 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREGen: Multimodal Retrieval-Embedded Generation for Long-to-Short Video Editing
May 24, 2025Short videos are an effective tool for promoting contents and improving knowledge accessibility. While existing extractive video summarization methods struggle to produce a coherent narrative, existing abstractive methods cannot `quote' from the input videos, i.e., inserting short video clips in their outputs. In this work, we explore novel video editing models for generating shorts that feature a coherent narrative with embedded video insertions extracted from a long input video. We propose a novel retrieval-embedded generation framework that allows a large language model to quote multimodal resources while maintaining a coherent narrative. Our proposed REGen system first generates the output story script with quote placeholders using a finetuned large language model, and then uses a novel retrieval model to replace the quote placeholders by selecting a video clip that best supports the narrative from a pool of candidate quotable video clips. We examine the proposed method on the task of documentary teaser generation, where short interview insertions are commonly used to support the narrative of a documentary. Our objective evaluations show that the proposed method can effectively insert short video clips while maintaining a coherent narrative. In a subjective survey, we show that our proposed method outperforms existing abstractive and extractive approaches in terms of coherence, alignment, and realism in teaser generation.
YuE: Scaling Open Foundation Models for Long-Form Music Generation
Mar 11, 2025We tackle the task of long-form music generation--particularly the challenging \textbf{lyrics-to-song} problem--by introducing YuE, a family of open foundation models based on the LLaMA2 architecture. Specifically, YuE scales to trillions of tokens and generates up to five minutes of music while maintaining lyrical alignment, coherent musical structure, and engaging vocal melodies with appropriate accompaniment. It achieves this through (1) track-decoupled next-token prediction to overcome dense mixture signals, (2) structural progressive conditioning for long-context lyrical alignment, and (3) a multitask, multiphase pre-training recipe to converge and generalize. In addition, we redesign the in-context learning technique for music generation, enabling versatile style transfer (e.g., converting Japanese city pop into an English rap while preserving the original accompaniment) and bidirectional generation. Through extensive evaluation, we demonstrate that YuE matches or even surpasses some of the proprietary systems in musicality and vocal agility. In addition, fine-tuning YuE enables additional controls and enhanced support for tail languages. Furthermore, beyond generation, we show that YuE's learned representations can perform well on music understanding tasks, where the results of YuE match or exceed state-of-the-art methods on the MARBLE benchmark. Keywords: lyrics2song, song generation, long-form, foundation model, music generation
DouZero: Mastering DouDizhu with Self-Play Deep Reinforcement Learning
Jun 11, 2021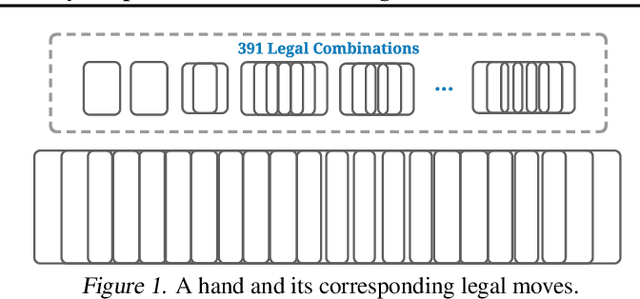
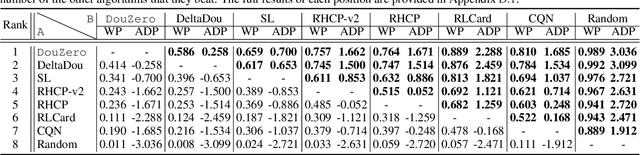
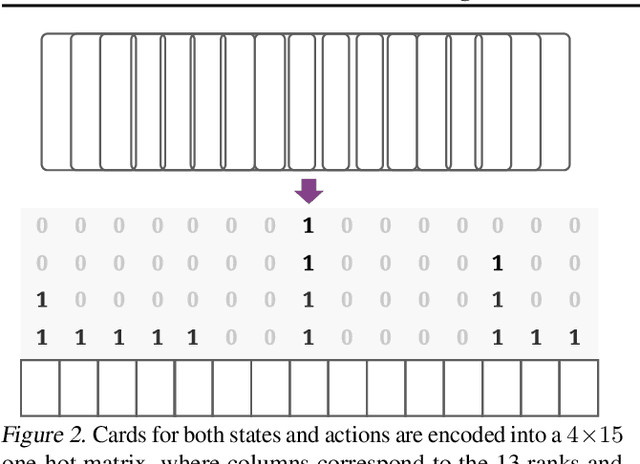

Games are abstractions of the real world, where artificial agents learn to compete and cooperate with other agents. While significant achievements have been made in various perfect- and imperfect-information games, DouDizhu (a.k.a. Fighting the Landlord), a three-player card game, is still unsolved. DouDizhu is a very challenging domain with competition, collaboration, imperfect information, large state space, and particularly a massive set of possible actions where the legal actions vary significantly from turn to turn. Unfortunately, modern reinforcement learning algorithms mainly focus on simple and small action spaces, and not surprisingly, are shown not to make satisfactory progress in DouDizhu. In this work, we propose a conceptually simple yet effective DouDizhu AI system, namely DouZero, which enhances traditional Monte-Carlo methods with deep neural networks, action encoding, and parallel actors. Starting from scratch in a single server with four GPUs, DouZero outperformed all the existing DouDizhu AI programs in days of training and was ranked the first in the Botzone leaderboard among 344 AI agents. Through building DouZero, we show that classic Monte-Carlo methods can be made to deliver strong results in a hard domain with a complex action space. The code and an online demo are released at https://github.com/kwai/DouZero with the hope that this insight could motivate future work.
Rank the Episodes: A Simple Approach for Exploration in Procedurally-Generated Environments
Feb 04, 2021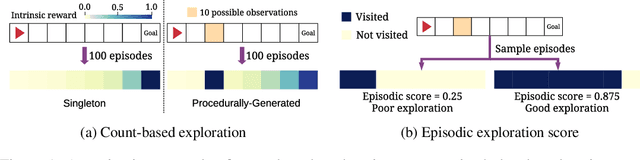
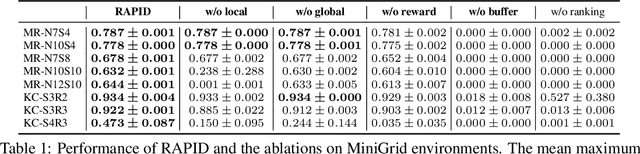
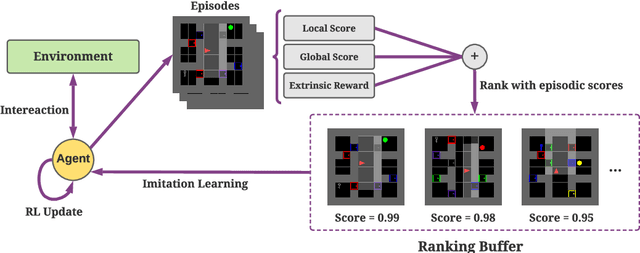

Exploration under sparse reward is a long-standing challenge of model-free reinforcement learning. The state-of-the-art methods address this challenge by introducing intrinsic rewards to encourage exploration in novel states or uncertain environment dynamics. Unfortunately, methods based on intrinsic rewards often fall short in procedurally-generated environments, where a different environment is generated in each episode so that the agent is not likely to visit the same state more than once. Motivated by how humans distinguish good exploration behaviors by looking into the entire episode, we introduce RAPID, a simple yet effective episode-level exploration method for procedurally-generated environments. RAPID regards each episode as a whole and gives an episodic exploration score from both per-episode and long-term views. Those highly scored episodes are treated as good exploration behaviors and are stored in a small ranking buffer. The agent then imitates the episodes in the buffer to reproduce the past good exploration behaviors. We demonstrate our method on several procedurally-generated MiniGrid environments, a first-person-view 3D Maze navigation task from MiniWorld, and several sparse MuJoCo tasks. The results show that RAPID significantly outperforms the state-of-the-art intrinsic reward strategies in terms of sample efficiency and final performance. The code is available at https://github.com/daochenzha/rapid
AdnFM: An Attentive DenseNet based Factorization Machine for CTR Prediction
Dec 20, 2020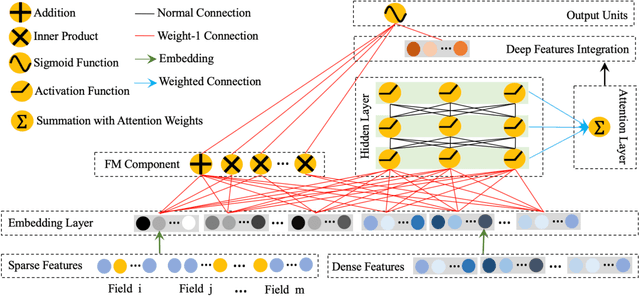
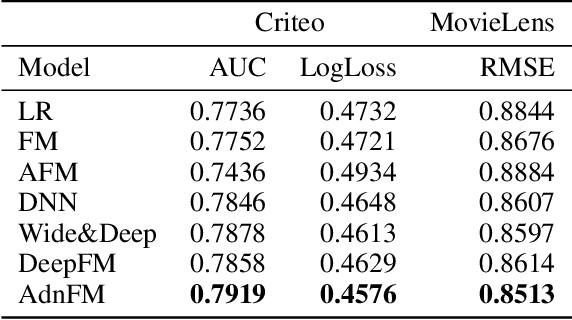
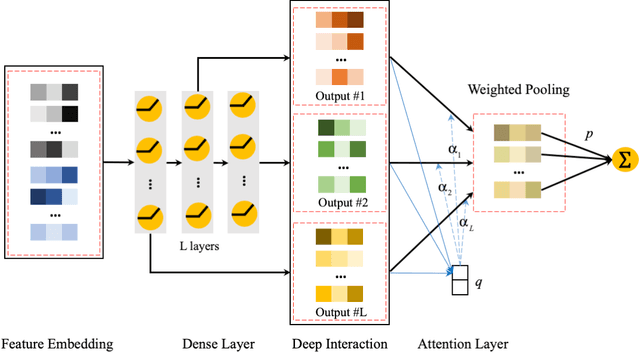
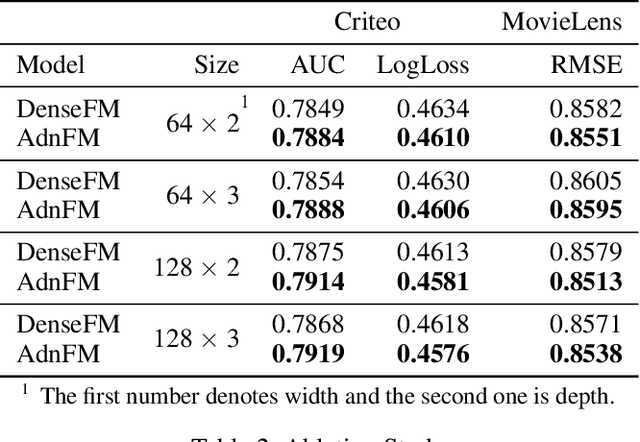
In this paper, we consider the Click-Through-Rate (CTR) prediction problem. Factorization Machines and their variants consider pair-wise feature interactions, but normally we won't do high-order feature interactions using FM due to high time complexity. Given the success of deep neural networks (DNNs) in many fields, researchers have proposed several DNN-based models to learn high-order feature interactions. Multi-layer perceptrons (MLP) have been widely employed to learn reliable mappings from feature embeddings to final logits. In this paper, we aim to explore more about these high-order features interactions. However, high-order feature interaction deserves more attention and further development. Inspired by the great achievements of Densely Connected Convolutional Networks (DenseNet) in computer vision, we propose a novel model called Attentive DenseNet based Factorization Machines (AdnFM). AdnFM can extract more comprehensive deep features by using all the hidden layers from a feed-forward neural network as implicit high-order features, then selects dominant features via an attention mechanism. Also, high-order interactions in the implicit way using DNNs are more cost-efficient than in the explicit way, for example in FM. Extensive experiments on two real-world datasets show that the proposed model can effectively improve the performance of CTR prediction.
Projective Quadratic Regression for Online Learning
Nov 25, 2019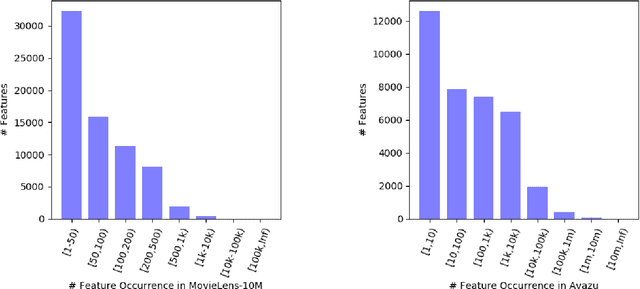


This paper considers online convex optimization (OCO) problems - the paramount framework for online learning algorithm design. The loss function of learning task in OCO setting is based on streaming data so that OCO is a powerful tool to model large scale applications such as online recommender systems. Meanwhile, real-world data are usually of extreme high-dimensional due to modern feature engineering techniques so that the quadratic regression is impractical. Factorization Machine as well as its variants are efficient models for capturing feature interactions with low-rank matrix model but they can't fulfill the OCO setting due to their non-convexity. In this paper, We propose a projective quadratic regression (PQR) model. First, it can capture the import second-order feature information. Second, it is a convex model, so the requirements of OCO are fulfilled and the global optimal solution can be achieved. Moreover, existing modern online optimization methods such as Online Gradient Descent (OGD) or Follow-The-Regularized-Leader (FTRL) can be applied directly. In addition, by choosing a proper hyper-parameter, we show that it has the same order of space and time complexity as the linear model and thus can handle high-dimensional data. Experimental results demonstrate the performance of the proposed PQR model in terms of accuracy and efficiency by comparing with the state-of-the-art methods.
RaFM: Rank-Aware Factorization Machines
May 18, 2019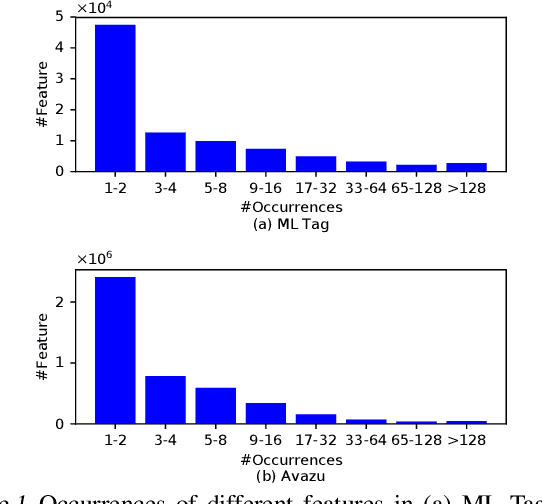

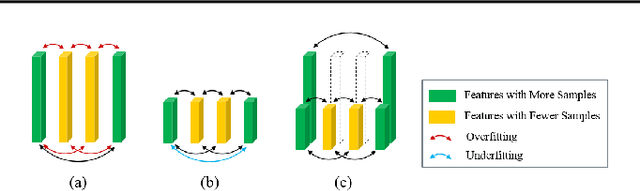
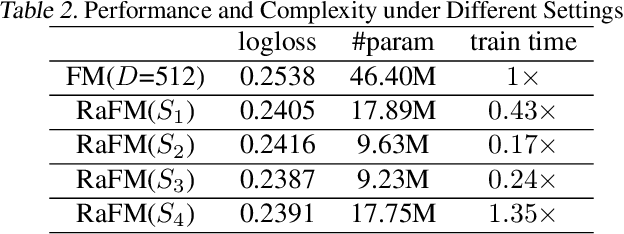
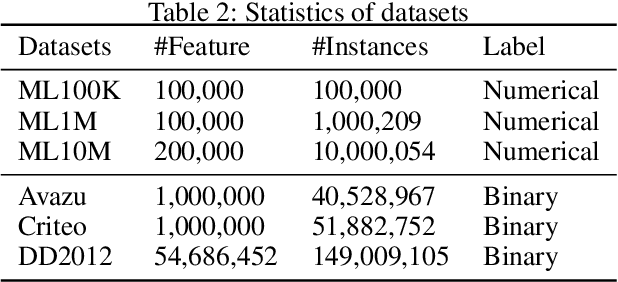
Factorization machines (FM) are a popular model class to learn pairwise interactions by a low-rank approximation. Different from existing FM-based approaches which use a fixed rank for all features, this paper proposes a Rank-Aware FM (RaFM) model which adopts pairwise interactions from embeddings with different ranks. The proposed model achieves a better performance on real-world datasets where different features have significantly varying frequencies of occurrences. Moreover, we prove that the RaFM model can be stored, evaluated, and trained as efficiently as one single FM, and under some reasonable conditions it can be even significantly more efficient than FM. RaFM improves the performance of FMs in both regression tasks and classification tasks while incurring less computational burden, therefore also has attractive potential in industrial applications.
Fast Single Image Reflection Suppression via Convex Optimization
Mar 10, 2019



Removing undesired reflections from images taken through the glass is of great importance in computer vision. It serves as a means to enhance the image quality for aesthetic purposes as well as to preprocess images in machine learning and pattern recognition applications. We propose a convex model to suppress the reflection from a single input image. Our model implies a partial differential equation with gradient thresholding, which is solved efficiently using Discrete Cosine Transform. Extensive experiments on synthetic and real-world images demonstrate that our approach achieves desirable reflection suppression results and dramatically reduces the execution time compared to the state of the art.