 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn Hard Problems During RL with Reference Guided Fine-tuning
Mar 05, 2026Reinforcement learning (RL) for mathematical reasoning can suffer from reward sparsity: for challenging problems, LLM fails to sample any correct trajectories, preventing RL from receiving meaningful positive feedback. At the same time, there often exist human-written reference solutions along with the problem (e.g., problems from AoPS), but directly fine-tuning on these solutions offers no benefit because models often cannot imitate human proofs that lie outside their own reasoning distribution. We introduce Reference-Guided Fine-Tuning (ReGFT), a simple and effective method that utilizes human-written reference solutions to synthesize positive trajectories on hard problems and train on them before RL. For each problem, we provide the model with a partial reference solution and let it generate its own reasoning trace, ensuring the resulting trajectories remain in the model's reasoning space while still benefiting from reference guidance. Fine-tuning on these reference-guided trajectories increases the number of solvable problems and produces a checkpoint that receives more positive rewards during RL. Across three benchmarks (AIME24, AIME25, BeyondAIME), ReGFT consistently improves supervised accuracy, accelerates DAPO training, and raises the final performance plateau of RL. Our results show that ReGFT effectively overcomes reward sparsity and unlocks stronger RL-based mathematical reasoning.
The Lessons of Developing Process Reward Models in Mathematical Reasoning
Jan 13, 2025



Process Reward Models (PRMs) emerge as a promising approach for process supervision in mathematical reasoning of Large Language Models (LLMs), which aim to identify and mitigate intermediate errors in the reasoning processes. However, the development of effective PRMs faces significant challenges, particularly in data annotation and evaluation methodologies. In this paper, through extensive experiments, we demonstrate that commonly used Monte Carlo (MC) estimation-based data synthesis for PRMs typically yields inferior performance and generalization compared to LLM-as-a-judge and human annotation methods. MC estimation relies on completion models to evaluate current-step correctness, leading to inaccurate step verification. Furthermore, we identify potential biases in conventional Best-of-N (BoN) evaluation strategies for PRMs: (1) The unreliable policy models generate responses with correct answers but flawed processes, leading to a misalignment between the evaluation criteria of BoN and the PRM objectives of process verification. (2) The tolerance of PRMs of such responses leads to inflated BoN scores. (3) Existing PRMs have a significant proportion of minimum scores concentrated on the final answer steps, revealing the shift from process to outcome-based assessment in BoN Optimized PRMs. To address these challenges, we develop a consensus filtering mechanism that effectively integrates MC estimation with LLM-as-a-judge and advocates a more comprehensive evaluation framework that combines response-level and step-level metrics. Based on the mechanisms, we significantly improve both model performance and data efficiency in the BoN evaluation and the step-wise error identification task. Finally, we release a new state-of-the-art PRM that outperforms existing open-source alternatives and provides practical guidelines for future research in building process supervision models.
An Empirical Analysis of Compute-Optimal Inference for Problem-Solving with Language Models
Aug 01, 2024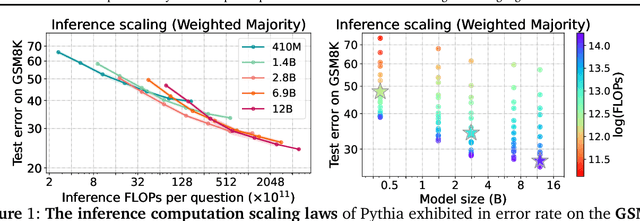
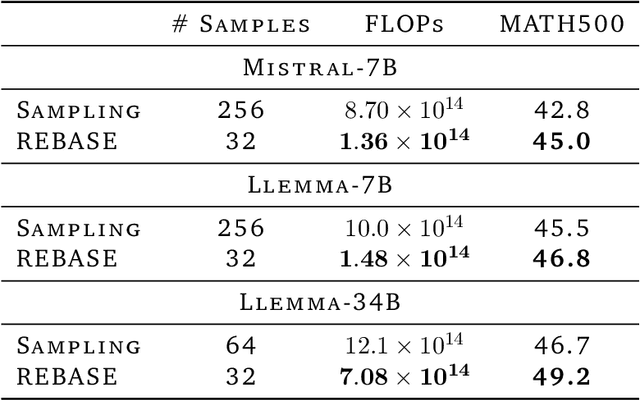
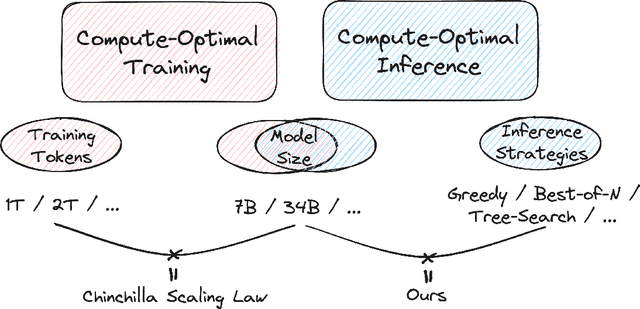
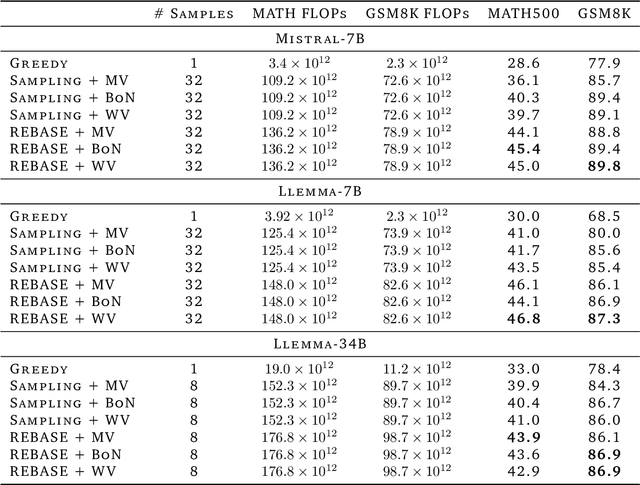
The optimal training configurations of large language models (LLMs) with respect to model sizes and compute budgets have been extensively studied. But how to optimally configure LLMs during inference has not been explored in sufficient depth. We study compute-optimal inference: designing models and inference strategies that optimally trade off additional inference-time compute for improved performance. As a first step towards understanding and designing compute-optimal inference methods, we assessed the effectiveness and computational efficiency of multiple inference strategies such as Greedy Search, Majority Voting, Best-of-N, Weighted Voting, and their variants on two different Tree Search algorithms, involving different model sizes and computational budgets. We found that a smaller language model with a novel tree search algorithm typically achieves a Pareto-optimal trade-off. These results highlight the potential benefits of deploying smaller models equipped with more sophisticated decoding algorithms in budget-constrained scenarios, e.g., on end-devices, to enhance problem-solving accuracy. For instance, we show that the Llemma-7B model can achieve competitive accuracy to a Llemma-34B model on MATH500 while using $2\times$ less FLOPs. Our findings could potentially apply to any generation task with a well-defined measure of success.