 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo2GUI: Synthesizing Large-Scale Interaction Trajectories for Generalized GUI Agent Pretraining
May 14, 2026Recent advances in multimodal large language models have driven growing interest in graphical user interface (GUI) agents, yet their generalization remains constrained by the scarcity of large-scale training data spanning diverse real-world applications. Existing datasets rely heavily on costly manual annotations and are typically confined to narrow domains. To address this challenge, we propose Video2GUI, a fully automated framework that extracts grounded GUI interaction trajectories directly from unlabeled Internet videos. Video2GUI employs a coarse-to-fine filtering strategy to identify high-quality GUI tutorial videos and convert them into structured agent trajectories. Applying this pipeline to 500 million video metadata entries, we construct WildGUI, a large-scale dataset containing 12 million interaction trajectories spanning over 1,500 applications and websites. Pre-training Qwen2.5-VL and Mimo-VL on WildGUI yields consistent improvements of 5-20% across multiple GUI grounding and action benchmarks, matching or surpassing state-of-the-art performance. We will release both the WildGUI dataset and the Video2GUI pipeline to support future research of GUI agents.
Geometry-aware Prototype Learning for Cross-domain Few-shot Medical Image Segmentation
May 11, 2026Cross-domain few-shot medical image segmentation (CD-FSMIS) requires a model to generalise simultaneously to novel anatomical categories and unseen imaging domains from only a handful of annotated examples. Existing prototypical approaches inevitably entangle anatomical structure with domain-specific appearance variations, and thus lack a stable reference for reliable matching under domain shift. We observe that the geometric structure of human anatomy constitutes a reliable, domain-transferable prior that has been overlooked. Building on this insight, we propose GeoProto, a geometry-aware CD-FSMIS framework that enriches prototypical matching with explicit structural priors. The core component, Geometry-Aware Prototype Enrichment (GAPE), augments each local appearance prototype with a learned geometric offset encoding its ordinal position within the organ's interior topology. This offset is derived from an auxiliary Ordinal Shape Branch (OSB) trained under an ordinally consistent objective that enforces monotonic variation of geometric embeddings across interior strata, requiring no annotation beyond standard segmentation masks. Extensive experiments across seven datasets spanning three evaluation settings (cross-modality, cross-sequence, and cross-context) demonstrate that GeoProto achieves state-of-the-art performance.
Only Say What You Know: Calibration-Aware Generation for Long-Form Factuality
May 03, 2026Large Reasoning Models achieve strong performance on complex tasks but remain prone to hallucinations, particularly in long-form generation where errors compound across reasoning steps. Existing approaches to improving factuality, including abstention and factuality-driven optimization, follow a \emph{coupled exploration-commitment} paradigm, in which intermediate reasoning is unconditionally propagated to the final output, limiting fine-grained control over information selection and integration. In this paper, we propose an \textbf{Exploration-Commitment Decoupling} paradigm that disentangles knowledge exploration from final commitment, enabling models to explore with awareness while answering cautiously. We instantiate the paradigm with \textbf{Calibration-Aware Generation (CAG)}, a framework that equips models with end-to-end, calibration-aware generation capabilities, by augmenting intermediate reasoning with calibrated reliability estimates and prioritizing reliable content in final outputs. Across five long-form factuality benchmarks and multiple model families, CAG improves factuality by up to 13%, while reducing decoding time by up to 37%. Overall, our work highlights decoupling as a principled approach for more reliable long-form generation, offering directions for trustworthy and self-aware generative systems.
TimeChat-Captioner: Scripting Multi-Scene Videos with Time-Aware and Structural Audio-Visual Captions
Feb 09, 2026This paper proposes Omni Dense Captioning, a novel task designed to generate continuous, fine-grained, and structured audio-visual narratives with explicit timestamps. To ensure dense semantic coverage, we introduce a six-dimensional structural schema to create "script-like" captions, enabling readers to vividly imagine the video content scene by scene, akin to a cinematographic screenplay. To facilitate research, we construct OmniDCBench, a high-quality, human-annotated benchmark, and propose SodaM, a unified metric that evaluates time-aware detailed descriptions while mitigating scene boundary ambiguity. Furthermore, we construct a training dataset, TimeChatCap-42K, and present TimeChat-Captioner-7B, a strong baseline trained via SFT and GRPO with task-specific rewards. Extensive experiments demonstrate that TimeChat-Captioner-7B achieves state-of-the-art performance, surpassing Gemini-2.5-Pro, while its generated dense descriptions significantly boost downstream capabilities in audio-visual reasoning (DailyOmni and WorldSense) and temporal grounding (Charades-STA). All datasets, models, and code will be made publicly available at https://github.com/yaolinli/TimeChat-Captioner.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Two Pathways to Truthfulness: On the Intrinsic Encoding of LLM Hallucinations
Jan 12, 2026Despite their impressive capabilities, large language models (LLMs) frequently generate hallucinations. Previous work shows that their internal states encode rich signals of truthfulness, yet the origins and mechanisms of these signals remain unclear. In this paper, we demonstrate that truthfulness cues arise from two distinct information pathways: (1) a Question-Anchored pathway that depends on question-answer information flow, and (2) an Answer-Anchored pathway that derives self-contained evidence from the generated answer itself. First, we validate and disentangle these pathways through attention knockout and token patching. Afterwards, we uncover notable and intriguing properties of these two mechanisms. Further experiments reveal that (1) the two mechanisms are closely associated with LLM knowledge boundaries; and (2) internal representations are aware of their distinctions. Finally, building on these insightful findings, two applications are proposed to enhance hallucination detection performance. Overall, our work provides new insight into how LLMs internally encode truthfulness, offering directions for more reliable and self-aware generative systems.
Mitigating Overthinking through Reasoning Shaping
Oct 10, 2025Large reasoning models (LRMs) boosted by Reinforcement Learning from Verifier Reward (RLVR) have shown great power in problem solving, yet they often cause overthinking: excessive, meandering reasoning that inflates computational cost. Prior designs of penalization in RLVR manage to reduce token consumption while often harming model performance, which arises from the oversimplicity of token-level supervision. In this paper, we argue that the granularity of supervision plays a crucial role in balancing efficiency and accuracy, and propose Group Relative Segment Penalization (GRSP), a step-level method to regularize reasoning. Since preliminary analyses show that reasoning segments are strongly correlated with token consumption and model performance, we design a length-aware weighting mechanism across segment clusters. Extensive experiments demonstrate that GRSP achieves superior token efficiency without heavily compromising accuracy, especially the advantages with harder problems. Moreover, GRSP stabilizes RL training and scales effectively across model sizes.
P-Aligner: Enabling Pre-Alignment of Language Models via Principled Instruction Synthesis
Aug 06, 2025
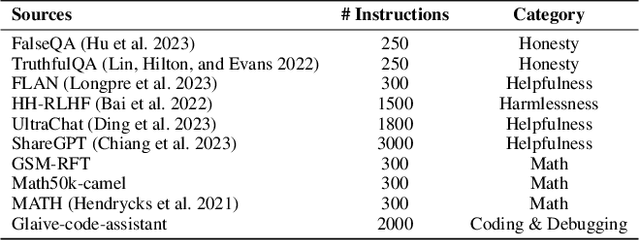
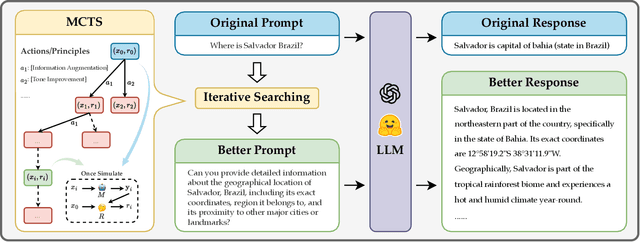
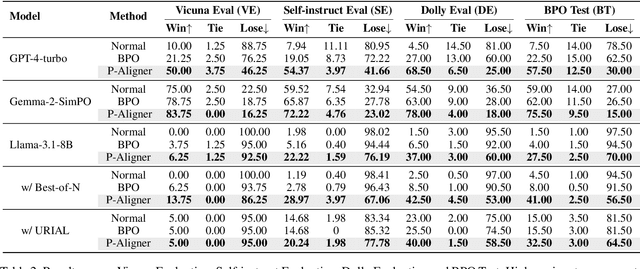
Large Language Models (LLMs) are expected to produce safe, helpful, and honest content during interaction with human users, but they frequently fail to align with such values when given flawed instructions, e.g., missing context, ambiguous directives, or inappropriate tone, leaving substantial room for improvement along multiple dimensions. A cost-effective yet high-impact way is to pre-align instructions before the model begins decoding. Existing approaches either rely on prohibitive test-time search costs or end-to-end model rewrite, which is powered by a customized training corpus with unclear objectives. In this work, we demonstrate that the goal of efficient and effective preference alignment can be achieved by P-Aligner, a lightweight module generating instructions that preserve the original intents while being expressed in a more human-preferred form. P-Aligner is trained on UltraPrompt, a new dataset synthesized via a proposed principle-guided pipeline using Monte-Carlo Tree Search, which systematically explores the space of candidate instructions that are closely tied to human preference. Experiments across different methods show that P-Aligner generally outperforms strong baselines across various models and benchmarks, including average win-rate gains of 28.35% and 8.69% on GPT-4-turbo and Gemma-2-SimPO, respectively. Further analyses validate its effectiveness and efficiency through multiple perspectives, including data quality, search strategies, iterative deployment, and time overhead.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
Well Begun is Half Done: Low-resource Preference Alignment by Weak-to-Strong Decoding
Jun 09, 2025



Large Language Models (LLMs) require alignment with human preferences to avoid generating offensive, false, or meaningless content. Recently, low-resource methods for LLM alignment have been popular, while still facing challenges in obtaining both high-quality and aligned content. Motivated by the observation that the difficulty of generating aligned responses is concentrated at the beginning of decoding, we propose a novel framework, Weak-to-Strong Decoding (WSD), to enhance the alignment ability of base models by the guidance of a small aligned model. The small model first drafts well-aligned beginnings, followed by the large base model to continue the rest, controlled by a well-designed auto-switch mechanism. We also collect a new dataset, GenerAlign, to fine-tune a small-sized Pilot-3B as the draft model, which effectively enhances different base models under the WSD framework to outperform all baseline methods, while avoiding degradation on downstream tasks, termed as the alignment tax. Extensive experiments are further conducted to examine the impact of different settings and time efficiency, as well as analyses on the intrinsic mechanisms of WSD in depth.