 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepPlanning: Benchmarking Long-Horizon Agentic Planning with Verifiable Constraints
Jan 26, 2026While agent evaluation has shifted toward long-horizon tasks, most benchmarks still emphasize local, step-level reasoning rather than the global constrained optimization (e.g., time and financial budgets) that demands genuine planning ability. Meanwhile, existing LLM planning benchmarks underrepresent the active information gathering and fine-grained local constraints typical of real-world settings. To address this, we introduce DeepPlanning, a challenging benchmark for practical long-horizon agent planning. It features multi-day travel planning and multi-product shopping tasks that require proactive information acquisition, local constrained reasoning, and global constrained optimization. Evaluations on DeepPlanning show that even frontier agentic LLMs struggle with these problems, highlighting the importance of reliable explicit reasoning patterns and parallel tool use for achieving better effectiveness-efficiency trade-offs. Error analysis further points to promising directions for improving agentic LLMs over long planning horizons. We open-source the code and data to support future research.
Qwen3 Technical Report
May 14, 2025



In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models--such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ-32B)--and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0.
Baichuan 2: Open Large-scale Language Models
Sep 20, 2023Large language models (LLMs) have demonstrated remarkable performance on a variety of natural language tasks based on just a few examples of natural language instructions, reducing the need for extensive feature engineering. However, most powerful LLMs are closed-source or limited in their capability for languages other than English. In this technical report, we present Baichuan 2, a series of large-scale multilingual language models containing 7 billion and 13 billion parameters, trained from scratch, on 2.6 trillion tokens. Baichuan 2 matches or outperforms other open-source models of similar size on public benchmarks like MMLU, CMMLU, GSM8K, and HumanEval. Furthermore, Baichuan 2 excels in vertical domains such as medicine and law. We will release all pre-training model checkpoints to benefit the research community in better understanding the training dynamics of Baichuan 2.
A Low-Cost, Controllable and Interpretable Task-Oriented Chatbot: With Real-World After-Sale Services as Example
May 13, 2022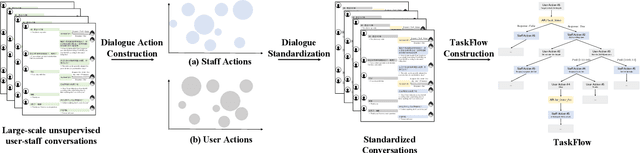
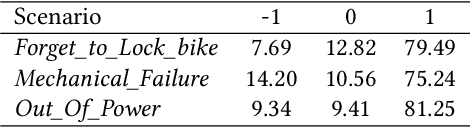
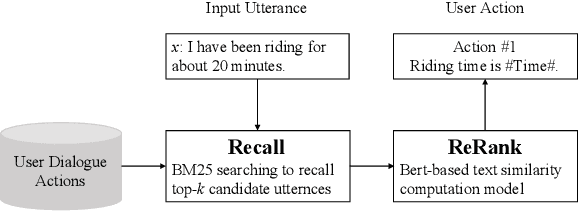
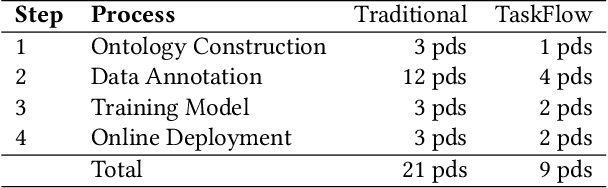
Though widely used in industry, traditional task-oriented dialogue systems suffer from three bottlenecks: (i) difficult ontology construction (e.g., intents and slots); (ii) poor controllability and interpretability; (iii) annotation-hungry. In this paper, we propose to represent utterance with a simpler concept named Dialogue Action, upon which we construct a tree-structured TaskFlow and further build task-oriented chatbot with TaskFlow as core component. A framework is presented to automatically construct TaskFlow from large-scale dialogues and deploy online. Our experiments on real-world after-sale customer services show TaskFlow can satisfy the major needs, as well as reduce the developer burden effectively.
Modeling Explicit Concerning States for Reinforcement Learning in Visual Dialogue
Jul 12, 2021

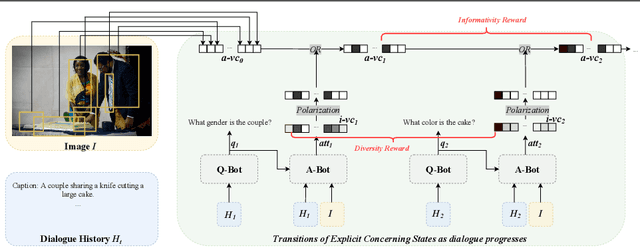

To encourage AI agents to conduct meaningful Visual Dialogue (VD), the use of Reinforcement Learning has been proven potential. In Reinforcement Learning, it is crucial to represent states and assign rewards based on the action-caused transitions of states. However, the state representation in previous Visual Dialogue works uses the textual information only and its transitions are implicit. In this paper, we propose Explicit Concerning States (ECS) to represent what visual contents are concerned at each round and what have been concerned throughout the Visual Dialogue. ECS is modeled from multimodal information and is represented explicitly. Based on ECS, we formulate two intuitive and interpretable rewards to encourage the Visual Dialogue agents to converse on diverse and informative visual information. Experimental results on the VisDial v1.0 dataset show our method enables the Visual Dialogue agents to generate more visual coherent, less repetitive and more visual informative dialogues compared with previous methods, according to multiple automatic metrics, human study and qualitative analysis.