 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMathMixup: Boosting LLM Mathematical Reasoning with Difficulty-Controllable Data Synthesis and Curriculum Learning
Jan 14, 2026In mathematical reasoning tasks, the advancement of Large Language Models (LLMs) relies heavily on high-quality training data with clearly defined and well-graded difficulty levels. However, existing data synthesis methods often suffer from limited diversity and lack precise control over problem difficulty, making them insufficient for supporting efficient training paradigms such as curriculum learning. To address these challenges, we propose MathMixup, a novel data synthesis paradigm that systematically generates high-quality, difficulty-controllable mathematical reasoning problems through hybrid and decomposed strategies. Automated self-checking and manual screening are incorporated to ensure semantic clarity and a well-structured difficulty gradient in the synthesized data. Building on this, we construct the MathMixupQA dataset and design a curriculum learning strategy that leverages these graded problems, supporting flexible integration with other datasets. Experimental results show that MathMixup and its curriculum learning strategy significantly enhance the mathematical reasoning performance of LLMs. Fine-tuned Qwen2.5-7B achieves an average score of 52.6\% across seven mathematical benchmarks, surpassing previous state-of-the-art methods. These results fully validate the effectiveness and broad applicability of MathMixup in improving the mathematical reasoning abilities of LLMs and advancing data-centric curriculum learning.
TiKMiX: Take Data Influence into Dynamic Mixture for Language Model Pre-training
Aug 25, 2025The data mixture used in the pre-training of a language model is a cornerstone of its final performance. However, a static mixing strategy is suboptimal, as the model's learning preferences for various data domains shift dynamically throughout training. Crucially, observing these evolving preferences in a computationally efficient manner remains a significant challenge. To address this, we propose TiKMiX, a method that dynamically adjusts the data mixture according to the model's evolving preferences. TiKMiX introduces Group Influence, an efficient metric for evaluating the impact of data domains on the model. This metric enables the formulation of the data mixing problem as a search for an optimal, influence-maximizing distribution. We solve this via two approaches: TiKMiX-D for direct optimization, and TiKMiX-M, which uses a regression model to predict a superior mixture. We trained models with different numbers of parameters, on up to 1 trillion tokens. TiKMiX-D exceeds the performance of state-of-the-art methods like REGMIX while using just 20% of the computational resources. TiKMiX-M leads to an average performance gain of 2% across 9 downstream benchmarks. Our experiments reveal that a model's data preferences evolve with training progress and scale, and we demonstrate that dynamically adjusting the data mixture based on Group Influence, a direct measure of these preferences, significantly improves performance by mitigating the underdigestion of data seen with static ratios.
QuaDMix: Quality-Diversity Balanced Data Selection for Efficient LLM Pretraining
Apr 23, 2025
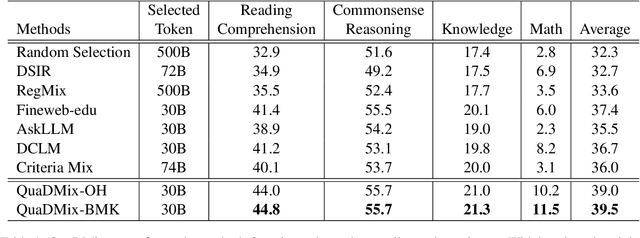
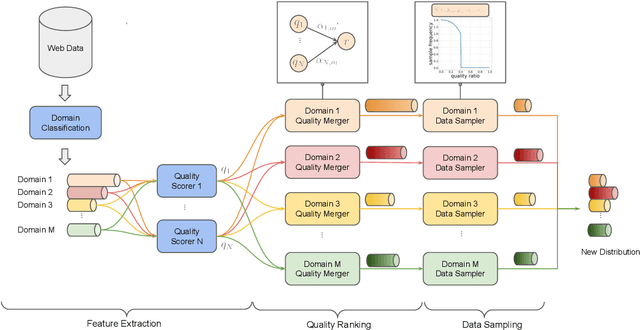

Quality and diversity are two critical metrics for the training data of large language models (LLMs), positively impacting performance. Existing studies often optimize these metrics separately, typically by first applying quality filtering and then adjusting data proportions. However, these approaches overlook the inherent trade-off between quality and diversity, necessitating their joint consideration. Given a fixed training quota, it is essential to evaluate both the quality of each data point and its complementary effect on the overall dataset. In this paper, we introduce a unified data selection framework called QuaDMix, which automatically optimizes the data distribution for LLM pretraining while balancing both quality and diversity. Specifically, we first propose multiple criteria to measure data quality and employ domain classification to distinguish data points, thereby measuring overall diversity. QuaDMix then employs a unified parameterized data sampling function that determines the sampling probability of each data point based on these quality and diversity related labels. To accelerate the search for the optimal parameters involved in the QuaDMix framework, we conduct simulated experiments on smaller models and use LightGBM for parameters searching, inspired by the RegMix method. Our experiments across diverse models and datasets demonstrate that QuaDMix achieves an average performance improvement of 7.2% across multiple benchmarks. These results outperform the independent strategies for quality and diversity, highlighting the necessity and ability to balance data quality and diversity.
YuE: Scaling Open Foundation Models for Long-Form Music Generation
Mar 11, 2025We tackle the task of long-form music generation--particularly the challenging \textbf{lyrics-to-song} problem--by introducing YuE, a family of open foundation models based on the LLaMA2 architecture. Specifically, YuE scales to trillions of tokens and generates up to five minutes of music while maintaining lyrical alignment, coherent musical structure, and engaging vocal melodies with appropriate accompaniment. It achieves this through (1) track-decoupled next-token prediction to overcome dense mixture signals, (2) structural progressive conditioning for long-context lyrical alignment, and (3) a multitask, multiphase pre-training recipe to converge and generalize. In addition, we redesign the in-context learning technique for music generation, enabling versatile style transfer (e.g., converting Japanese city pop into an English rap while preserving the original accompaniment) and bidirectional generation. Through extensive evaluation, we demonstrate that YuE matches or even surpasses some of the proprietary systems in musicality and vocal agility. In addition, fine-tuning YuE enables additional controls and enhanced support for tail languages. Furthermore, beyond generation, we show that YuE's learned representations can perform well on music understanding tasks, where the results of YuE match or exceed state-of-the-art methods on the MARBLE benchmark. Keywords: lyrics2song, song generation, long-form, foundation model, music generation
Qwen2 Technical Report
Jul 16, 2024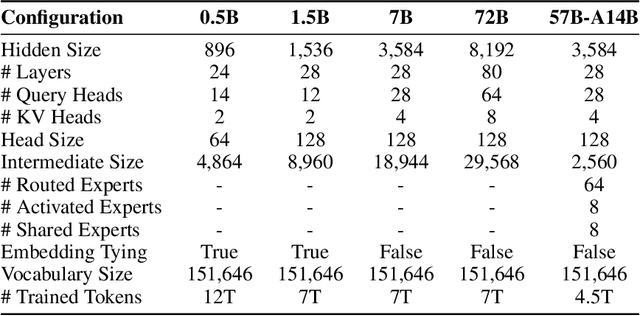
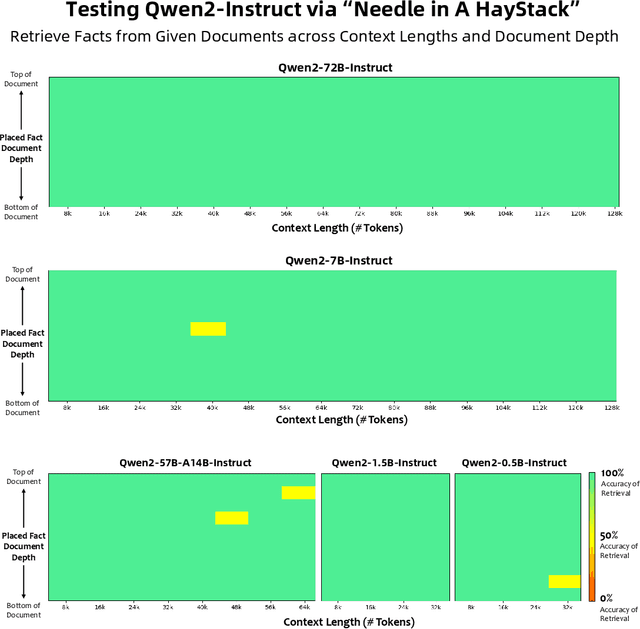
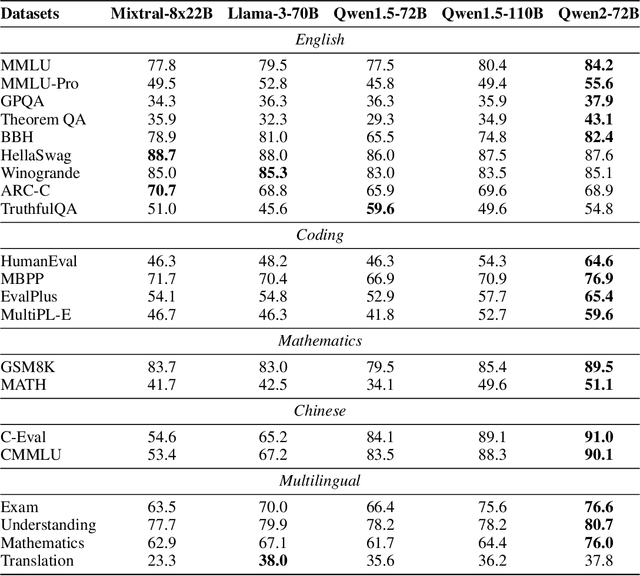
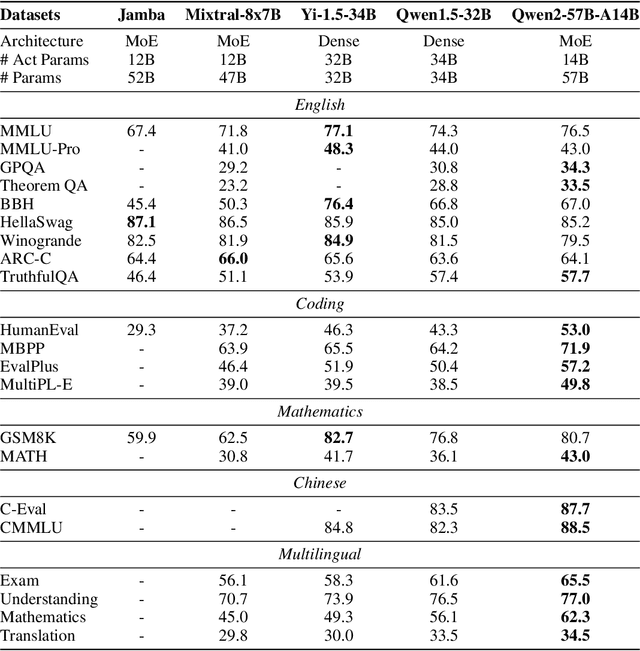
This report introduces the Qwen2 series, the latest addition to our large language models and large multimodal models. We release a comprehensive suite of foundational and instruction-tuned language models, encompassing a parameter range from 0.5 to 72 billion, featuring dense models and a Mixture-of-Experts model. Qwen2 surpasses most prior open-weight models, including its predecessor Qwen1.5, and exhibits competitive performance relative to proprietary models across diverse benchmarks on language understanding, generation, multilingual proficiency, coding, mathematics, and reasoning. The flagship model, Qwen2-72B, showcases remarkable performance: 84.2 on MMLU, 37.9 on GPQA, 64.6 on HumanEval, 89.5 on GSM8K, and 82.4 on BBH as a base language model. The instruction-tuned variant, Qwen2-72B-Instruct, attains 9.1 on MT-Bench, 48.1 on Arena-Hard, and 35.7 on LiveCodeBench. Moreover, Qwen2 demonstrates robust multilingual capabilities, proficient in approximately 30 languages, spanning English, Chinese, Spanish, French, German, Arabic, Russian, Korean, Japanese, Thai, Vietnamese, and more, underscoring its versatility and global reach. To foster community innovation and accessibility, we have made the Qwen2 model weights openly available on Hugging Face and ModelScope, and the supplementary materials including example code on GitHub. These platforms also include resources for quantization, fine-tuning, and deployment, facilitating a wide range of applications and research endeavors.
AIR-Bench: Benchmarking Large Audio-Language Models via Generative Comprehension
Feb 12, 2024



Recently, instruction-following audio-language models have received broad attention for human-audio interaction. However, the absence of benchmarks capable of evaluating audio-centric interaction capabilities has impeded advancements in this field. Previous models primarily focus on assessing different fundamental tasks, such as Automatic Speech Recognition (ASR), and lack an assessment of the open-ended generative capabilities centered around audio. Thus, it is challenging to track the progression in the Large Audio-Language Models (LALMs) domain and to provide guidance for future improvement. In this paper, we introduce AIR-Bench (\textbf{A}udio \textbf{I}nst\textbf{R}uction \textbf{Bench}mark), the first benchmark designed to evaluate the ability of LALMs to understand various types of audio signals (including human speech, natural sounds, and music), and furthermore, to interact with humans in the textual format. AIR-Bench encompasses two dimensions: \textit{foundation} and \textit{chat} benchmarks. The former consists of 19 tasks with approximately 19k single-choice questions, intending to inspect the basic single-task ability of LALMs. The latter one contains 2k instances of open-ended question-and-answer data, directly assessing the comprehension of the model on complex audio and its capacity to follow instructions. Both benchmarks require the model to generate hypotheses directly. We design a unified framework that leverages advanced language models, such as GPT-4, to evaluate the scores of generated hypotheses given the meta-information of the audio. Experimental results demonstrate a high level of consistency between GPT-4-based evaluation and human evaluation. By revealing the limitations of existing LALMs through evaluation results, AIR-Bench can provide insights into the direction of future research.
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Nov 14, 2023



Recently, instruction-following audio-language models have received broad attention for audio interaction with humans. However, the absence of pre-trained audio models capable of handling diverse audio types and tasks has hindered progress in this field. Consequently, most existing works have only been able to support a limited range of interaction capabilities. In this paper, we develop the Qwen-Audio model and address this limitation by scaling up audio-language pre-training to cover over 30 tasks and various audio types, such as human speech, natural sounds, music, and songs, to facilitate universal audio understanding abilities. However, directly co-training all tasks and datasets can lead to interference issues, as the textual labels associated with different datasets exhibit considerable variations due to differences in task focus, language, granularity of annotation, and text structure. To overcome the one-to-many interference, we carefully design a multi-task training framework by conditioning on a sequence of hierarchical tags to the decoder for encouraging knowledge sharing and avoiding interference through shared and specified tags respectively. Remarkably, Qwen-Audio achieves impressive performance across diverse benchmark tasks without requiring any task-specific fine-tuning, surpassing its counterparts. Building upon the capabilities of Qwen-Audio, we further develop Qwen-Audio-Chat, which allows for input from various audios and text inputs, enabling multi-turn dialogues and supporting various audio-central scenarios.
LauraGPT: Listen, Attend, Understand, and Regenerate Audio with GPT
Oct 11, 2023



Generative Pre-trained Transformer (GPT) models have achieved remarkable performance on various natural language processing tasks. However, there has been limited research on applying similar frameworks to audio tasks. Previously proposed large language models for audio tasks either lack sufficient quantitative evaluations, or are limited to tasks for recognizing and understanding audio content, or significantly underperform existing state-of-the-art (SOTA) models. In this paper, we propose LauraGPT, a unified GPT model for audio recognition, understanding, and generation. LauraGPT is a versatile language model that can process both audio and text inputs and generate outputs in either modalities. It can perform a wide range of tasks related to content, semantics, paralinguistics, and audio-signal analysis. Some of its noteworthy tasks include automatic speech recognition, speech-to-text translation, text-to-speech synthesis, machine translation, speech enhancement, automated audio captioning, speech emotion recognition, and spoken language understanding. To achieve this goal, we use a combination of continuous and discrete features for audio. We encode input audio into continuous representations using an audio encoder and decode output audio from discrete codec codes. We then fine-tune a large decoder-only Transformer-based language model on multiple audio-to-text, text-to-audio, audio-to-audio, and text-to-text tasks using a supervised multitask learning approach. Extensive experiments show that LauraGPT achieves competitive or superior performance compared to existing SOTA models on various audio processing benchmarks.
Qwen Technical Report
Sep 28, 2023

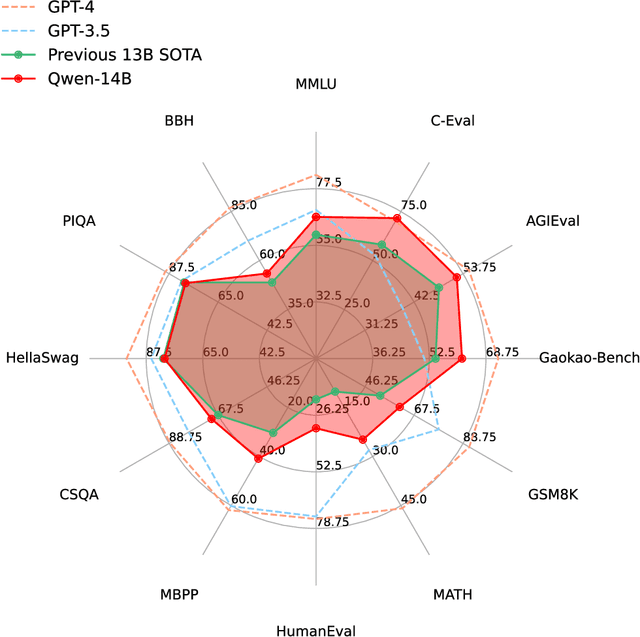
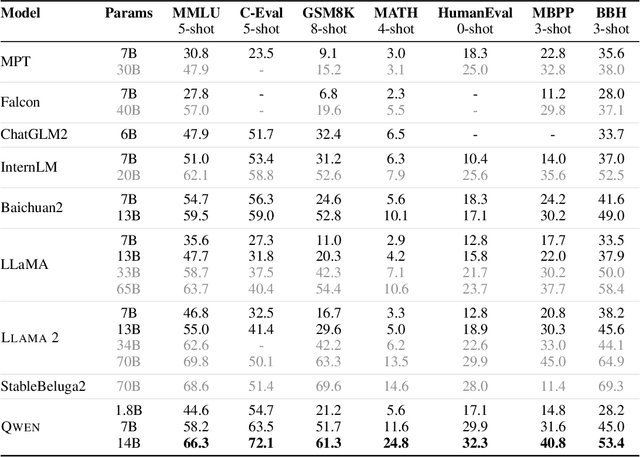
Large language models (LLMs) have revolutionized the field of artificial intelligence, enabling natural language processing tasks that were previously thought to be exclusive to humans. In this work, we introduce Qwen, the first installment of our large language model series. Qwen is a comprehensive language model series that encompasses distinct models with varying parameter counts. It includes Qwen, the base pretrained language models, and Qwen-Chat, the chat models finetuned with human alignment techniques. The base language models consistently demonstrate superior performance across a multitude of downstream tasks, and the chat models, particularly those trained using Reinforcement Learning from Human Feedback (RLHF), are highly competitive. The chat models possess advanced tool-use and planning capabilities for creating agent applications, showcasing impressive performance even when compared to bigger models on complex tasks like utilizing a code interpreter. Furthermore, we have developed coding-specialized models, Code-Qwen and Code-Qwen-Chat, as well as mathematics-focused models, Math-Qwen-Chat, which are built upon base language models. These models demonstrate significantly improved performance in comparison with open-source models, and slightly fall behind the proprietary models.
ONE-PEACE: Exploring One General Representation Model Toward Unlimited Modalities
May 18, 2023



In this work, we explore a scalable way for building a general representation model toward unlimited modalities. We release ONE-PEACE, a highly extensible model with 4B parameters that can seamlessly align and integrate representations across vision, audio, and language modalities. The architecture of ONE-PEACE comprises modality adapters, shared self-attention layers, and modality FFNs. This design allows for the easy extension of new modalities by adding adapters and FFNs, while also enabling multi-modal fusion through self-attention layers. To pretrain ONE-PEACE, we develop two modality-agnostic pretraining tasks, cross-modal aligning contrast and intra-modal denoising contrast, which align the semantic space of different modalities and capture fine-grained details within modalities concurrently. With the scaling-friendly architecture and pretraining tasks, ONE-PEACE has the potential to expand to unlimited modalities. Without using any vision or language pretrained model for initialization, ONE-PEACE achieves leading results on a wide range of uni-modal and multi-modal tasks, including image classification (ImageNet), semantic segmentation (ADE20K), audio-text retrieval (AudioCaps, Clotho), audio classification (ESC-50, FSD50K, VGGSound), audio question answering (AVQA), image-text retrieval (MSCOCO, Flickr30K), and visual grounding (RefCOCO/+/g). Code is available at https://github.com/OFA-Sys/ONE-PEACE.