 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnmixing the Crowd: Learning Mixture-to-Set Speaker Embeddings for Enrollment-Free Target Speech Extraction
Apr 03, 2026Personalized or target speech extraction (TSE) typically needs a clean enrollment -- hard to obtain in real-world crowded environments. We remove the essential need for enrollment by predicting, from the mixture itself, a small set of per-speaker embeddings that serve as the control signal for extraction. Our model maps a noisy mixture directly to a small set of candidate speaker embeddings trained to align with a strong single-speaker speaker-embedding space via permutation-invariant teacher supervision. On noisy LibriMix, the resulting embeddings form a structured and clusterable identity space, outperforming WavLM+K-means and separation-derived embeddings in standard clustering metrics. Conditioning these embeddings into multiple extraction back-ends consistently improves objective quality and intelligibility, and generalizes to real DNS-Challenge recordings.
Video-Guided Text-to-Music Generation Using Public Domain Movie Collections
Jun 14, 2025Despite recent advancements in music generation systems, their application in film production remains limited, as they struggle to capture the nuances of real-world filmmaking, where filmmakers consider multiple factors-such as visual content, dialogue, and emotional tone-when selecting or composing music for a scene. This limitation primarily stems from the absence of comprehensive datasets that integrate these elements. To address this gap, we introduce Open Screen Sound Library (OSSL), a dataset consisting of movie clips from public domain films, totaling approximately 36.5 hours, paired with high-quality soundtracks and human-annotated mood information. To demonstrate the effectiveness of our dataset in improving the performance of pre-trained models on film music generation tasks, we introduce a new video adapter that enhances an autoregressive transformer-based text-to-music model by adding video-based conditioning. Our experimental results demonstrate that our proposed approach effectively enhances MusicGen-Medium in terms of both objective measures of distributional and paired fidelity, and subjective compatibility in mood and genre. The dataset and code are available at https://havenpersona.github.io/ossl-v1.
REGen: Multimodal Retrieval-Embedded Generation for Long-to-Short Video Editing
May 24, 2025Short videos are an effective tool for promoting contents and improving knowledge accessibility. While existing extractive video summarization methods struggle to produce a coherent narrative, existing abstractive methods cannot `quote' from the input videos, i.e., inserting short video clips in their outputs. In this work, we explore novel video editing models for generating shorts that feature a coherent narrative with embedded video insertions extracted from a long input video. We propose a novel retrieval-embedded generation framework that allows a large language model to quote multimodal resources while maintaining a coherent narrative. Our proposed REGen system first generates the output story script with quote placeholders using a finetuned large language model, and then uses a novel retrieval model to replace the quote placeholders by selecting a video clip that best supports the narrative from a pool of candidate quotable video clips. We examine the proposed method on the task of documentary teaser generation, where short interview insertions are commonly used to support the narrative of a documentary. Our objective evaluations show that the proposed method can effectively insert short video clips while maintaining a coherent narrative. In a subjective survey, we show that our proposed method outperforms existing abstractive and extractive approaches in terms of coherence, alignment, and realism in teaser generation.
Deriving Representative Structure from Music Corpora
Feb 21, 2025Western music is an innately hierarchical system of interacting levels of structure, from fine-grained melody to high-level form. In order to analyze music compositions holistically and at multiple granularities, we propose a unified, hierarchical meta-representation of musical structure called the structural temporal graph (STG). For a single piece, the STG is a data structure that defines a hierarchy of progressively finer structural musical features and the temporal relationships between them. We use the STG to enable a novel approach for deriving a representative structural summary of a music corpus, which we formalize as a dually NP-hard combinatorial optimization problem extending the Generalized Median Graph problem. Our approach first applies simulated annealing to develop a measure of structural distance between two music pieces rooted in graph isomorphism. Our approach then combines the formal guarantees of SMT solvers with nested simulated annealing over structural distances to produce a structurally sound, representative centroid STG for an entire corpus of STGs from individual pieces. To evaluate our approach, we conduct experiments verifying that structural distance accurately differentiates between music pieces, and that derived centroids accurately structurally characterize their corpora.
Generative AI for Music and Audio
Nov 21, 2024



Generative AI has been transforming the way we interact with technology and consume content. In the next decade, AI technology will reshape how we create audio content in various media, including music, theater, films, games, podcasts, and short videos. In this dissertation, I introduce the three main directions of my research centered around generative AI for music and audio: 1) multitrack music generation, 2) assistive music creation tools, and 3) multimodal learning for audio and music. Through my research, I aim to answer the following two fundamental questions: 1) How can AI help professionals or amateurs create music and audio content? 2) Can AI learn to create music in a way similar to how humans learn music? My long-term goal is to lower the barrier of entry for music composition and democratize audio content creation
TeaserGen: Generating Teasers for Long Documentaries
Oct 08, 2024

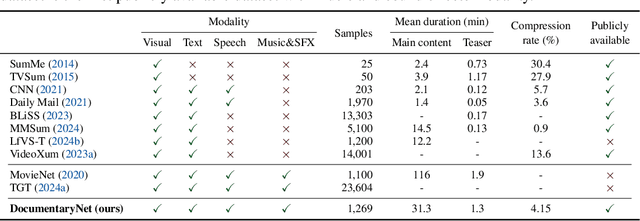
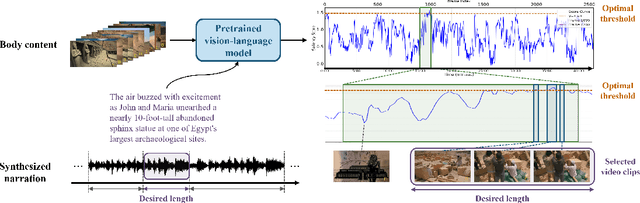
Teasers are an effective tool for promoting content in entertainment, commercial and educational fields. However, creating an effective teaser for long videos is challenging for it requires long-range multimodal modeling on the input videos, while necessitating maintaining audiovisual alignments, managing scene changes and preserving factual accuracy for the output teasers. Due to the lack of a publicly-available dataset, progress along this research direction has been hindered. In this work, we present DocumentaryNet, a collection of 1,269 documentaries paired with their teasers, featuring multimodal data streams of video, speech, music, sound effects and narrations. With DocumentaryNet, we propose a new two-stage system for generating teasers from long documentaries. The proposed TeaserGen system first generates the teaser narration from the transcribed narration of the documentary using a pretrained large language model, and then selects the most relevant visual content to accompany the generated narration through language-vision models. For narration-video matching, we explore two approaches: a pretraining-based model using pretrained contrastive language-vision models and a deep sequential model that learns the mapping between the narrations and visuals. Our experimental results show that the pretraining-based approach is more effective at identifying relevant visual content than directly trained deep autoregressive models.
Generating Symbolic Music from Natural Language Prompts using an LLM-Enhanced Dataset
Oct 02, 2024



Recent years have seen many audio-domain text-to-music generation models that rely on large amounts of text-audio pairs for training. However, symbolic-domain controllable music generation has lagged behind partly due to the lack of a large-scale symbolic music dataset with extensive metadata and captions. In this work, we present MetaScore, a new dataset consisting of 963K musical scores paired with rich metadata, including free-form user-annotated tags, collected from an online music forum. To approach text-to-music generation, we leverage a pretrained large language model (LLM) to generate pseudo natural language captions from the metadata. With the LLM-enhanced MetaScore, we train a text-conditioned music generation model that learns to generate symbolic music from the pseudo captions, allowing control of instruments, genre, composer, complexity and other free-form music descriptors. In addition, we train a tag-conditioned system that supports a predefined set of tags available in MetaScore. Our experimental results show that both the proposed text-to-music and tags-to-music models outperform a baseline text-to-music model in a listening test, while the text-based system offers a more natural interface that allows free-form natural language prompts.
Nested Music Transformer: Sequentially Decoding Compound Tokens in Symbolic Music and Audio Generation
Aug 02, 2024



Representing symbolic music with compound tokens, where each token consists of several different sub-tokens representing a distinct musical feature or attribute, offers the advantage of reducing sequence length. While previous research has validated the efficacy of compound tokens in music sequence modeling, predicting all sub-tokens simultaneously can lead to suboptimal results as it may not fully capture the interdependencies between them. We introduce the Nested Music Transformer (NMT), an architecture tailored for decoding compound tokens autoregressively, similar to processing flattened tokens, but with low memory usage. The NMT consists of two transformers: the main decoder that models a sequence of compound tokens and the sub-decoder for modeling sub-tokens of each compound token. The experiment results showed that applying the NMT to compound tokens can enhance the performance in terms of better perplexity in processing various symbolic music datasets and discrete audio tokens from the MAESTRO dataset.
Futga: Towards Fine-grained Music Understanding through Temporally-enhanced Generative Augmentation
Jul 29, 2024



Existing music captioning methods are limited to generating concise global descriptions of short music clips, which fail to capture fine-grained musical characteristics and time-aware musical changes. To address these limitations, we propose FUTGA, a model equipped with fined-grained music understanding capabilities through learning from generative augmentation with temporal compositions. We leverage existing music caption datasets and large language models (LLMs) to synthesize fine-grained music captions with structural descriptions and time boundaries for full-length songs. Augmented by the proposed synthetic dataset, FUTGA is enabled to identify the music's temporal changes at key transition points and their musical functions, as well as generate detailed descriptions for each music segment. We further introduce a full-length music caption dataset generated by FUTGA, as the augmentation of the MusicCaps and the Song Describer datasets. We evaluate the automatically generated captions on several downstream tasks, including music generation and retrieval. The experiments demonstrate the quality of the generated captions and the better performance in various downstream tasks achieved by the proposed music captioning approach. Our code and datasets can be found in \href{https://huggingface.co/JoshuaW1997/FUTGA}{\textcolor{blue}{https://huggingface.co/JoshuaW1997/FUTGA}}.
Equipping Pretrained Unconditional Music Transformers with Instrument and Genre Controls
Nov 21, 2023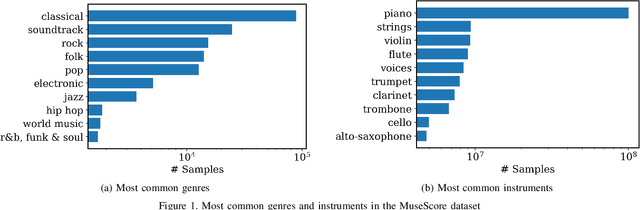
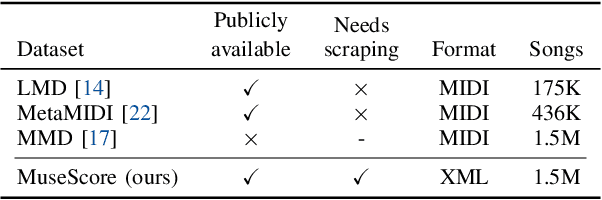

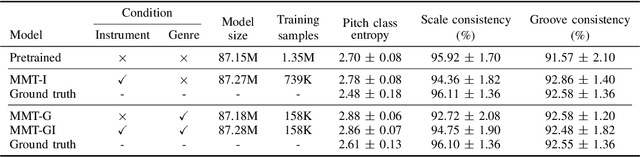
The ''pretraining-and-finetuning'' paradigm has become a norm for training domain-specific models in natural language processing and computer vision. In this work, we aim to examine this paradigm for symbolic music generation through leveraging the largest ever symbolic music dataset sourced from the MuseScore forum. We first pretrain a large unconditional transformer model using 1.5 million songs. We then propose a simple technique to equip this pretrained unconditional music transformer model with instrument and genre controls by finetuning the model with additional control tokens. Our proposed representation offers improved high-level controllability and expressiveness against two existing representations. The experimental results show that the proposed model can successfully generate music with user-specified instruments and genre. In a subjective listening test, the proposed model outperforms the pretrained baseline model in terms of coherence, harmony, arrangement and overall quality.