC model to gradually modify REs. Our experimental results on three RE benchmark datasets, RefCOCO, RefCOCO+, and RefCOCOg show that IREG outperforms previous state-of-the-art methods on popular evaluation metrics. Furthermore, a human evaluation shows that IREG generates better REs with the capability of interaction.
GR-GAN: Gradual Refinement Text-to-image Generation
May 23, 2022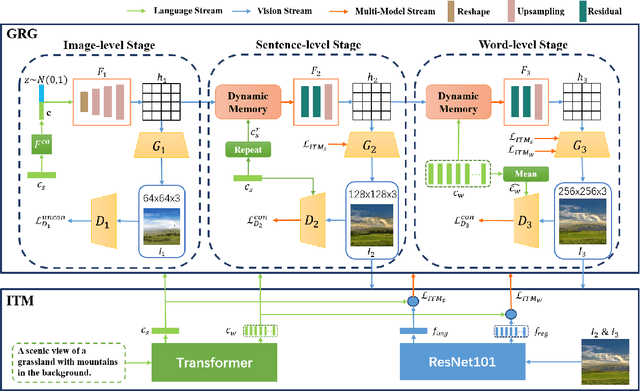
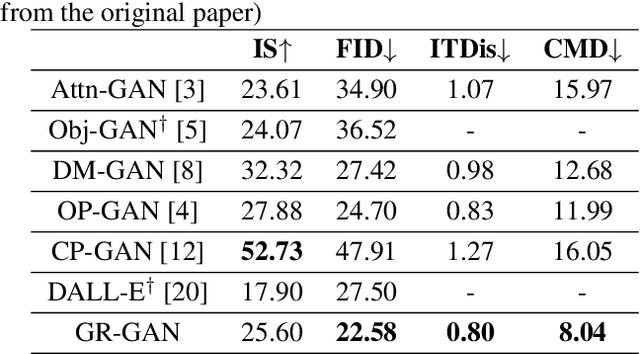

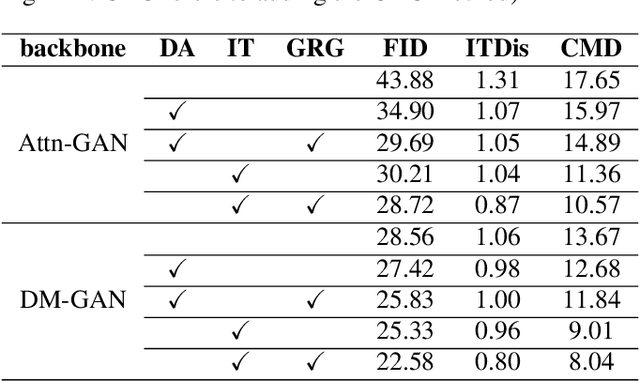
A good Text-to-Image model should not only generate high quality images, but also ensure the consistency between the text and the generated image. Previous models failed to simultaneously fix both sides well. This paper proposes a Gradual Refinement Generative Adversarial Network (GR-GAN) to alleviates the problem efficiently. A GRG module is designed to generate images from low resolution to high resolution with the corresponding text constraints from coarse granularity (sentence) to fine granularity (word) stage by stage, a ITM module is designed to provide image-text matching losses at both sentence-image level and word-region level for corresponding stages. We also introduce a new metric Cross-Model Distance (CMD) for simultaneously evaluating image quality and image-text consistency. Experimental results show GR-GAN significant outperform previous models, and achieve new state-of-the-art on both FID and CMD. A detailed analysis demonstrates the efficiency of different generation stages in GR-GAN.
Question-Driven Graph Fusion Network For Visual Question Answering
Apr 03, 2022
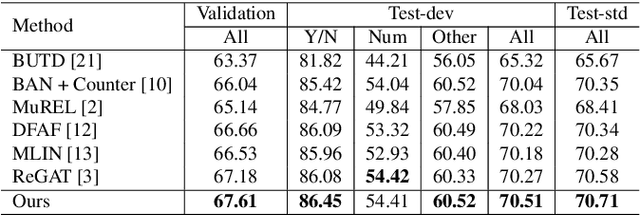
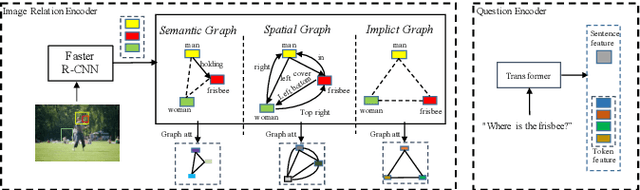
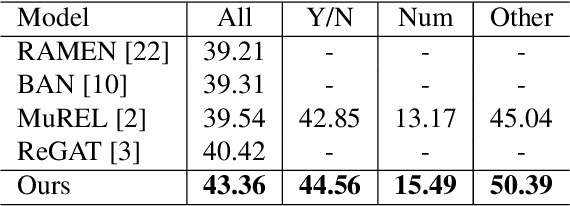
Existing Visual Question Answering (VQA) models have explored various visual relationships between objects in the image to answer complex questions, which inevitably introduces irrelevant information brought by inaccurate object detection and text grounding. To address the problem, we propose a Question-Driven Graph Fusion Network (QD-GFN). It first models semantic, spatial, and implicit visual relations in images by three graph attention networks, then question information is utilized to guide the aggregation process of the three graphs, further, our QD-GFN adopts an object filtering mechanism to remove question-irrelevant objects contained in the image. Experiment results demonstrate that our QD-GFN outperforms the prior state-of-the-art on both VQA 2.0 and VQA-CP v2 datasets. Further analysis shows that both the novel graph aggregation method and object filtering mechanism play a significant role in improving the performance of the model.
Co-VQA : Answering by Interactive Sub Question Sequence
Apr 02, 2022
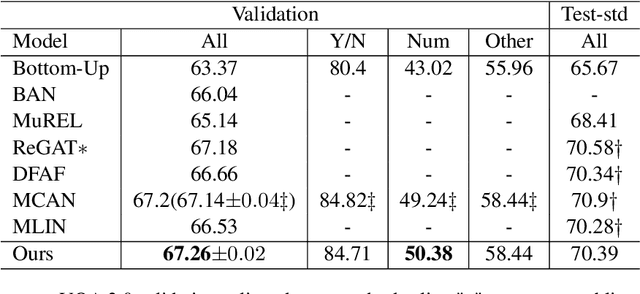
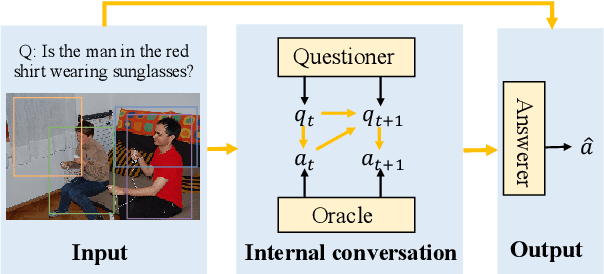
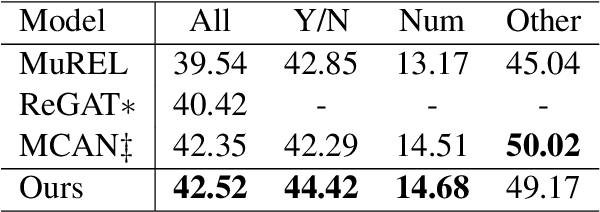
Most existing approaches to Visual Question Answering (VQA) answer questions directly, however, people usually decompose a complex question into a sequence of simple sub questions and finally obtain the answer to the original question after answering the sub question sequence(SQS). By simulating the process, this paper proposes a conversation-based VQA (Co-VQA) framework, which consists of three components: Questioner, Oracle, and Answerer. Questioner raises the sub questions using an extending HRED model, and Oracle answers them one-by-one. An Adaptive Chain Visual Reasoning Model (ACVRM) for Answerer is also proposed, where the question-answer pair is used to update the visual representation sequentially. To perform supervised learning for each model, we introduce a well-designed method to build a SQS for each question on VQA 2.0 and VQA-CP v2 datasets. Experimental results show that our method achieves state-of-the-art on VQA-CP v2. Further analyses show that SQSs help build direct semantic connections between questions and images, provide question-adaptive variable-length reasoning chains, and with explicit interpretability as well as error traceability.
Spot the Difference: A Cooperative Object-Referring Game in Non-Perfectly Co-Observable Scene
Mar 16, 2022


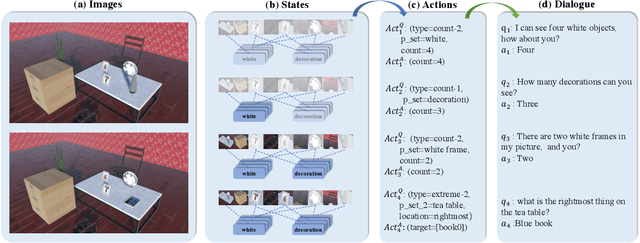
Visual dialog has witnessed great progress after introducing various vision-oriented goals into the conversation, especially such as GuessWhich and GuessWhat, where the only image is visible by either and both of the questioner and the answerer, respectively. Researchers explore more on visual dialog tasks in such kind of single- or perfectly co-observable visual scene, while somewhat neglect the exploration on tasks of non perfectly co-observable visual scene, where the images accessed by two agents may not be exactly the same, often occurred in practice. Although building common ground in non-perfectly co-observable visual scene through conversation is significant for advanced dialog agents, the lack of such dialog task and corresponding large-scale dataset makes it impossible to carry out in-depth research. To break this limitation, we propose an object-referring game in non-perfectly co-observable visual scene, where the goal is to spot the difference between the similar visual scenes through conversing in natural language. The task addresses challenges of the dialog strategy in non-perfectly co-observable visual scene and the ability of categorizing objects. Correspondingly, we construct a large-scale multimodal dataset, named SpotDiff, which contains 87k Virtual Reality images and 97k dialogs generated by self-play. Finally, we give benchmark models for this task, and conduct extensive experiments to evaluate its performance as well as analyze its main challenges.