 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
MiMo-Audio: Audio Language Models are Few-Shot Learners
Dec 29, 2025Existing audio language models typically rely on task-specific fine-tuning to accomplish particular audio tasks. In contrast, humans are able to generalize to new audio tasks with only a few examples or simple instructions. GPT-3 has shown that scaling next-token prediction pretraining enables strong generalization capabilities in text, and we believe this paradigm is equally applicable to the audio domain. By scaling MiMo-Audio's pretraining data to over one hundred million of hours, we observe the emergence of few-shot learning capabilities across a diverse set of audio tasks. We develop a systematic evaluation of these capabilities and find that MiMo-Audio-7B-Base achieves SOTA performance on both speech intelligence and audio understanding benchmarks among open-source models. Beyond standard metrics, MiMo-Audio-7B-Base generalizes to tasks absent from its training data, such as voice conversion, style transfer, and speech editing. MiMo-Audio-7B-Base also demonstrates powerful speech continuation capabilities, capable of generating highly realistic talk shows, recitations, livestreaming and debates. At the post-training stage, we curate a diverse instruction-tuning corpus and introduce thinking mechanisms into both audio understanding and generation. MiMo-Audio-7B-Instruct achieves open-source SOTA on audio understanding benchmarks (MMSU, MMAU, MMAR, MMAU-Pro), spoken dialogue benchmarks (Big Bench Audio, MultiChallenge Audio) and instruct-TTS evaluations, approaching or surpassing closed-source models. Model checkpoints and full evaluation suite are available at https://github.com/XiaomiMiMo/MiMo-Audio.
Mitigating Overthinking through Reasoning Shaping
Oct 10, 2025Large reasoning models (LRMs) boosted by Reinforcement Learning from Verifier Reward (RLVR) have shown great power in problem solving, yet they often cause overthinking: excessive, meandering reasoning that inflates computational cost. Prior designs of penalization in RLVR manage to reduce token consumption while often harming model performance, which arises from the oversimplicity of token-level supervision. In this paper, we argue that the granularity of supervision plays a crucial role in balancing efficiency and accuracy, and propose Group Relative Segment Penalization (GRSP), a step-level method to regularize reasoning. Since preliminary analyses show that reasoning segments are strongly correlated with token consumption and model performance, we design a length-aware weighting mechanism across segment clusters. Extensive experiments demonstrate that GRSP achieves superior token efficiency without heavily compromising accuracy, especially the advantages with harder problems. Moreover, GRSP stabilizes RL training and scales effectively across model sizes.
P-Aligner: Enabling Pre-Alignment of Language Models via Principled Instruction Synthesis
Aug 06, 2025
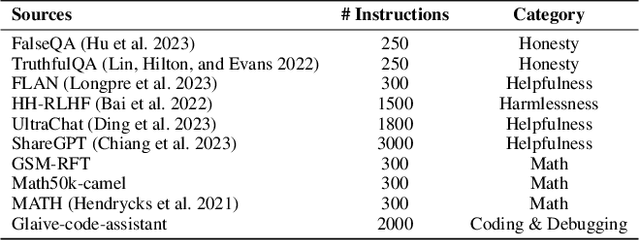
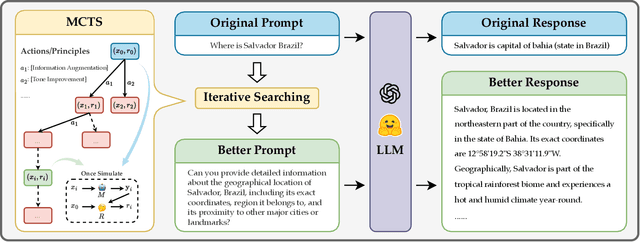
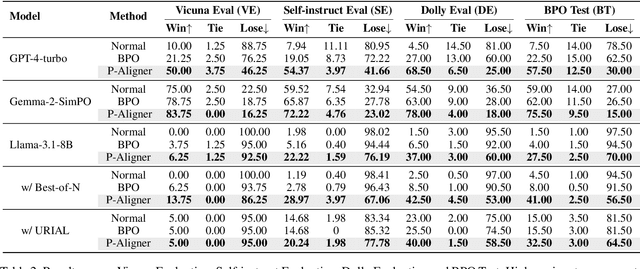
Large Language Models (LLMs) are expected to produce safe, helpful, and honest content during interaction with human users, but they frequently fail to align with such values when given flawed instructions, e.g., missing context, ambiguous directives, or inappropriate tone, leaving substantial room for improvement along multiple dimensions. A cost-effective yet high-impact way is to pre-align instructions before the model begins decoding. Existing approaches either rely on prohibitive test-time search costs or end-to-end model rewrite, which is powered by a customized training corpus with unclear objectives. In this work, we demonstrate that the goal of efficient and effective preference alignment can be achieved by P-Aligner, a lightweight module generating instructions that preserve the original intents while being expressed in a more human-preferred form. P-Aligner is trained on UltraPrompt, a new dataset synthesized via a proposed principle-guided pipeline using Monte-Carlo Tree Search, which systematically explores the space of candidate instructions that are closely tied to human preference. Experiments across different methods show that P-Aligner generally outperforms strong baselines across various models and benchmarks, including average win-rate gains of 28.35% and 8.69% on GPT-4-turbo and Gemma-2-SimPO, respectively. Further analyses validate its effectiveness and efficiency through multiple perspectives, including data quality, search strategies, iterative deployment, and time overhead.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
Teaching Large Language Models to Maintain Contextual Faithfulness via Synthetic Tasks and Reinforcement Learning
May 22, 2025Teaching large language models (LLMs) to be faithful in the provided context is crucial for building reliable information-seeking systems. Therefore, we propose a systematic framework, CANOE, to improve the faithfulness of LLMs in both short-form and long-form generation tasks without human annotations. Specifically, we first synthesize short-form question-answering (QA) data with four diverse tasks to construct high-quality and easily verifiable training data without human annotation. Also, we propose Dual-GRPO, a rule-based reinforcement learning method that includes three tailored rule-based rewards derived from synthesized short-form QA data, while simultaneously optimizing both short-form and long-form response generation. Notably, Dual-GRPO eliminates the need to manually label preference data to train reward models and avoids over-optimizing short-form generation when relying only on the synthesized short-form QA data. Experimental results show that CANOE greatly improves the faithfulness of LLMs across 11 different downstream tasks, even outperforming the most advanced LLMs, e.g., GPT-4o and OpenAI o1.
CodeElo: Benchmarking Competition-level Code Generation of LLMs with Human-comparable Elo Ratings
Jan 03, 2025With the increasing code reasoning capabilities of existing large language models (LLMs) and breakthroughs in reasoning models like OpenAI o1 and o3, there is a growing need to develop more challenging and comprehensive benchmarks that effectively test their sophisticated competition-level coding abilities. Existing benchmarks, like LiveCodeBench and USACO, fall short due to the unavailability of private test cases, lack of support for special judges, and misaligned execution environments. To bridge this gap, we introduce CodeElo, a standardized competition-level code generation benchmark that effectively addresses all these challenges for the first time. CodeElo benchmark is mainly based on the official CodeForces platform and tries to align with the platform as much as possible. We compile the recent six months of contest problems on CodeForces with detailed information such as contest divisions, problem difficulty ratings, and problem algorithm tags. We introduce a unique judging method in which problems are submitted directly to the platform and develop a reliable Elo rating calculation system that aligns with the platform and is comparable with human participants but has lower variance. By testing on our CodeElo, we provide the Elo ratings of 30 existing popular open-source and 3 proprietary LLMs for the first time. The results show that o1-mini and QwQ-32B-Preview stand out significantly, achieving Elo ratings of 1578 and 1261, respectively, while other models struggle even with the easiest problems, placing in the lowest 25 percent among all human participants. Detailed analysis experiments are also conducted to provide insights into performance across algorithms and comparisons between using C++ and Python, which can suggest directions for future studies.
Language Models can Self-Lengthen to Generate Long Texts
Oct 31, 2024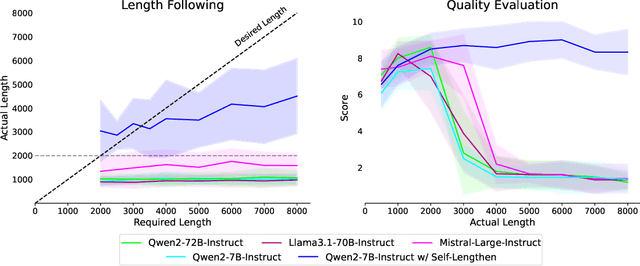
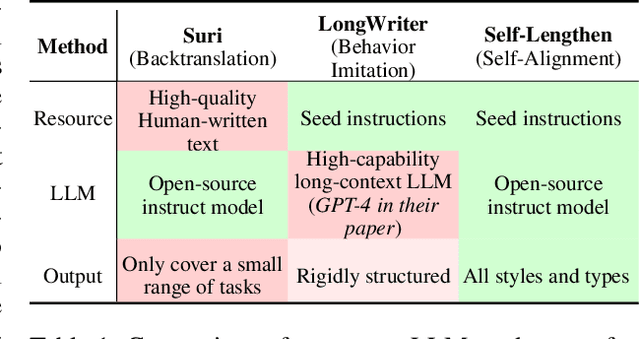
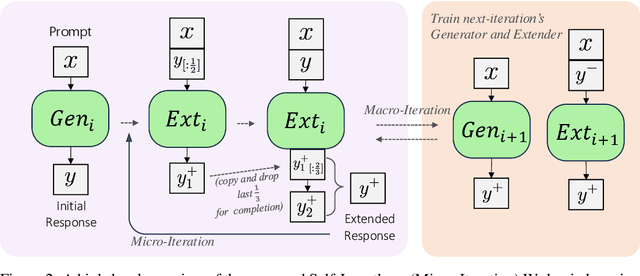
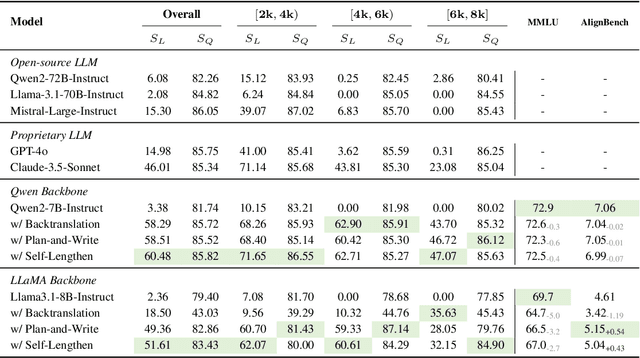
Recent advancements in Large Language Models (LLMs) have significantly enhanced their ability to process long contexts, yet a notable gap remains in generating long, aligned outputs. This limitation stems from a training gap where pre-training lacks effective instructions for long-text generation, and post-training data primarily consists of short query-response pairs. Current approaches, such as instruction backtranslation and behavior imitation, face challenges including data quality, copyright issues, and constraints on proprietary model usage. In this paper, we introduce an innovative iterative training framework called Self-Lengthen that leverages only the intrinsic knowledge and skills of LLMs without the need for auxiliary data or proprietary models. The framework consists of two roles: the Generator and the Extender. The Generator produces the initial response, which is then split and expanded by the Extender. This process results in a new, longer response, which is used to train both the Generator and the Extender iteratively. Through this process, the models are progressively trained to handle increasingly longer responses. Experiments on benchmarks and human evaluations show that Self-Lengthen outperforms existing methods in long-text generation, when applied to top open-source LLMs such as Qwen2 and LLaMA3. Our code is publicly available at https://github.com/QwenLM/Self-Lengthen.
Aligning CodeLLMs with Direct Preference Optimization
Oct 24, 2024The last year has witnessed the rapid progress of large language models (LLMs) across diverse domains. Among them, CodeLLMs have garnered particular attention because they can not only assist in completing various programming tasks but also represent the decision-making and logical reasoning capabilities of LLMs. However, current CodeLLMs mainly focus on pre-training and supervised fine-tuning scenarios, leaving the alignment stage, which is important for post-training LLMs, under-explored. This work first identifies that the commonly used PPO algorithm may be suboptimal for the alignment of CodeLLM because the involved reward rules are routinely coarse-grained and potentially flawed. We then advocate addressing this using the DPO algorithm. Based on only preference data pairs, DPO can render the model rank data automatically, giving rise to a fine-grained rewarding pattern more robust than human intervention. We also contribute a pipeline for collecting preference pairs for DPO on CodeLLMs. Studies show that our method significantly improves the performance of existing CodeLLMs on benchmarks such as MBPP and HumanEval.
Omni-MATH: A Universal Olympiad Level Mathematic Benchmark For Large Language Models
Oct 10, 2024
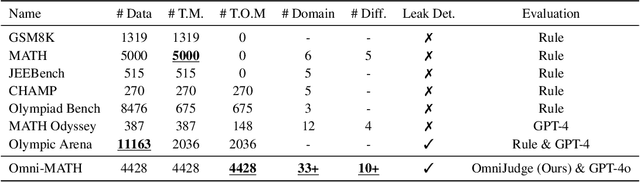

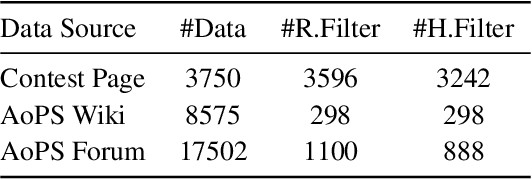
Recent advancements in large language models (LLMs) have led to significant breakthroughs in mathematical reasoning capabilities. However, existing benchmarks like GSM8K or MATH are now being solved with high accuracy (e.g., OpenAI o1 achieves 94.8% on MATH dataset), indicating their inadequacy for truly challenging these models. To bridge this gap, we propose a comprehensive and challenging benchmark specifically designed to assess LLMs' mathematical reasoning at the Olympiad level. Unlike existing Olympiad-related benchmarks, our dataset focuses exclusively on mathematics and comprises a vast collection of 4428 competition-level problems with rigorous human annotation. These problems are meticulously categorized into over 33 sub-domains and span more than 10 distinct difficulty levels, enabling a holistic assessment of model performance in Olympiad-mathematical reasoning. Furthermore, we conducted an in-depth analysis based on this benchmark. Our experimental results show that even the most advanced models, OpenAI o1-mini and OpenAI o1-preview, struggle with highly challenging Olympiad-level problems, with 60.54% and 52.55% accuracy, highlighting significant challenges in Olympiad-level mathematical reasoning.