 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Explicit Concerning States for Reinforcement Learning in Visual Dialogue
Paper and Code


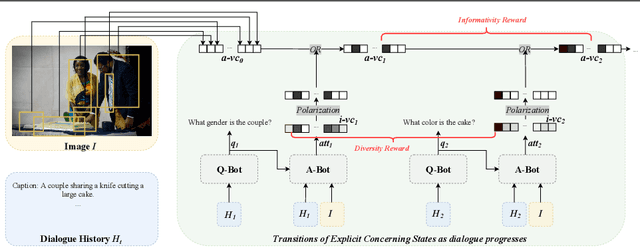

To encourage AI agents to conduct meaningful Visual Dialogue (VD), the use of Reinforcement Learning has been proven potential. In Reinforcement Learning, it is crucial to represent states and assign rewards based on the action-caused transitions of states. However, the state representation in previous Visual Dialogue works uses the textual information only and its transitions are implicit. In this paper, we propose Explicit Concerning States (ECS) to represent what visual contents are concerned at each round and what have been concerned throughout the Visual Dialogue. ECS is modeled from multimodal information and is represented explicitly. Based on ECS, we formulate two intuitive and interpretable rewards to encourage the Visual Dialogue agents to converse on diverse and informative visual information. Experimental results on the VisDial v1.0 dataset show our method enables the Visual Dialogue agents to generate more visual coherent, less repetitive and more visual informative dialogues compared with previous methods, according to multiple automatic metrics, human study and qualitative analysis.