 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAP: Runtime-Adaptive Pruning for LLM Inference
May 26, 2025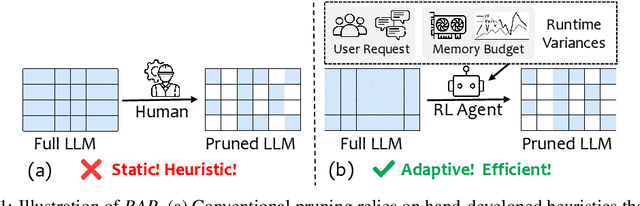

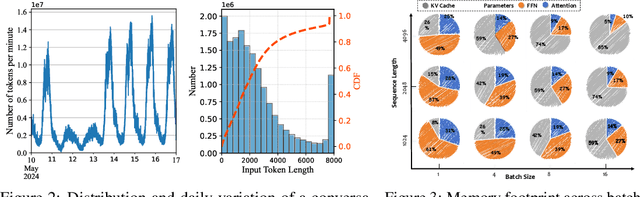

Large language models (LLMs) excel at language understanding and generation, but their enormous computational and memory requirements hinder deployment. Compression offers a potential solution to mitigate these constraints. However, most existing methods rely on fixed heuristics and thus fail to adapt to runtime memory variations or heterogeneous KV-cache demands arising from diverse user requests. To address these limitations, we propose RAP, an elastic pruning framework driven by reinforcement learning (RL) that dynamically adjusts compression strategies in a runtime-aware manner. Specifically, RAP dynamically tracks the evolving ratio between model parameters and KV-cache across practical execution. Recognizing that FFNs house most parameters, whereas parameter -light attention layers dominate KV-cache formation, the RL agent retains only those components that maximize utility within the current memory budget, conditioned on instantaneous workload and device state. Extensive experiments results demonstrate that RAP outperforms state-of-the-art baselines, marking the first time to jointly consider model weights and KV-cache on the fly.
Futga: Towards Fine-grained Music Understanding through Temporally-enhanced Generative Augmentation
Jul 29, 2024



Existing music captioning methods are limited to generating concise global descriptions of short music clips, which fail to capture fine-grained musical characteristics and time-aware musical changes. To address these limitations, we propose FUTGA, a model equipped with fined-grained music understanding capabilities through learning from generative augmentation with temporal compositions. We leverage existing music caption datasets and large language models (LLMs) to synthesize fine-grained music captions with structural descriptions and time boundaries for full-length songs. Augmented by the proposed synthetic dataset, FUTGA is enabled to identify the music's temporal changes at key transition points and their musical functions, as well as generate detailed descriptions for each music segment. We further introduce a full-length music caption dataset generated by FUTGA, as the augmentation of the MusicCaps and the Song Describer datasets. We evaluate the automatically generated captions on several downstream tasks, including music generation and retrieval. The experiments demonstrate the quality of the generated captions and the better performance in various downstream tasks achieved by the proposed music captioning approach. Our code and datasets can be found in \href{https://huggingface.co/JoshuaW1997/FUTGA}{\textcolor{blue}{https://huggingface.co/JoshuaW1997/FUTGA}}.