 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausality-Inspired Safe Residual Correction for Multivariate Time Series
Dec 27, 2025While modern multivariate forecasters such as Transformers and GNNs achieve strong benchmark performance, they often suffer from systematic errors at specific variables or horizons and, critically, lack guarantees against performance degradation in deployment. Existing post-hoc residual correction methods attempt to fix these errors, but are inherently greedy: although they may improve average accuracy, they can also "help in the wrong way" by overcorrecting reliable predictions and causing local failures in unseen scenarios. To address this critical "safety gap," we propose CRC (Causality-inspired Safe Residual Correction), a plug-and-play framework explicitly designed to ensure non-degradation. CRC follows a divide-and-conquer philosophy: it employs a causality-inspired encoder to expose direction-aware structure by decoupling self- and cross-variable dynamics, and a hybrid corrector to model residual errors. Crucially, the correction process is governed by a strict four-fold safety mechanism that prevents harmful updates. Experiments across multiple datasets and forecasting backbones show that CRC consistently improves accuracy, while an in-depth ablation study confirms that its core safety mechanisms ensure exceptionally high non-degradation rates (NDR), making CRC a correction framework suited for safe and reliable deployment.
After Retrieval, Before Generation: Enhancing the Trustworthiness of Large Language Models in RAG
May 21, 2025



Retrieval-augmented generation (RAG) systems face critical challenges in balancing internal (parametric) and external (retrieved) knowledge, especially when these sources conflict or are unreliable. To analyze these scenarios comprehensively, we construct the Trustworthiness Response Dataset (TRD) with 36,266 questions spanning four RAG settings. We reveal that existing approaches address isolated scenarios-prioritizing one knowledge source, naively merging both, or refusing answers-but lack a unified framework to handle different real-world conditions simultaneously. Therefore, we propose the BRIDGE framework, which dynamically determines a comprehensive response strategy of large language models (LLMs). BRIDGE leverages an adaptive weighting mechanism named soft bias to guide knowledge collection, followed by a Maximum Soft-bias Decision Tree to evaluate knowledge and select optimal response strategies (trust internal/external knowledge, or refuse). Experiments show BRIDGE outperforms baselines by 5-15% in accuracy while maintaining balanced performance across all scenarios. Our work provides an effective solution for LLMs' trustworthy responses in real-world RAG applications.
SOCIA: An End-to-End Agentic Framework for Automated Cyber-Physical-Social Simulator Generation
May 17, 2025This paper introduces SOCIA (Simulation Orchestration for Cyber-physical-social Intelligence and Agents), a novel end-to-end framework leveraging Large Language Model (LLM)-based multi-agent systems to automate the generation of high-fidelity Cyber-Physical-Social (CPS) simulators. Addressing the challenges of labor-intensive manual simulator development and complex data calibration, SOCIA integrates a centralized orchestration manager that coordinates specialized agents for tasks including data comprehension, code generation, simulation execution, and iterative evaluation-feedback loops. Through empirical evaluations across diverse CPS tasks, such as mask adoption behavior simulation (social), personal mobility generation (physical), and user modeling (cyber), SOCIA demonstrates its ability to produce high-fidelity, scalable simulations with reduced human intervention. These results highlight SOCIA's potential to offer a scalable solution for studying complex CPS phenomena
RIDE: Enhancing Large Language Model Alignment through Restyled In-Context Learning Demonstration Exemplars
Feb 20, 2025Alignment tuning is crucial for ensuring large language models (LLMs) behave ethically and helpfully. Current alignment approaches require high-quality annotations and significant training resources. This paper proposes a low-cost, tuning-free method using in-context learning (ICL) to enhance LLM alignment. Through an analysis of high-quality ICL demos, we identified style as a key factor influencing LLM alignment capabilities and explicitly restyled ICL exemplars based on this stylistic framework. Additionally, we combined the restyled demos to achieve a balance between the two conflicting aspects of LLM alignment--factuality and safety. We packaged the restyled examples as prompts to trigger few-shot learning, improving LLM alignment. Compared to the best baseline approach, with an average score of 5.00 as the maximum, our method achieves a maximum 0.10 increase on the Alpaca task (from 4.50 to 4.60), a 0.22 enhancement on the Just-eval benchmark (from 4.34 to 4.56), and a maximum improvement of 0.32 (from 3.53 to 3.85) on the MT-Bench dataset. We release the code and data at https://github.com/AnonymousCode-ComputerScience/RIDE.
ACCESS : A Benchmark for Abstract Causal Event Discovery and Reasoning
Feb 12, 2025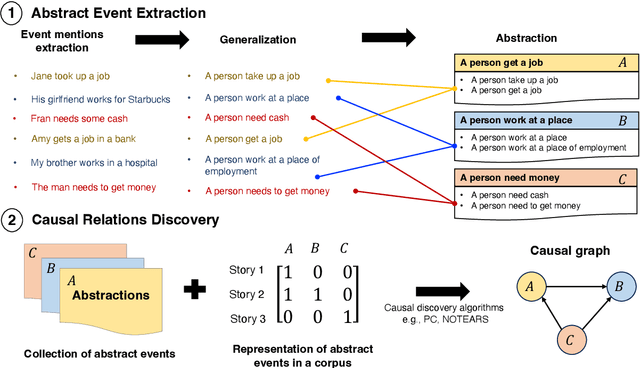

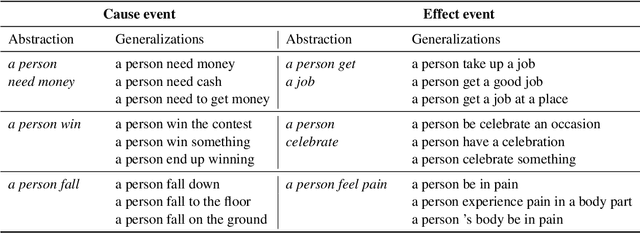
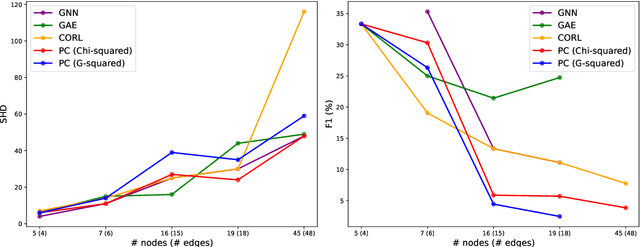
Identifying cause-and-effect relationships is critical to understanding real-world dynamics and ultimately causal reasoning. Existing methods for identifying event causality in NLP, including those based on Large Language Models (LLMs), exhibit difficulties in out-of-distribution settings due to the limited scale and heavy reliance on lexical cues within available benchmarks. Modern benchmarks, inspired by probabilistic causal inference, have attempted to construct causal graphs of events as a robust representation of causal knowledge, where \texttt{CRAB} \citep{romanou2023crab} is one such recent benchmark along this line. In this paper, we introduce \texttt{ACCESS}, a benchmark designed for discovery and reasoning over abstract causal events. Unlike existing resources, \texttt{ACCESS} focuses on causality of everyday life events on the abstraction level. We propose a pipeline for identifying abstractions for event generalizations from \texttt{GLUCOSE} \citep{mostafazadeh-etal-2020-glucose}, a large-scale dataset of implicit commonsense causal knowledge, from which we subsequently extract $1,4$K causal pairs. Our experiments highlight the ongoing challenges of using statistical methods and/or LLMs for automatic abstraction identification and causal discovery in NLP. Nonetheless, we demonstrate that the abstract causal knowledge provided in \texttt{ACCESS} can be leveraged for enhancing QA reasoning performance in LLMs.
CoTKR: Chain-of-Thought Enhanced Knowledge Rewriting for Complex Knowledge Graph Question Answering
Sep 29, 2024



Recent studies have explored the use of Large Language Models (LLMs) with Retrieval Augmented Generation (RAG) for Knowledge Graph Question Answering (KGQA). They typically require rewriting retrieved subgraphs into natural language formats comprehensible to LLMs. However, when tackling complex questions, the knowledge rewritten by existing methods may include irrelevant information, omit crucial details, or fail to align with the question's semantics. To address them, we propose a novel rewriting method CoTKR, Chain-of-Thought Enhanced Knowledge Rewriting, for generating reasoning traces and corresponding knowledge in an interleaved manner, thereby mitigating the limitations of single-step knowledge rewriting. Additionally, to bridge the preference gap between the knowledge rewriter and the question answering (QA) model, we propose a training strategy PAQAF, Preference Alignment from Question Answering Feedback, for leveraging feedback from the QA model to further optimize the knowledge rewriter. We conduct experiments using various LLMs across several KGQA benchmarks. Experimental results demonstrate that, compared with previous knowledge rewriting methods, CoTKR generates the most beneficial knowledge representation for QA models, which significantly improves the performance of LLMs in KGQA.
Causal Discovery Inspired Unsupervised Domain Adaptation for Emotion-Cause Pair Extraction
Jun 18, 2024
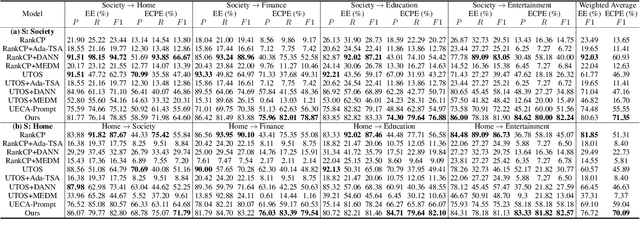
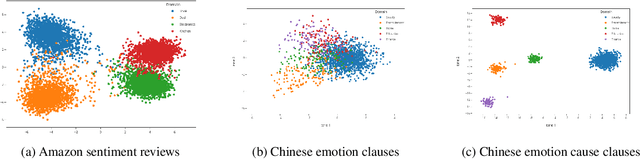
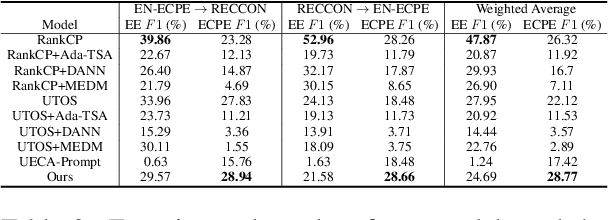
This paper tackles the task of emotion-cause pair extraction in the unsupervised domain adaptation setting. The problem is challenging as the distributions of the events causing emotions in target domains are dramatically different than those in source domains, despite the distributions of emotional expressions between domains are overlapped. Inspired by causal discovery, we propose a novel deep latent model in the variational autoencoder (VAE) framework, which not only captures the underlying latent structures of data but also utilizes the easily transferable knowledge of emotions as the bridge to link the distributions of events in different domains. To facilitate knowledge transfer across domains, we also propose a novel variational posterior regularization technique to disentangle the latent representations of emotions from those of events in order to mitigate the damage caused by the spurious correlations related to the events in source domains. Through extensive experiments, we demonstrate that our model outperforms the strongest baseline by approximately 11.05% on a Chinese benchmark and 2.45% on a English benchmark in terms of weighted-average F1 score. The source code will be publicly available upon acceptance.
SCAR: Efficient Instruction-Tuning for Large Language Models via Style Consistency-Aware Response Ranking
Jun 16, 2024



Recent studies have shown that maintaining a consistent response style by human experts and enhancing data quality in training sets can significantly improve the performance of fine-tuned Large Language Models (LLMs) while reducing the number of training examples needed. However, the precise definition of style and the relationship between style, data quality, and LLM performance remains unclear. This research decomposes response style into presentation and composition styles and finds that, among training data of similar quality, those with higher style consistency lead to better LLM performance. Inspired by this, we introduce Style Consistency-Aware Response Ranking (SCAR), which automatically prioritizes instruction-response pairs in the training set based on their response stylistic consistency. By selecting the most style-consistent examples, ranging from the top 25% to 0.7% of the full dataset, the fine-tuned LLMs can match or even surpass the performance of models trained on the entire dataset in coding and open-ended question-answering benchmarks. Code and data are available at https://github.com/zhuang-li/SCAR .
IMO: Greedy Layer-Wise Sparse Representation Learning for Out-of-Distribution Text Classification with Pre-trained Models
Apr 21, 2024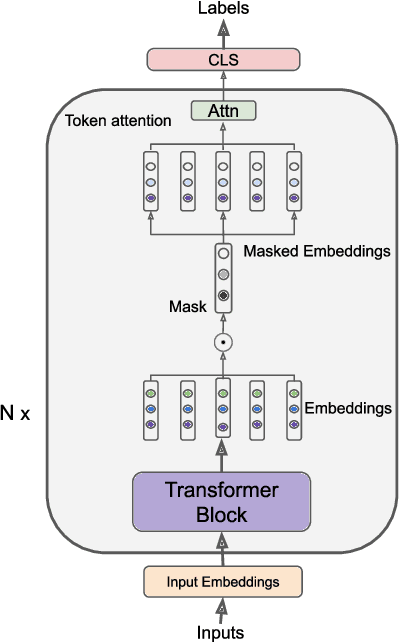
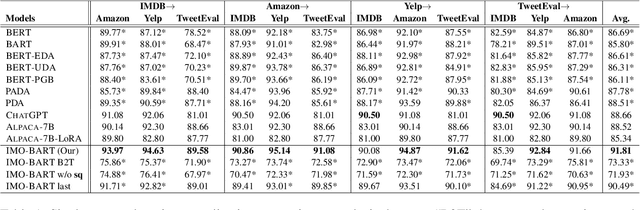
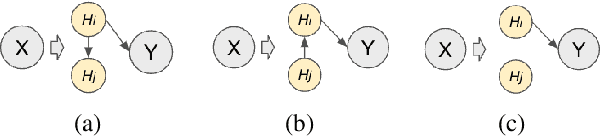
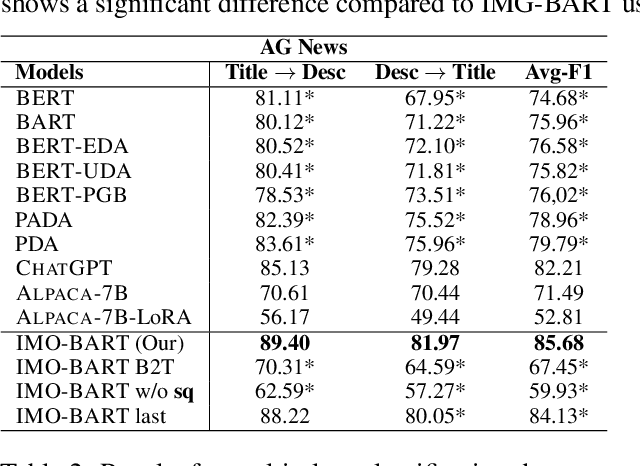
Machine learning models have made incredible progress, but they still struggle when applied to examples from unseen domains. This study focuses on a specific problem of domain generalization, where a model is trained on one source domain and tested on multiple target domains that are unseen during training. We propose IMO: Invariant features Masks for Out-of-Distribution text classification, to achieve OOD generalization by learning invariant features. During training, IMO would learn sparse mask layers to remove irrelevant features for prediction, where the remaining features keep invariant. Additionally, IMO has an attention module at the token level to focus on tokens that are useful for prediction. Our comprehensive experiments show that IMO substantially outperforms strong baselines in terms of various evaluation metrics and settings.
Counter-intuitive: Large Language Models Can Better Understand Knowledge Graphs Than We Thought
Feb 18, 2024Although the method of enhancing large language models' (LLMs') reasoning ability and reducing their hallucinations through the use of knowledge graphs (KGs) has received widespread attention, the exploration of how to enable LLMs to integrate the structured knowledge in KGs on-the-fly remains inadequate. Researchers often co-train KG embeddings and LLM parameters to equip LLMs with the ability of comprehending KG knowledge. However, this resource-hungry training paradigm significantly increases the model learning cost and is also unsuitable for non-open-source, black-box LLMs. In this paper, we employ complex question answering (CQA) as a task to assess the LLM's ability of comprehending KG knowledge. We conducted a comprehensive comparison of KG knowledge injection methods (from triples to natural language text), aiming to explore the optimal prompting method for supplying KG knowledge to LLMs, thereby enhancing their comprehension of KG. Contrary to our initial expectations, our analysis revealed that LLMs effectively handle messy, noisy, and linearized KG knowledge, outperforming methods that employ well-designed natural language (NL) textual prompts. This counter-intuitive finding provides substantial insights for future research on LLMs' comprehension of structured knowledge.