 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectralCLIP: Preventing Artifacts in Text-Guided Style Transfer from a Spectral Perspective
Mar 16, 2023Contrastive Language-Image Pre-Training (CLIP) has refreshed the state of the art for a broad range of vision-language cross-modal tasks. Particularly, it has created an intriguing research line of text-guided image style transfer, dispensing with the need for style reference images as in traditional style transfer methods. However, directly using CLIP to guide the transfer of style leads to undesirable artifacts (mainly written words and unrelated visual entities) spread over the image, partly due to the entanglement of visual and written concepts inherent in CLIP. Inspired by the use of spectral analysis in filtering linguistic information at different granular levels, we analyse the patch embeddings from the last layer of the CLIP vision encoder from the perspective of spectral analysis and find that the presence of undesirable artifacts is highly correlated to some certain frequency components. We propose SpectralCLIP, which implements a spectral filtering layer on top of the CLIP vision encoder, to alleviate the artifact issue. Experimental results show that SpectralCLIP prevents the generation of artifacts effectively in quantitative and qualitative terms, without impairing the stylisation quality. We further apply SpectralCLIP to text-conditioned image generation and show that it prevents written words in the generated images. Code is available at https://github.com/zipengxuc/SpectralCLIP.
StylerDALLE: Language-Guided Style Transfer Using a Vector-Quantized Tokenizer of a Large-Scale Generative Model
Mar 16, 2023



Despite the progress made in the style transfer task, most previous work focus on transferring only relatively simple features like color or texture, while missing more abstract concepts such as overall art expression or painter-specific traits. However, these abstract semantics can be captured by models like DALL-E or CLIP, which have been trained using huge datasets of images and textual documents. In this paper, we propose StylerDALLE, a style transfer method that exploits both of these models and uses natural language to describe abstract art styles. Specifically, we formulate the language-guided style transfer task as a non-autoregressive token sequence translation, i.e., from input content image to output stylized image, in the discrete latent space of a large-scale pretrained vector-quantized tokenizer. To incorporate style information, we propose a Reinforcement Learning strategy with CLIP-based language supervision that ensures stylization and content preservation simultaneously. Experimental results demonstrate the superiority of our method, which can effectively transfer art styles using language instructions at different granularities. Code is available at https://github.com/zipengxuc/StylerDALLE.
Spot the Difference: A Cooperative Object-Referring Game in Non-Perfectly Co-Observable Scene
Mar 16, 2022


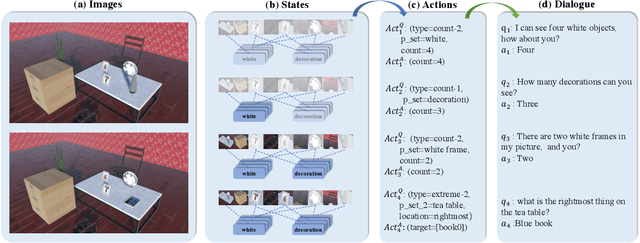
Visual dialog has witnessed great progress after introducing various vision-oriented goals into the conversation, especially such as GuessWhich and GuessWhat, where the only image is visible by either and both of the questioner and the answerer, respectively. Researchers explore more on visual dialog tasks in such kind of single- or perfectly co-observable visual scene, while somewhat neglect the exploration on tasks of non perfectly co-observable visual scene, where the images accessed by two agents may not be exactly the same, often occurred in practice. Although building common ground in non-perfectly co-observable visual scene through conversation is significant for advanced dialog agents, the lack of such dialog task and corresponding large-scale dataset makes it impossible to carry out in-depth research. To break this limitation, we propose an object-referring game in non-perfectly co-observable visual scene, where the goal is to spot the difference between the similar visual scenes through conversing in natural language. The task addresses challenges of the dialog strategy in non-perfectly co-observable visual scene and the ability of categorizing objects. Correspondingly, we construct a large-scale multimodal dataset, named SpotDiff, which contains 87k Virtual Reality images and 97k dialogs generated by self-play. Finally, we give benchmark models for this task, and conduct extensive experiments to evaluate its performance as well as analyze its main challenges.
Predict, Prevent, and Evaluate: Disentangled Text-Driven Image Manipulation Empowered by Pre-Trained Vision-Language Model
Nov 26, 2021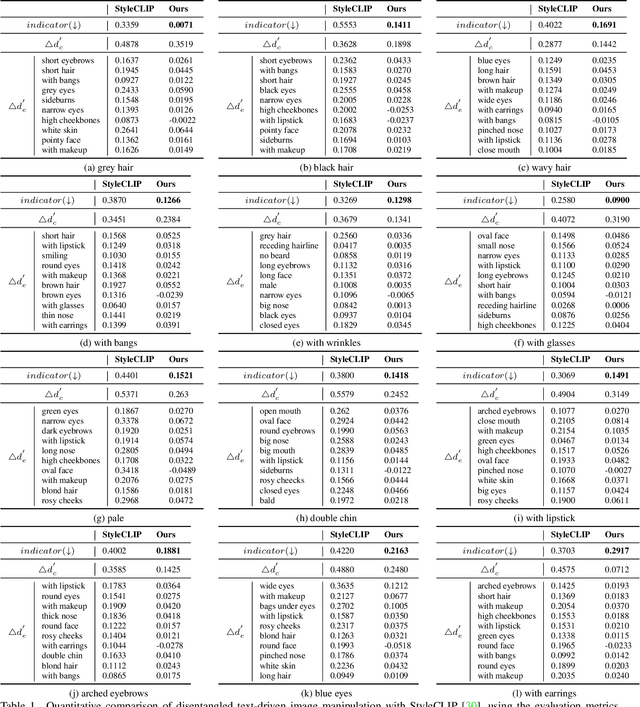
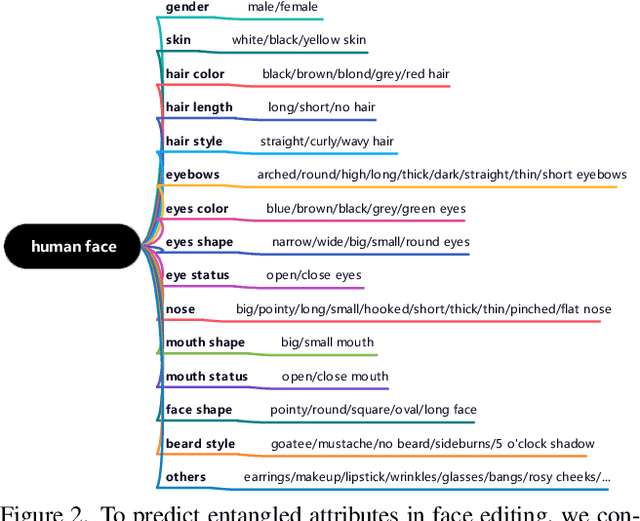
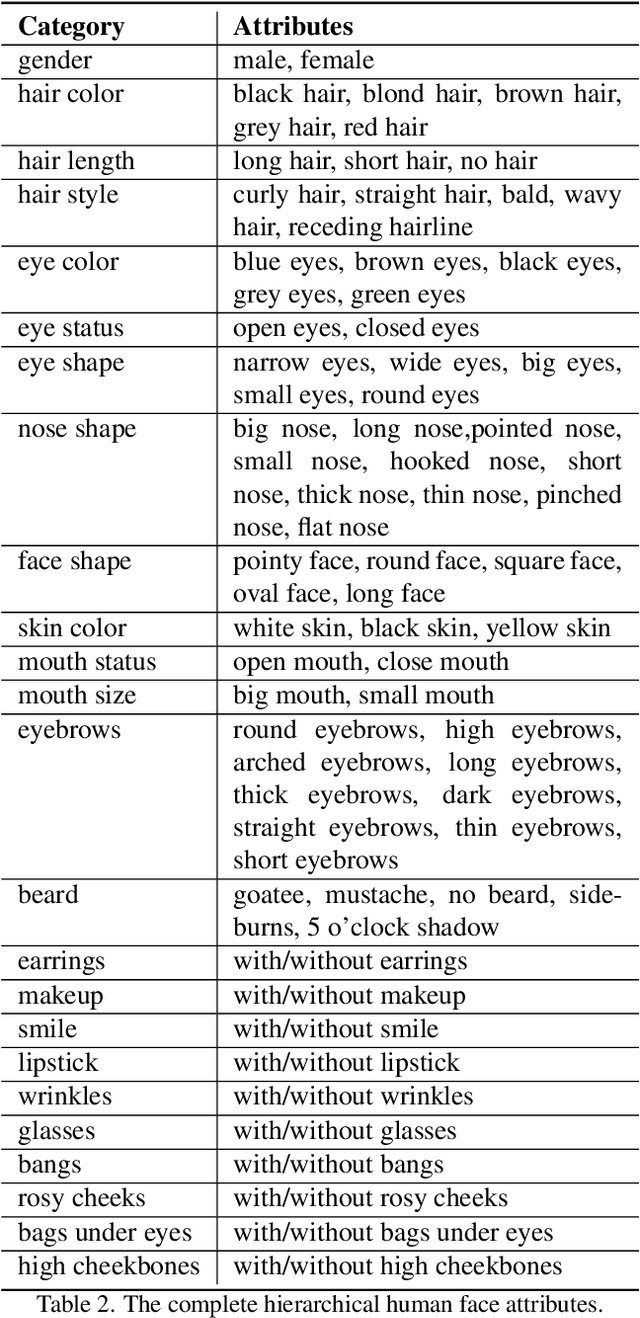

To achieve disentangled image manipulation, previous works depend heavily on manual annotation. Meanwhile, the available manipulations are limited to a pre-defined set the models were trained for. In this paper, we propose a novel framework, i.e., Predict, Prevent, and Evaluate (PPE), for disentangled text-driven image manipulation, which does not need manual annotation and thus is not limited to fixed manipulations. Our method approaches the targets by deeply exploiting the power of the large scale pre-trained vision-language model CLIP. Concretely, we firstly Predict the possibly entangled attributes for a given text command. Then, based on the predicted attributes, we introduce an entanglement loss to Prevent entanglements during training. Finally, we propose a new evaluation metric to Evaluate the disentangled image manipulation. We verify the effectiveness of our method on the challenging face editing task. Extensive experiments show that the proposed PPE framework achieves much better quantitative and qualitative results than the up-to-date StyleCLIP baseline.
Enhancing Visual Dialog Questioner with Entity-based Strategy Learning and Augmented Guesser
Sep 06, 2021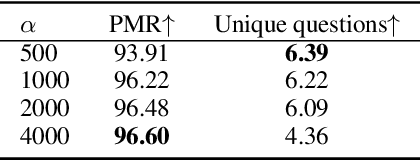
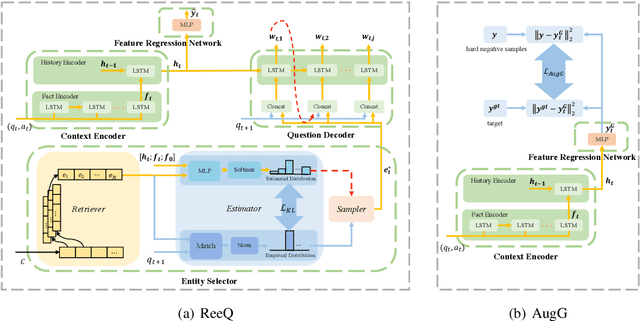
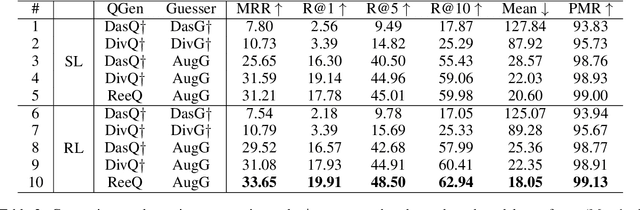
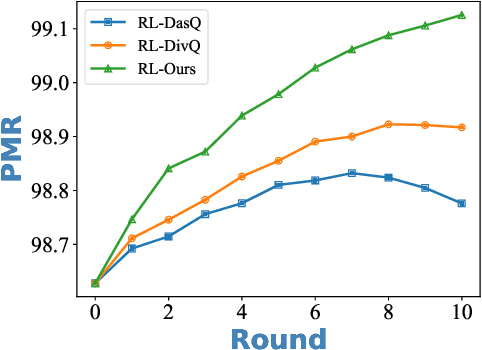
Considering the importance of building a good Visual Dialog (VD) Questioner, many researchers study the topic under a Q-Bot-A-Bot image-guessing game setting, where the Questioner needs to raise a series of questions to collect information of an undisclosed image. Despite progress has been made in Supervised Learning (SL) and Reinforcement Learning (RL), issues still exist. Firstly, previous methods do not provide explicit and effective guidance for Questioner to generate visually related and informative questions. Secondly, the effect of RL is hampered by an incompetent component, i.e., the Guesser, who makes image predictions based on the generated dialogs and assigns rewards accordingly. To enhance VD Questioner: 1) we propose a Related entity enhanced Questioner (ReeQ) that generates questions under the guidance of related entities and learns entity-based questioning strategy from human dialogs; 2) we propose an Augmented Guesser (AugG) that is strong and is optimized for the VD setting especially. Experimental results on the VisDial v1.0 dataset show that our approach achieves state-of-theart performance on both image-guessing task and question diversity. Human study further proves that our model generates more visually related, informative and coherent questions.
Modeling Explicit Concerning States for Reinforcement Learning in Visual Dialogue
Jul 12, 2021

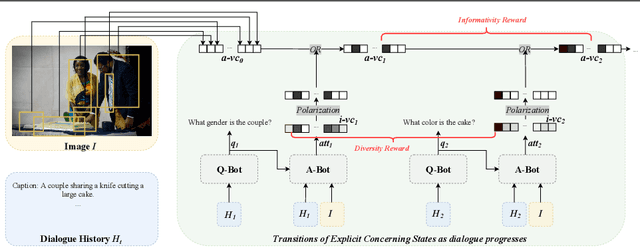

To encourage AI agents to conduct meaningful Visual Dialogue (VD), the use of Reinforcement Learning has been proven potential. In Reinforcement Learning, it is crucial to represent states and assign rewards based on the action-caused transitions of states. However, the state representation in previous Visual Dialogue works uses the textual information only and its transitions are implicit. In this paper, we propose Explicit Concerning States (ECS) to represent what visual contents are concerned at each round and what have been concerned throughout the Visual Dialogue. ECS is modeled from multimodal information and is represented explicitly. Based on ECS, we formulate two intuitive and interpretable rewards to encourage the Visual Dialogue agents to converse on diverse and informative visual information. Experimental results on the VisDial v1.0 dataset show our method enables the Visual Dialogue agents to generate more visual coherent, less repetitive and more visual informative dialogues compared with previous methods, according to multiple automatic metrics, human study and qualitative analysis.
Answer-Driven Visual State Estimator for Goal-Oriented Visual Dialogue
Oct 01, 2020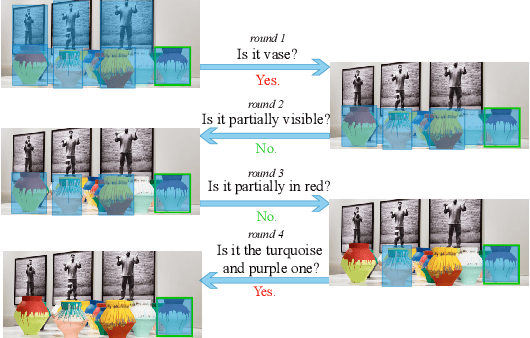
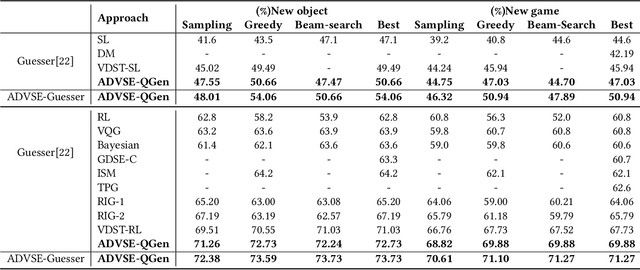
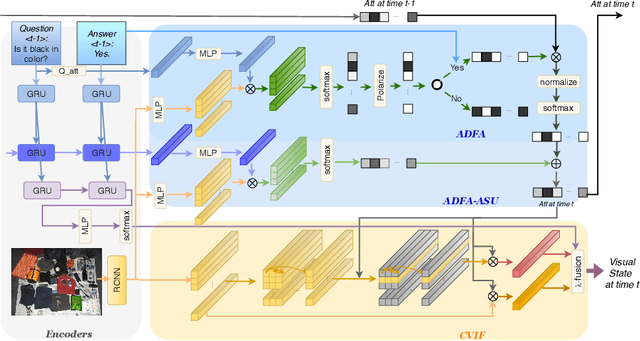
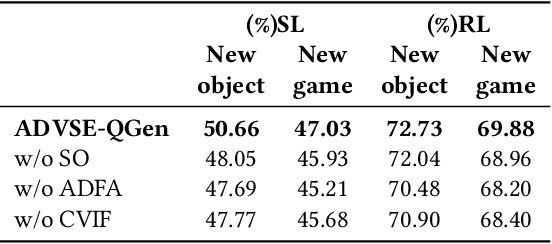
A goal-oriented visual dialogue involves multi-turn interactions between two agents, Questioner and Oracle. During which, the answer given by Oracle is of great significance, as it provides golden response to what Questioner concerns. Based on the answer, Questioner updates its belief on target visual content and further raises another question. Notably, different answers drive into different visual beliefs and future questions. However, existing methods always indiscriminately encode answers after much longer questions, resulting in a weak utilization of answers. In this paper, we propose an Answer-Driven Visual State Estimator (ADVSE) to impose the effects of different answers on visual states. First, we propose an Answer-Driven Focusing Attention (ADFA) to capture the answer-driven effect on visual attention by sharpening question-related attention and adjusting it by answer-based logical operation at each turn. Then based on the focusing attention, we get the visual state estimation by Conditional Visual Information Fusion (CVIF), where overall information and difference information are fused conditioning on the question-answer state. We evaluate the proposed ADVSE to both question generator and guesser tasks on the large-scale GuessWhat?! dataset and achieve the state-of-the-art performances on both tasks. The qualitative results indicate that the ADVSE boosts the agent to generate highly efficient questions and obtains reliable visual attentions during the reasonable question generation and guess processes.