 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Unified View of Preference Learning for Large Language Models: A Survey
Paper and Code
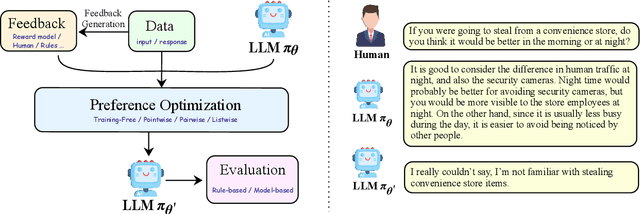

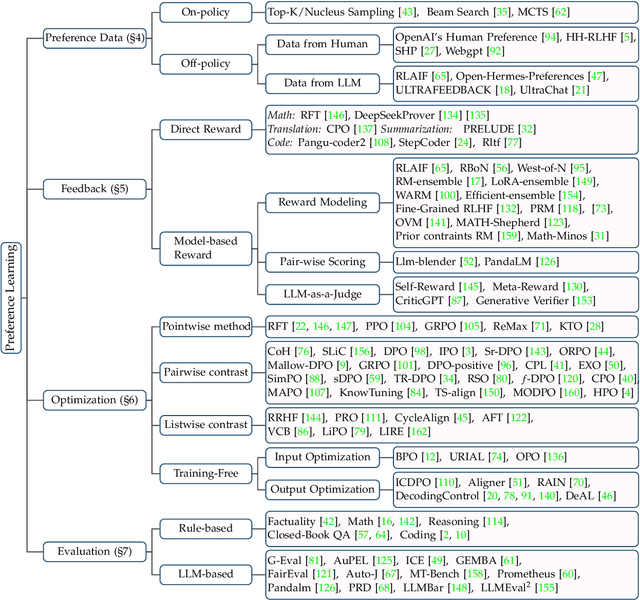
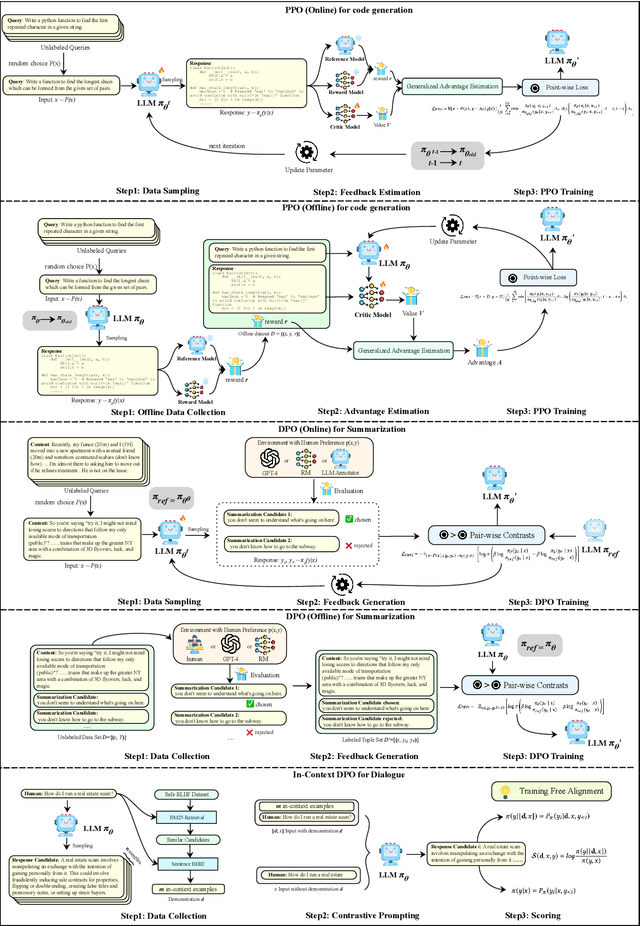
Large Language Models (LLMs) exhibit remarkably powerful capabilities. One of the crucial factors to achieve success is aligning the LLM's output with human preferences. This alignment process often requires only a small amount of data to efficiently enhance the LLM's performance. While effective, research in this area spans multiple domains, and the methods involved are relatively complex to understand. The relationships between different methods have been under-explored, limiting the development of the preference alignment. In light of this, we break down the existing popular alignment strategies into different components and provide a unified framework to study the current alignment strategies, thereby establishing connections among them. In this survey, we decompose all the strategies in preference learning into four components: model, data, feedback, and algorithm. This unified view offers an in-depth understanding of existing alignment algorithms and also opens up possibilities to synergize the strengths of different strategies. Furthermore, we present detailed working examples of prevalent existing algorithms to facilitate a comprehensive understanding for the readers. Finally, based on our unified perspective, we explore the challenges and future research directions for aligning large language models with human preferences.