 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models can Self-Lengthen to Generate Long Texts
Paper and Code
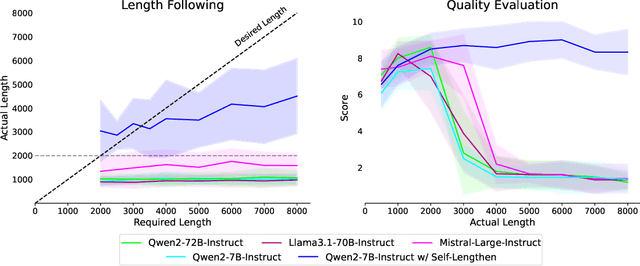
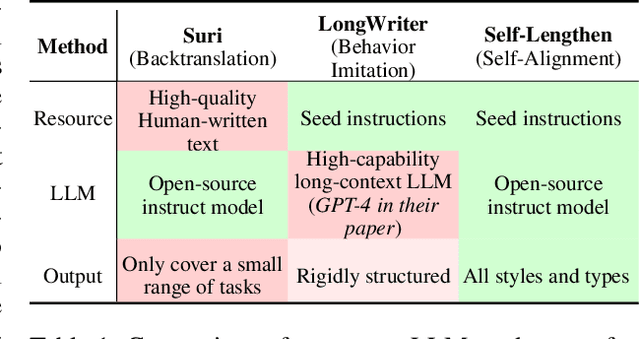
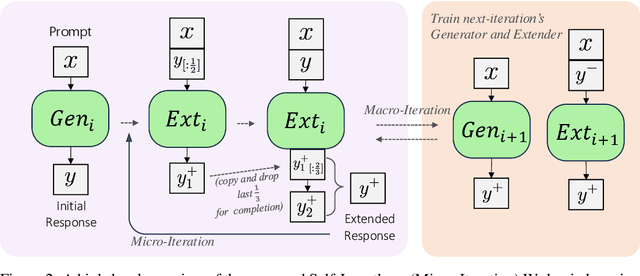
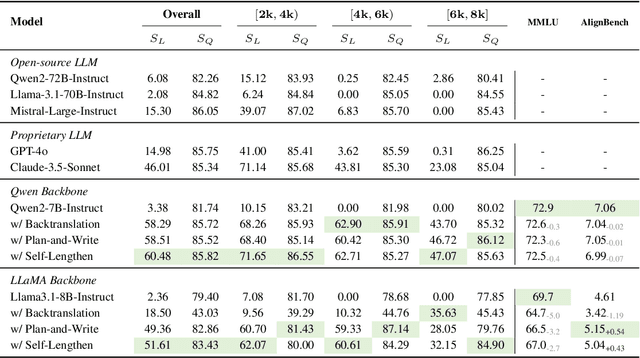
Recent advancements in Large Language Models (LLMs) have significantly enhanced their ability to process long contexts, yet a notable gap remains in generating long, aligned outputs. This limitation stems from a training gap where pre-training lacks effective instructions for long-text generation, and post-training data primarily consists of short query-response pairs. Current approaches, such as instruction backtranslation and behavior imitation, face challenges including data quality, copyright issues, and constraints on proprietary model usage. In this paper, we introduce an innovative iterative training framework called Self-Lengthen that leverages only the intrinsic knowledge and skills of LLMs without the need for auxiliary data or proprietary models. The framework consists of two roles: the Generator and the Extender. The Generator produces the initial response, which is then split and expanded by the Extender. This process results in a new, longer response, which is used to train both the Generator and the Extender iteratively. Through this process, the models are progressively trained to handle increasingly longer responses. Experiments on benchmarks and human evaluations show that Self-Lengthen outperforms existing methods in long-text generation, when applied to top open-source LLMs such as Qwen2 and LLaMA3. Our code is publicly available at https://github.com/QwenLM/Self-Lengthen.