 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Training Superintelligent Software Agents through Self-Play SWE-RL
Dec 21, 2025While current software agents powered by large language models (LLMs) and agentic reinforcement learning (RL) can boost programmer productivity, their training data (e.g., GitHub issues and pull requests) and environments (e.g., pass-to-pass and fail-to-pass tests) heavily depend on human knowledge or curation, posing a fundamental barrier to superintelligence. In this paper, we present Self-play SWE-RL (SSR), a first step toward training paradigms for superintelligent software agents. Our approach takes minimal data assumptions, only requiring access to sandboxed repositories with source code and installed dependencies, with no need for human-labeled issues or tests. Grounded in these real-world codebases, a single LLM agent is trained via reinforcement learning in a self-play setting to iteratively inject and repair software bugs of increasing complexity, with each bug formally specified by a test patch rather than a natural language issue description. On the SWE-bench Verified and SWE-Bench Pro benchmarks, SSR achieves notable self-improvement (+10.4 and +7.8 points, respectively) and consistently outperforms the human-data baseline over the entire training trajectory, despite being evaluated on natural language issues absent from self-play. Our results, albeit early, suggest a path where agents autonomously gather extensive learning experiences from real-world software repositories, ultimately enabling superintelligent systems that exceed human capabilities in understanding how systems are constructed, solving novel challenges, and autonomously creating new software from scratch.
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
Apr 16, 2025We present BrowseComp, a simple yet challenging benchmark for measuring the ability for agents to browse the web. BrowseComp comprises 1,266 questions that require persistently navigating the internet in search of hard-to-find, entangled information. Despite the difficulty of the questions, BrowseComp is simple and easy-to-use, as predicted answers are short and easily verifiable against reference answers. BrowseComp for browsing agents can be seen as analogous to how programming competitions are an incomplete but useful benchmark for coding agents. While BrowseComp sidesteps challenges of a true user query distribution, like generating long answers or resolving ambiguity, it measures the important core capability of exercising persistence and creativity in finding information. BrowseComp can be found at https://github.com/openai/simple-evals.
Improve Vision Language Model Chain-of-thought Reasoning
Oct 21, 2024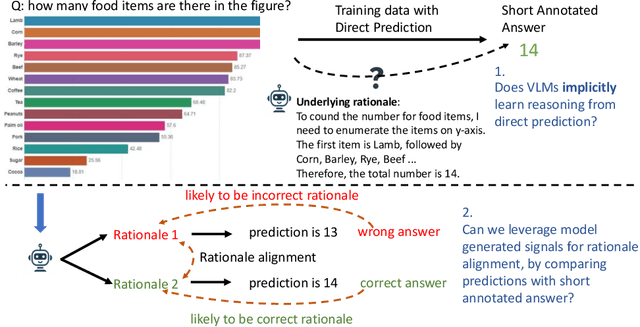


Chain-of-thought (CoT) reasoning in vision language models (VLMs) is crucial for improving interpretability and trustworthiness. However, current training recipes lack robust CoT reasoning data, relying on datasets dominated by short annotations with minimal rationales. In this work, we show that training VLM on short answers does not generalize well to reasoning tasks that require more detailed responses. To address this, we propose a two-fold approach. First, we distill rationales from GPT-4o model to enrich the training data and fine-tune VLMs, boosting their CoT performance. Second, we apply reinforcement learning to further calibrate reasoning quality. Specifically, we construct positive (correct) and negative (incorrect) pairs of model-generated reasoning chains, by comparing their predictions with annotated short answers. Using this pairwise data, we apply the Direct Preference Optimization algorithm to refine the model's reasoning abilities. Our experiments demonstrate significant improvements in CoT reasoning on benchmark datasets and better generalization to direct answer prediction as well. This work emphasizes the importance of incorporating detailed rationales in training and leveraging reinforcement learning to strengthen the reasoning capabilities of VLMs.
An Empirical Analysis of Compute-Optimal Inference for Problem-Solving with Language Models
Aug 01, 2024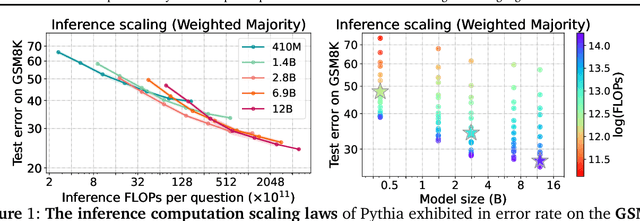
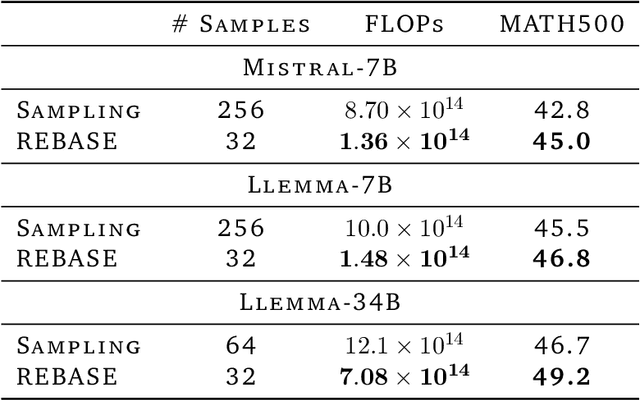
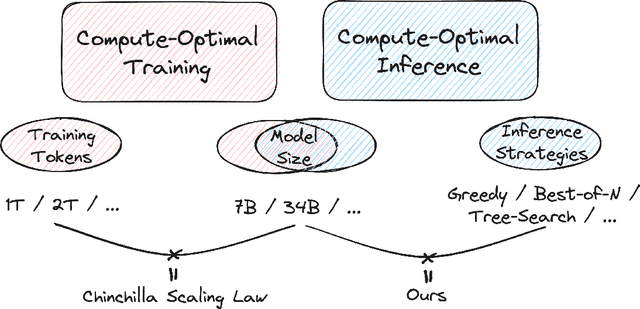
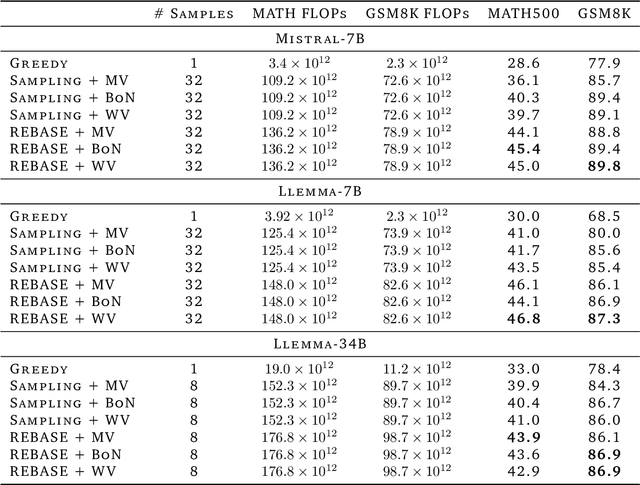
The optimal training configurations of large language models (LLMs) with respect to model sizes and compute budgets have been extensively studied. But how to optimally configure LLMs during inference has not been explored in sufficient depth. We study compute-optimal inference: designing models and inference strategies that optimally trade off additional inference-time compute for improved performance. As a first step towards understanding and designing compute-optimal inference methods, we assessed the effectiveness and computational efficiency of multiple inference strategies such as Greedy Search, Majority Voting, Best-of-N, Weighted Voting, and their variants on two different Tree Search algorithms, involving different model sizes and computational budgets. We found that a smaller language model with a novel tree search algorithm typically achieves a Pareto-optimal trade-off. These results highlight the potential benefits of deploying smaller models equipped with more sophisticated decoding algorithms in budget-constrained scenarios, e.g., on end-devices, to enhance problem-solving accuracy. For instance, we show that the Llemma-7B model can achieve competitive accuracy to a Llemma-34B model on MATH500 while using $2\times$ less FLOPs. Our findings could potentially apply to any generation task with a well-defined measure of success.
Lean-STaR: Learning to Interleave Thinking and Proving
Jul 14, 2024

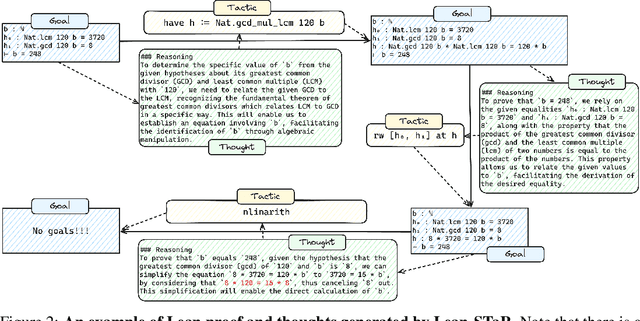

Traditional language model-based theorem proving assumes that by training on a sufficient amount of formal proof data, a model will learn to prove theorems. Our key observation is that a wealth of informal information that is not present in formal proofs can be useful for learning to prove theorems. For instance, humans think through steps of a proof, but this thought process is not visible in the resulting code. We present Lean-STaR, a framework for training language models to produce informal thoughts prior to each step of a proof, thereby boosting the model's theorem-proving capabilities. Lean-STaR uses retrospective ground-truth tactics to generate synthetic thoughts for training the language model. At inference time, the trained model directly generates the thoughts prior to the prediction of the tactics in each proof step. Building on the self-taught reasoner framework, we then apply expert iteration to further fine-tune the model on the correct proofs it samples and verifies using the Lean solver. Lean-STaR achieves state-of-the-art results on the miniF2F-test benchmark within the Lean theorem proving environment, significantly outperforming base models ($\boldsymbol{43.4\% \rightarrow 46.3\%,}$ Pass@64). We also analyze the impact of the augmented thoughts on various aspects of the theorem proving process, providing insights into their effectiveness.
Dr-LLaVA: Visual Instruction Tuning with Symbolic Clinical Grounding
May 29, 2024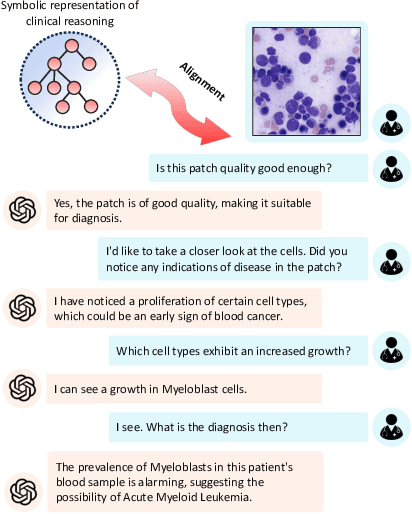
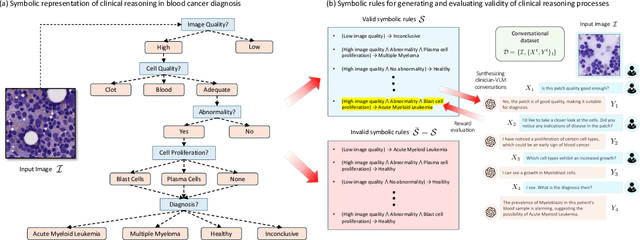
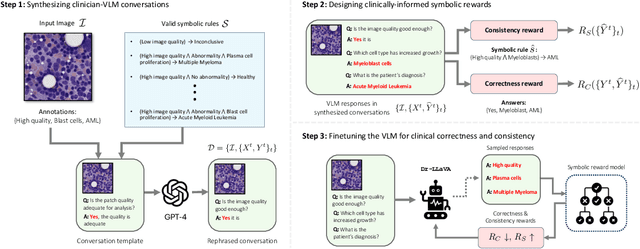
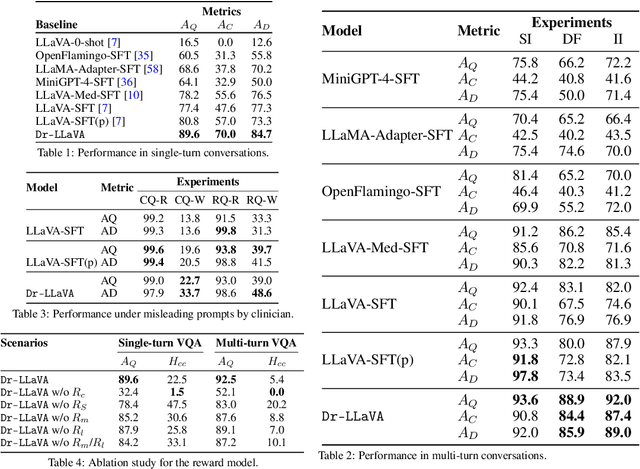
Vision-Language Models (VLM) can support clinicians by analyzing medical images and engaging in natural language interactions to assist in diagnostic and treatment tasks. However, VLMs often exhibit "hallucinogenic" behavior, generating textual outputs not grounded in contextual multimodal information. This challenge is particularly pronounced in the medical domain, where we do not only require VLM outputs to be accurate in single interactions but also to be consistent with clinical reasoning and diagnostic pathways throughout multi-turn conversations. For this purpose, we propose a new alignment algorithm that uses symbolic representations of clinical reasoning to ground VLMs in medical knowledge. These representations are utilized to (i) generate GPT-4-guided visual instruction tuning data at scale, simulating clinician-VLM conversations with demonstrations of clinical reasoning, and (ii) create an automatic reward function that evaluates the clinical validity of VLM generations throughout clinician-VLM interactions. Our algorithm eliminates the need for human involvement in training data generation or reward model construction, reducing costs compared to standard reinforcement learning with human feedback (RLHF). We apply our alignment algorithm to develop Dr-LLaVA, a conversational VLM finetuned for analyzing bone marrow pathology slides, demonstrating strong performance in multi-turn medical conversations.
LLM and Simulation as Bilevel Optimizers: A New Paradigm to Advance Physical Scientific Discovery
May 16, 2024



Large Language Models have recently gained significant attention in scientific discovery for their extensive knowledge and advanced reasoning capabilities. However, they encounter challenges in effectively simulating observational feedback and grounding it with language to propel advancements in physical scientific discovery. Conversely, human scientists undertake scientific discovery by formulating hypotheses, conducting experiments, and revising theories through observational analysis. Inspired by this, we propose to enhance the knowledge-driven, abstract reasoning abilities of LLMs with the computational strength of simulations. We introduce Scientific Generative Agent (SGA), a bilevel optimization framework: LLMs act as knowledgeable and versatile thinkers, proposing scientific hypotheses and reason about discrete components, such as physics equations or molecule structures; meanwhile, simulations function as experimental platforms, providing observational feedback and optimizing via differentiability for continuous parts, such as physical parameters. We conduct extensive experiments to demonstrate our framework's efficacy in constitutive law discovery and molecular design, unveiling novel solutions that differ from conventional human expectations yet remain coherent upon analysis.
Self-Play Preference Optimization for Language Model Alignment
May 01, 2024
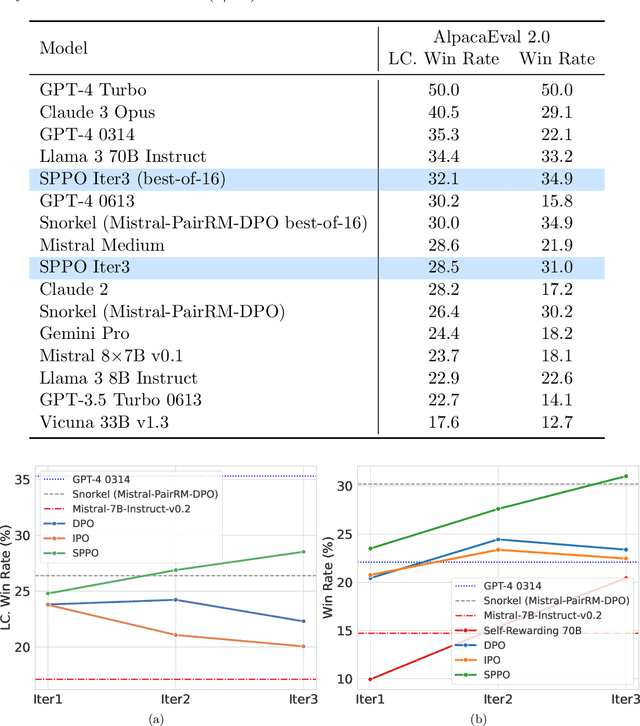


Traditional reinforcement learning from human feedback (RLHF) approaches relying on parametric models like the Bradley-Terry model fall short in capturing the intransitivity and irrationality in human preferences. Recent advancements suggest that directly working with preference probabilities can yield a more accurate reflection of human preferences, enabling more flexible and accurate language model alignment. In this paper, we propose a self-play-based method for language model alignment, which treats the problem as a constant-sum two-player game aimed at identifying the Nash equilibrium policy. Our approach, dubbed \textit{Self-Play Preference Optimization} (SPPO), approximates the Nash equilibrium through iterative policy updates and enjoys theoretical convergence guarantee. Our method can effectively increase the log-likelihood of the chosen response and decrease that of the rejected response, which cannot be trivially achieved by symmetric pairwise loss such as Direct Preference Optimization (DPO) and Identity Preference Optimization (IPO). In our experiments, using only 60k prompts (without responses) from the UltraFeedback dataset and without any prompt augmentation, by leveraging a pre-trained preference model PairRM with only 0.4B parameters, SPPO can obtain a model from fine-tuning Mistral-7B-Instruct-v0.2 that achieves the state-of-the-art length-controlled win-rate of 28.53% against GPT-4-Turbo on AlpacaEval 2.0. It also outperforms the (iterative) DPO and IPO on MT-Bench and the Open LLM Leaderboard. Notably, the strong performance of SPPO is achieved without additional external supervision (e.g., responses, preferences, etc.) from GPT-4 or other stronger language models.
Direct Preference Optimization of Video Large Multimodal Models from Language Model Reward
Apr 02, 2024



Preference modeling techniques, such as direct preference optimization (DPO), has shown effective in enhancing the generalization abilities of large language model (LLM). However, in tasks involving video instruction-following, providing informative feedback, especially for detecting hallucinations in generated responses, remains a significant challenge. Previous studies have explored using large large multimodal models (LMMs) as reward models to guide preference modeling, but their ability to accurately assess the factuality of generated responses compared to corresponding videos has not been conclusively established. This paper introduces a novel framework that utilizes detailed video captions as a proxy of video content, enabling language models to incorporate this information as supporting evidence for scoring video Question Answering (QA) predictions. Our approach demonstrates robust alignment with OpenAI GPT-4V model's reward mechanism, which directly takes video frames as input. Furthermore, we show that applying this tailored reward through DPO significantly improves the performance of video LMMs on video QA tasks.
Easy-to-Hard Generalization: Scalable Alignment Beyond Human Supervision
Mar 14, 2024


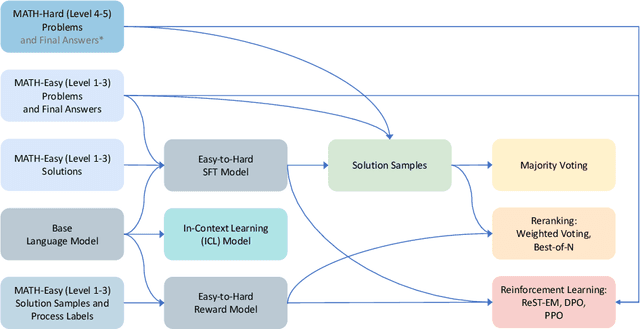
Current AI alignment methodologies rely on human-provided demonstrations or judgments, and the learned capabilities of AI systems would be upper-bounded by human capabilities as a result. This raises a challenging research question: How can we keep improving the systems when their capabilities have surpassed the levels of humans? This paper answers this question in the context of tackling hard reasoning tasks (e.g., level 4-5 MATH problems) via learning from human annotations on easier tasks (e.g., level 1-3 MATH problems), which we term as \textit{easy-to-hard generalization}. Our key insight is that an evaluator (reward model) trained on supervisions for easier tasks can be effectively used for scoring candidate solutions of harder tasks and hence facilitating easy-to-hard generalization over different levels of tasks. Based on this insight, we propose a novel approach to scalable alignment, which firstly trains the process-supervised reward models on easy problems (e.g., level 1-3), and then uses them to evaluate the performance of policy models on hard problems. We show that such \textit{easy-to-hard generalization from evaluators} can enable \textit{easy-to-hard generalizations in generators} either through re-ranking or reinforcement learning (RL). Notably, our process-supervised 7b RL model achieves an accuracy of 34.0\% on MATH500, despite only using human supervision on easy problems. Our approach suggests a promising path toward AI systems that advance beyond the frontier of human supervision.