 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeETCHR: Editing To Clarify and Harness Reasoning
May 22, 2026Multimodal Large Language Models have advanced visual reasoning, yet a purely textual chain of thought remains a bottleneck for questions that require fine-grained focus or view transformations. The ''think with images'' paradigm narrows this gap, but existing approaches are either constrained by fixed predefined toolkits or produce noisy intermediate images from unified multimodal methods. We pursue a third option: using a dedicated image editing model and decouple it with an understanding model. However, off-the-shelf image editors fail as reasoning assistants with two complementary gaps: a language-side gap, where editors trained as passive instruction-followers cannot map an abstract question to an appropriate visual transformation, and a generation-side gap, where edit correctness degrades as reasoning depth grows. Guided by this analysis, we introduce ETCHR (Editing To Clarify and Harness Reasoning), a question-conditioned, reasoning-aware image editor decoupled from the downstream understanding model and trained with a two-stage recipe targeted at the two gaps: Reasoning Imitation via supervised fine-tuning on edit trajectories, followed by Reasoning Enhancement with VLM-derived rewards for edit correctness and downstream reasoning accuracy. Since the editor is decoupled, ETCHR plugs into different open- and closed-source MLLMs in a training-free manner. Across five task families (fine-grained perception, chart understanding, logic reasoning, jigsaw restoration, and 3D understanding), ETCHR raises average Pass@1 from 55.95 to 60.77 (+4.82) with Qwen3-VL-8B, from 65.08 to 70.55 (+5.47) with Gemini-3.1-Flash-Lite, and from 76.55 to 81.16 (+4.61) with the 1T-parameter MoE model Kimi K2.5.
STAND: Semantic Anchoring Constraint with Dual-Granularity Disambiguation for Remote Sensing Image Change Captioning
Apr 25, 2026Remote sensing image change captioning (RSICC) aims to describe the difference between two remote sensing images. While recent methods have explored video modeling, they largely overlook the inherent ambiguities in viewpoint, scale, and prior knowledge, lacking effective constraints on the encoder. In this paper, we present STAND, a Semantic Anchoring Constraint with Dual-Granularity Disambiguation for RSICC, to progressively resolve these ambiguities. Specifically, to establish a reliable feature foundation, we first introduce an interpretable constraint to regularize temporal representations. Operating on these purified features, a dual-granularity disambiguation module resolves spatial uncertainties by coupling macro-level global context aggregation for viewpoint confusion with micro-level frequency-refocused attention for small-object scale enhancement. Ultimately, to translate these visually disambiguated features into precise text, a semantic concept anchoring module leverages language categorical priors to tackle knowledge ambiguity during decoding. Extensive experiments verify the superiority of STAND and its effectiveness in addressing ambiguities.
EndoCoT: Scaling Endogenous Chain-of-Thought Reasoning in Diffusion Models
Mar 12, 2026Recently, Multimodal Large Language Models (MLLMs) have been widely integrated into diffusion frameworks primarily as text encoders to tackle complex tasks such as spatial reasoning. However, this paradigm suffers from two critical limitations: (i) MLLMs text encoder exhibits insufficient reasoning depth. Single-step encoding fails to activate the Chain-of-Thought process, which is essential for MLLMs to provide accurate guidance for complex tasks. (ii) The guidance remains invariant during the decoding process. Invariant guidance during decoding prevents DiT from progressively decomposing complex instructions into actionable denoising steps, even with correct MLLM encodings. To this end, we propose Endogenous Chain-of-Thought (EndoCoT), a novel framework that first activates MLLMs' reasoning potential by iteratively refining latent thought states through an iterative thought guidance module, and then bridges these states to the DiT's denoising process. Second, a terminal thought grounding module is applied to ensure the reasoning trajectory remains grounded in textual supervision by aligning the final state with ground-truth answers. With these two components, the MLLM text encoder delivers meticulously reasoned guidance, enabling the DiT to execute it progressively and ultimately solve complex tasks in a step-by-step manner. Extensive evaluations across diverse benchmarks (e.g., Maze, TSP, VSP, and Sudoku) achieve an average accuracy of 92.1%, outperforming the strongest baseline by 8.3 percentage points.
Think Visually, Reason Textually: Vision-Language Synergy in ARC
Nov 19, 2025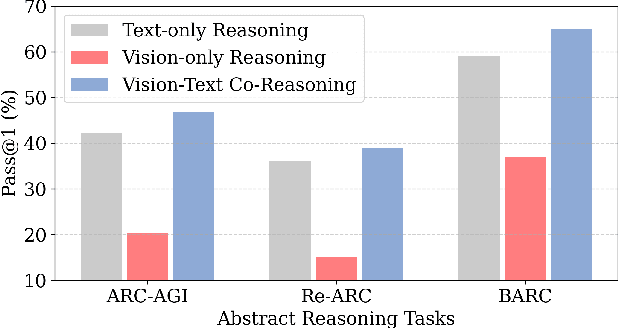
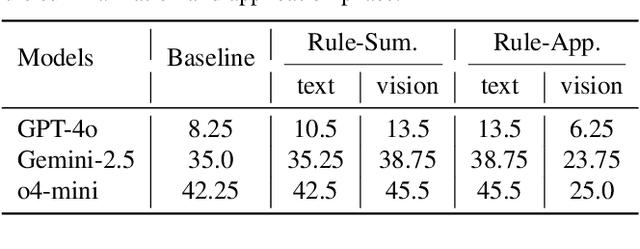

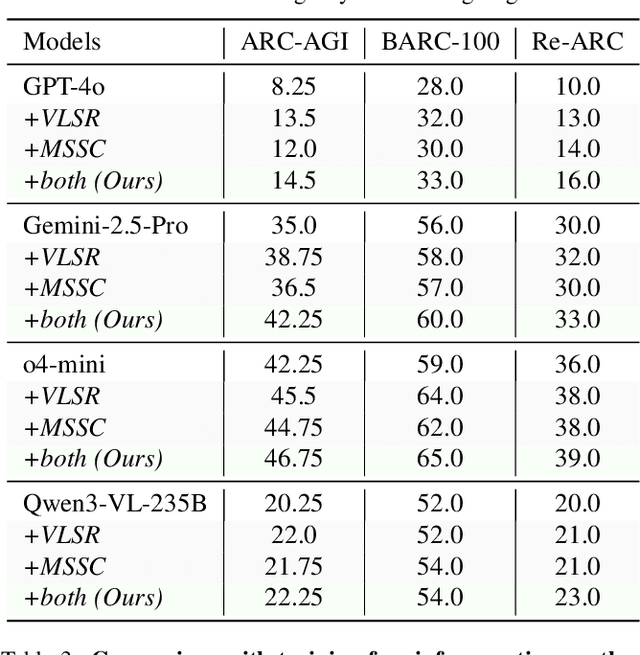
Abstract reasoning from minimal examples remains a core unsolved problem for frontier foundation models such as GPT-5 and Grok 4. These models still fail to infer structured transformation rules from a handful of examples, which is a key hallmark of human intelligence. The Abstraction and Reasoning Corpus for Artificial General Intelligence (ARC-AGI) provides a rigorous testbed for this capability, demanding conceptual rule induction and transfer to novel tasks. Most existing methods treat ARC-AGI as a purely textual reasoning task, overlooking the fact that humans rely heavily on visual abstraction when solving such puzzles. However, our pilot experiments reveal a paradox: naively rendering ARC-AGI grids as images degrades performance due to imprecise rule execution. This leads to our central hypothesis that vision and language possess complementary strengths across distinct reasoning stages: vision supports global pattern abstraction and verification, whereas language specializes in symbolic rule formulation and precise execution. Building on this insight, we introduce two synergistic strategies: (1) Vision-Language Synergy Reasoning (VLSR), which decomposes ARC-AGI into modality-aligned subtasks; and (2) Modality-Switch Self-Correction (MSSC), which leverages vision to verify text-based reasoning for intrinsic error correction. Extensive experiments demonstrate that our approach yields up to a 4.33% improvement over text-only baselines across diverse flagship models and multiple ARC-AGI tasks. Our findings suggest that unifying visual abstraction with linguistic reasoning is a crucial step toward achieving generalizable, human-like intelligence in future foundation models. Source code will be released soon.
Coupling Agent-based Modeling and Life Cycle Assessment to Analyze Trade-offs in Resilient Energy Transitions
Nov 10, 2025


Transitioning to sustainable and resilient energy systems requires navigating complex and interdependent trade-offs across environmental, social, and resource dimensions. Neglecting these trade-offs can lead to unintended consequences across sectors. However, existing assessments often evaluate emerging energy pathways and their impacts in silos, overlooking critical interactions such as regional resource competition and cumulative impacts. We present an integrated modeling framework that couples agent-based modeling and Life Cycle Assessment (LCA) to simulate how energy transition pathways interact with regional resource competition, ecological constraints, and community-level burdens. We apply the model to a case study in Southern California. The results demonstrate how integrated and multiscale decision making can shape energy pathway deployment and reveal spatially explicit trade-offs under scenario-driven constraints. This modeling framework can further support more adaptive and resilient energy transition planning on spatial and institutional scales.
Spatial-SSRL: Enhancing Spatial Understanding via Self-Supervised Reinforcement Learning
Oct 31, 2025Spatial understanding remains a weakness of Large Vision-Language Models (LVLMs). Existing supervised fine-tuning (SFT) and recent reinforcement learning with verifiable rewards (RLVR) pipelines depend on costly supervision, specialized tools, or constrained environments that limit scale. We introduce Spatial-SSRL, a self-supervised RL paradigm that derives verifiable signals directly from ordinary RGB or RGB-D images. Spatial-SSRL automatically formulates five pretext tasks that capture 2D and 3D spatial structure: shuffled patch reordering, flipped patch recognition, cropped patch inpainting, regional depth ordering, and relative 3D position prediction. These tasks provide ground-truth answers that are easy to verify and require no human or LVLM annotation. Training on our tasks substantially improves spatial reasoning while preserving general visual capabilities. On seven spatial understanding benchmarks in both image and video settings, Spatial-SSRL delivers average accuracy gains of 4.63% (3B) and 3.89% (7B) over the Qwen2.5-VL baselines. Our results show that simple, intrinsic supervision enables RLVR at scale and provides a practical route to stronger spatial intelligence in LVLMs.
From Trial-and-Error to Improvement: A Systematic Analysis of LLM Exploration Mechanisms in RLVR
Aug 11, 2025Reinforcement learning with verifiable rewards (RLVR) has emerged as a powerful paradigm for enhancing the reasoning capabilities of large language models (LLMs). Unlike traditional RL approaches, RLVR leverages rule-based feedback to guide LLMs in generating and refining complex reasoning chains -- a process critically dependent on effective exploration strategies. While prior work has demonstrated RLVR's empirical success, the fundamental mechanisms governing LLMs' exploration behaviors remain underexplored. This technical report presents a systematic investigation of exploration capacities in RLVR, covering four main aspects: (1) exploration space shaping, where we develop quantitative metrics to characterize LLMs' capability boundaries; (2) entropy-performance exchange, analyzed across training stages, individual instances, and token-level patterns; and (3) RL performance optimization, examining methods to effectively translate exploration gains into measurable improvements. By unifying previously identified insights with new empirical evidence, this work aims to provide a foundational framework for advancing RLVR systems.
Towards Effective Code-Integrated Reasoning
May 30, 2025In this paper, we investigate code-integrated reasoning, where models generate code when necessary and integrate feedback by executing it through a code interpreter. To acquire this capability, models must learn when and how to use external code tools effectively, which is supported by tool-augmented reinforcement learning (RL) through interactive learning. Despite its benefits, tool-augmented RL can still suffer from potential instability in the learning dynamics. In light of this challenge, we present a systematic approach to improving the training effectiveness and stability of tool-augmented RL for code-integrated reasoning. Specifically, we develop enhanced training strategies that balance exploration and stability, progressively building tool-use capabilities while improving reasoning performance. Through extensive experiments on five mainstream mathematical reasoning benchmarks, our model demonstrates significant performance improvements over multiple competitive baselines. Furthermore, we conduct an in-depth analysis of the mechanism and effect of code-integrated reasoning, revealing several key insights, such as the extension of model's capability boundaries and the simultaneous improvement of reasoning efficiency through code integration. All data and code for reproducing this work are available at: https://github.com/RUCAIBox/CIR.
Qwen3 Technical Report
May 14, 2025



In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models--such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ-32B)--and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0.
Slow Thinking for Sequential Recommendation
Apr 13, 2025To develop effective sequential recommender systems, numerous methods have been proposed to model historical user behaviors. Despite the effectiveness, these methods share the same fast thinking paradigm. That is, for making recommendations, these methods typically encodes user historical interactions to obtain user representations and directly match these representations with candidate item representations. However, due to the limited capacity of traditional lightweight recommendation models, this one-step inference paradigm often leads to suboptimal performance. To tackle this issue, we present a novel slow thinking recommendation model, named STREAM-Rec. Our approach is capable of analyzing historical user behavior, generating a multi-step, deliberative reasoning process, and ultimately delivering personalized recommendations. In particular, we focus on two key challenges: (1) identifying the suitable reasoning patterns in recommender systems, and (2) exploring how to effectively stimulate the reasoning capabilities of traditional recommenders. To this end, we introduce a three-stage training framework. In the first stage, the model is pretrained on large-scale user behavior data to learn behavior patterns and capture long-range dependencies. In the second stage, we design an iterative inference algorithm to annotate suitable reasoning traces by progressively refining the model predictions. This annotated data is then used to fine-tune the model. Finally, in the third stage, we apply reinforcement learning to further enhance the model generalization ability. Extensive experiments validate the effectiveness of our proposed method.