 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentRefusal: Latent-Signal Refusal for Unanswerable Text-to-SQL Queries
Jan 16, 2026In LLM-based text-to-SQL systems, unanswerable and underspecified user queries may generate not only incorrect text but also executable programs that yield misleading results or violate safety constraints, posing a major barrier to safe deployment. Existing refusal strategies for such queries either rely on output-level instruction following, which is brittle due to model hallucinations, or estimate output uncertainty, which adds complexity and overhead. To address this challenge, we formalize safe refusal in text-to-SQL systems as an answerability-gating problem and propose LatentRefusal, a latent-signal refusal mechanism that predicts query answerability from intermediate hidden activations of a large language model. We introduce the Tri-Residual Gated Encoder, a lightweight probing architecture, to suppress schema noise and amplify sparse, localized cues of question-schema mismatch that indicate unanswerability. Extensive empirical evaluations across diverse ambiguous and unanswerable settings, together with ablation studies and interpretability analyses, demonstrate the effectiveness of the proposed approach and show that LatentRefusal provides an attachable and efficient safety layer for text-to-SQL systems. Across four benchmarks, LatentRefusal improves average F1 to 88.5 percent on both backbones while adding approximately 2 milliseconds of probe overhead.
Qwen3 Technical Report
May 14, 2025



In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models--such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ-32B)--and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0.
CodeElo: Benchmarking Competition-level Code Generation of LLMs with Human-comparable Elo Ratings
Jan 03, 2025With the increasing code reasoning capabilities of existing large language models (LLMs) and breakthroughs in reasoning models like OpenAI o1 and o3, there is a growing need to develop more challenging and comprehensive benchmarks that effectively test their sophisticated competition-level coding abilities. Existing benchmarks, like LiveCodeBench and USACO, fall short due to the unavailability of private test cases, lack of support for special judges, and misaligned execution environments. To bridge this gap, we introduce CodeElo, a standardized competition-level code generation benchmark that effectively addresses all these challenges for the first time. CodeElo benchmark is mainly based on the official CodeForces platform and tries to align with the platform as much as possible. We compile the recent six months of contest problems on CodeForces with detailed information such as contest divisions, problem difficulty ratings, and problem algorithm tags. We introduce a unique judging method in which problems are submitted directly to the platform and develop a reliable Elo rating calculation system that aligns with the platform and is comparable with human participants but has lower variance. By testing on our CodeElo, we provide the Elo ratings of 30 existing popular open-source and 3 proprietary LLMs for the first time. The results show that o1-mini and QwQ-32B-Preview stand out significantly, achieving Elo ratings of 1578 and 1261, respectively, while other models struggle even with the easiest problems, placing in the lowest 25 percent among all human participants. Detailed analysis experiments are also conducted to provide insights into performance across algorithms and comparisons between using C++ and Python, which can suggest directions for future studies.
Qwen2.5 Technical Report
Dec 19, 2024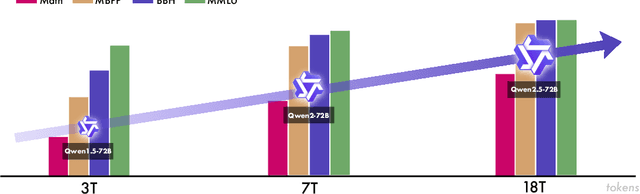

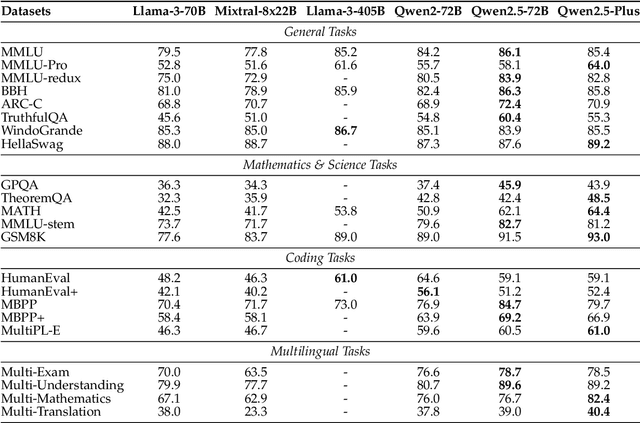
In this report, we introduce Qwen2.5, a comprehensive series of large language models (LLMs) designed to meet diverse needs. Compared to previous iterations, Qwen 2.5 has been significantly improved during both the pre-training and post-training stages. In terms of pre-training, we have scaled the high-quality pre-training datasets from the previous 7 trillion tokens to 18 trillion tokens. This provides a strong foundation for common sense, expert knowledge, and reasoning capabilities. In terms of post-training, we implement intricate supervised finetuning with over 1 million samples, as well as multistage reinforcement learning. Post-training techniques enhance human preference, and notably improve long text generation, structural data analysis, and instruction following. To handle diverse and varied use cases effectively, we present Qwen2.5 LLM series in rich sizes. Open-weight offerings include base and instruction-tuned models, with quantized versions available. In addition, for hosted solutions, the proprietary models currently include two mixture-of-experts (MoE) variants: Qwen2.5-Turbo and Qwen2.5-Plus, both available from Alibaba Cloud Model Studio. Qwen2.5 has demonstrated top-tier performance on a wide range of benchmarks evaluating language understanding, reasoning, mathematics, coding, human preference alignment, etc. Specifically, the open-weight flagship Qwen2.5-72B-Instruct outperforms a number of open and proprietary models and demonstrates competitive performance to the state-of-the-art open-weight model, Llama-3-405B-Instruct, which is around 5 times larger. Qwen2.5-Turbo and Qwen2.5-Plus offer superior cost-effectiveness while performing competitively against GPT-4o-mini and GPT-4o respectively. Additionally, as the foundation, Qwen2.5 models have been instrumental in training specialized models such as Qwen2.5-Math, Qwen2.5-Coder, QwQ, and multimodal models.
Omni-MATH: A Universal Olympiad Level Mathematic Benchmark For Large Language Models
Oct 10, 2024
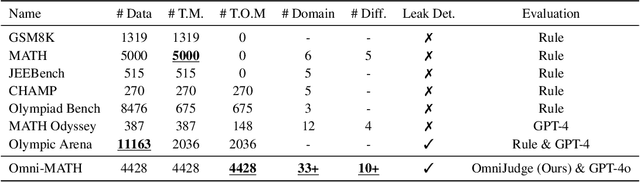

Recent advancements in large language models (LLMs) have led to significant breakthroughs in mathematical reasoning capabilities. However, existing benchmarks like GSM8K or MATH are now being solved with high accuracy (e.g., OpenAI o1 achieves 94.8% on MATH dataset), indicating their inadequacy for truly challenging these models. To bridge this gap, we propose a comprehensive and challenging benchmark specifically designed to assess LLMs' mathematical reasoning at the Olympiad level. Unlike existing Olympiad-related benchmarks, our dataset focuses exclusively on mathematics and comprises a vast collection of 4428 competition-level problems with rigorous human annotation. These problems are meticulously categorized into over 33 sub-domains and span more than 10 distinct difficulty levels, enabling a holistic assessment of model performance in Olympiad-mathematical reasoning. Furthermore, we conducted an in-depth analysis based on this benchmark. Our experimental results show that even the most advanced models, OpenAI o1-mini and OpenAI o1-preview, struggle with highly challenging Olympiad-level problems, with 60.54% and 52.55% accuracy, highlighting significant challenges in Olympiad-level mathematical reasoning.
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Sep 18, 2024



We present the Qwen2-VL Series, an advanced upgrade of the previous Qwen-VL models that redefines the conventional predetermined-resolution approach in visual processing. Qwen2-VL introduces the Naive Dynamic Resolution mechanism, which enables the model to dynamically process images of varying resolutions into different numbers of visual tokens. This approach allows the model to generate more efficient and accurate visual representations, closely aligning with human perceptual processes. The model also integrates Multimodal Rotary Position Embedding (M-RoPE), facilitating the effective fusion of positional information across text, images, and videos. We employ a unified paradigm for processing both images and videos, enhancing the model's visual perception capabilities. To explore the potential of large multimodal models, Qwen2-VL investigates the scaling laws for large vision-language models (LVLMs). By scaling both the model size-with versions at 2B, 8B, and 72B parameters-and the amount of training data, the Qwen2-VL Series achieves highly competitive performance. Notably, the Qwen2-VL-72B model achieves results comparable to leading models such as GPT-4o and Claude3.5-Sonnet across various multimodal benchmarks, outperforming other generalist models. Code is available at \url{https://github.com/QwenLM/Qwen2-VL}.
Qwen2.5-Coder Technical Report
Sep 18, 2024



In this report, we introduce the Qwen2.5-Coder series, a significant upgrade from its predecessor, CodeQwen1.5. This series includes two models: Qwen2.5-Coder-1.5B and Qwen2.5-Coder-7B. As a code-specific model, Qwen2.5-Coder is built upon the Qwen2.5 architecture and continues pretrained on a vast corpus of over 5.5 trillion tokens. Through meticulous data cleaning, scalable synthetic data generation, and balanced data mixing, Qwen2.5-Coder demonstrates impressive code generation capabilities while retaining general versatility. The model has been evaluated on a wide range of code-related tasks, achieving state-of-the-art (SOTA) performance across more than 10 benchmarks, including code generation, completion, reasoning, and repair, consistently outperforming larger models of the same model size. We believe that the release of the Qwen2.5-Coder series will not only push the boundaries of research in code intelligence but also, through its permissive licensing, encourage broader adoption by developers in real-world applications.
Qwen2 Technical Report
Jul 16, 2024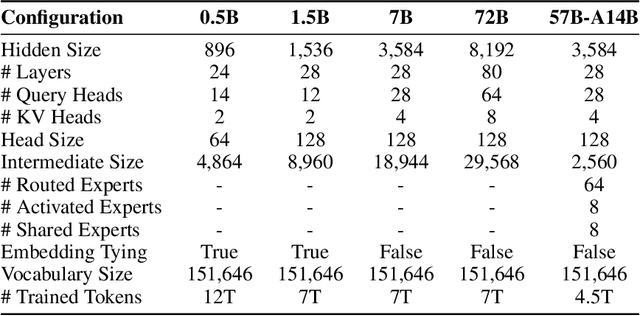
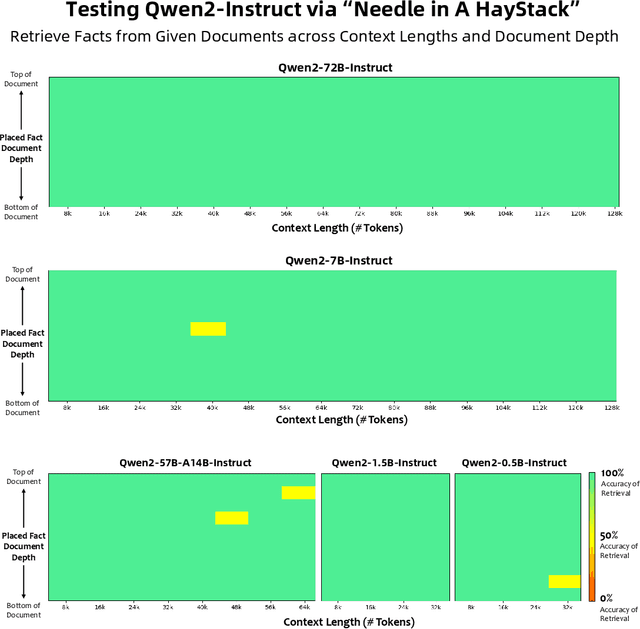
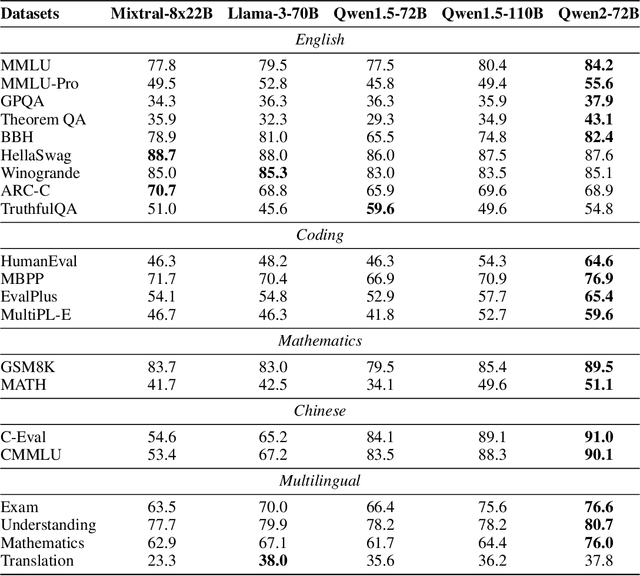
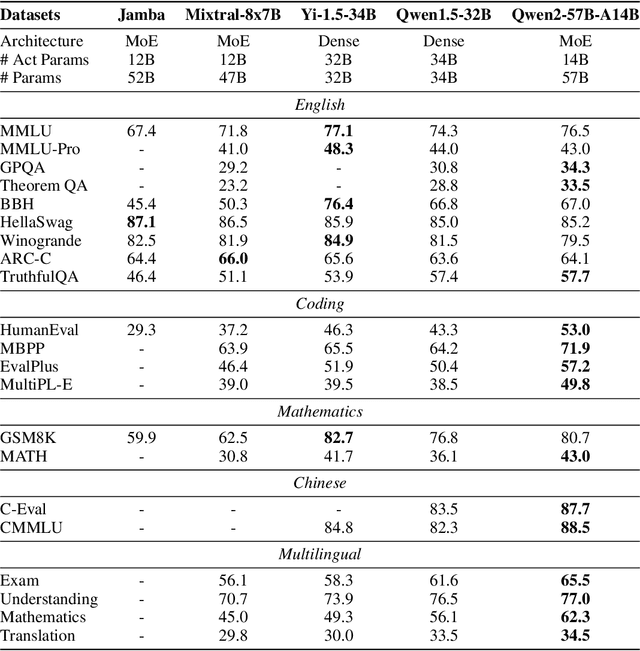
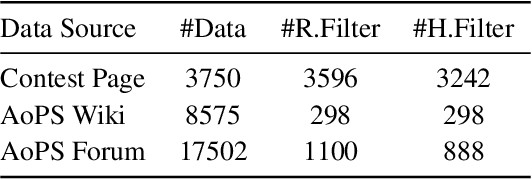
This report introduces the Qwen2 series, the latest addition to our large language models and large multimodal models. We release a comprehensive suite of foundational and instruction-tuned language models, encompassing a parameter range from 0.5 to 72 billion, featuring dense models and a Mixture-of-Experts model. Qwen2 surpasses most prior open-weight models, including its predecessor Qwen1.5, and exhibits competitive performance relative to proprietary models across diverse benchmarks on language understanding, generation, multilingual proficiency, coding, mathematics, and reasoning. The flagship model, Qwen2-72B, showcases remarkable performance: 84.2 on MMLU, 37.9 on GPQA, 64.6 on HumanEval, 89.5 on GSM8K, and 82.4 on BBH as a base language model. The instruction-tuned variant, Qwen2-72B-Instruct, attains 9.1 on MT-Bench, 48.1 on Arena-Hard, and 35.7 on LiveCodeBench. Moreover, Qwen2 demonstrates robust multilingual capabilities, proficient in approximately 30 languages, spanning English, Chinese, Spanish, French, German, Arabic, Russian, Korean, Japanese, Thai, Vietnamese, and more, underscoring its versatility and global reach. To foster community innovation and accessibility, we have made the Qwen2 model weights openly available on Hugging Face and ModelScope, and the supplementary materials including example code on GitHub. These platforms also include resources for quantization, fine-tuning, and deployment, facilitating a wide range of applications and research endeavors.
Qwen Technical Report
Sep 28, 2023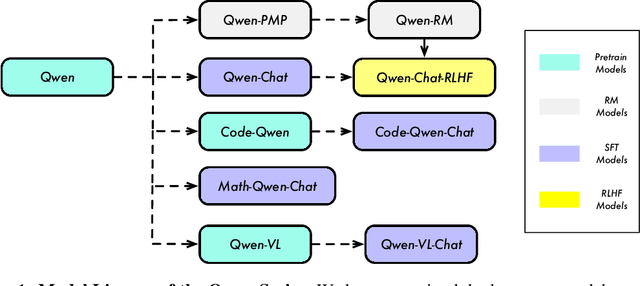

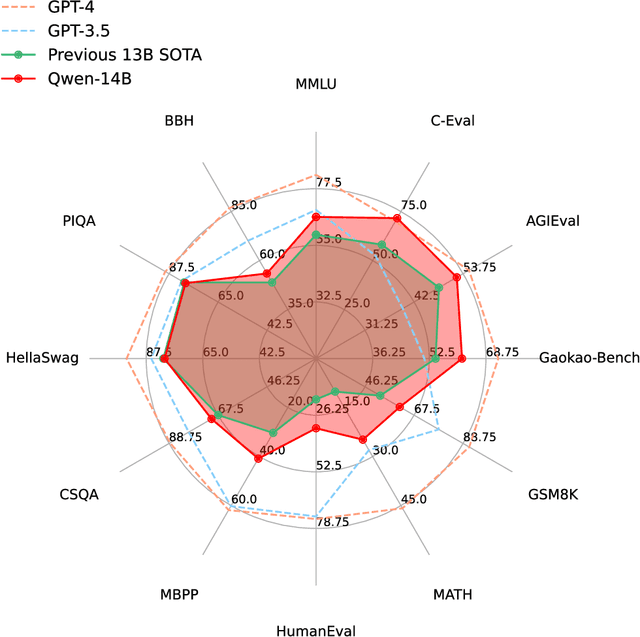
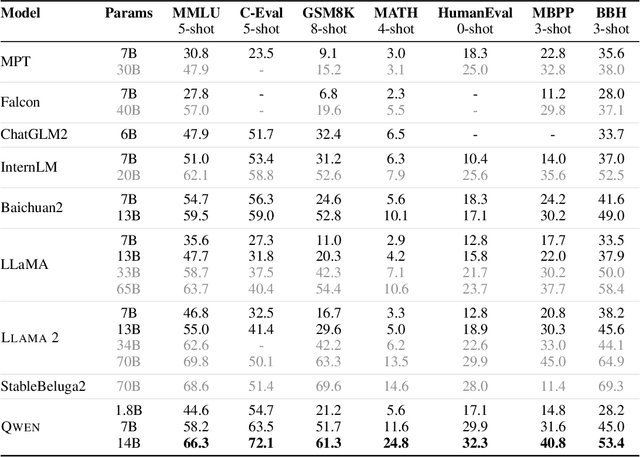
Large language models (LLMs) have revolutionized the field of artificial intelligence, enabling natural language processing tasks that were previously thought to be exclusive to humans. In this work, we introduce Qwen, the first installment of our large language model series. Qwen is a comprehensive language model series that encompasses distinct models with varying parameter counts. It includes Qwen, the base pretrained language models, and Qwen-Chat, the chat models finetuned with human alignment techniques. The base language models consistently demonstrate superior performance across a multitude of downstream tasks, and the chat models, particularly those trained using Reinforcement Learning from Human Feedback (RLHF), are highly competitive. The chat models possess advanced tool-use and planning capabilities for creating agent applications, showcasing impressive performance even when compared to bigger models on complex tasks like utilizing a code interpreter. Furthermore, we have developed coding-specialized models, Code-Qwen and Code-Qwen-Chat, as well as mathematics-focused models, Math-Qwen-Chat, which are built upon base language models. These models demonstrate significantly improved performance in comparison with open-source models, and slightly fall behind the proprietary models.
Transferring General Multimodal Pretrained Models to Text Recognition
Dec 19, 2022This paper proposes a new method, OFA-OCR, to transfer multimodal pretrained models to text recognition. Specifically, we recast text recognition as image captioning and directly transfer a unified vision-language pretrained model to the end task. Without pretraining on large-scale annotated or synthetic text recognition data, OFA-OCR outperforms the baselines and achieves state-of-the-art performance in the Chinese text recognition benchmark. Additionally, we construct an OCR pipeline with OFA-OCR, and we demonstrate that it can achieve competitive performance with the product-level API. The code (https://github.com/OFA-Sys/OFA) and demo (https://modelscope.cn/studios/damo/ofa_ocr_pipeline/summary) are publicly available.