 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Polyglot Harmony: On Multilingual Data Allocation for Large Language Models Pretraining
Sep 19, 2025Large language models (LLMs) have become integral to a wide range of applications worldwide, driving an unprecedented global demand for effective multilingual capabilities. Central to achieving robust multilingual performance is the strategic allocation of language proportions within training corpora. However, determining optimal language ratios is highly challenging due to intricate cross-lingual interactions and sensitivity to dataset scale. This paper introduces Climb (Cross-Lingual Interaction-aware Multilingual Balancing), a novel framework designed to systematically optimize multilingual data allocation. At its core, Climb introduces a cross-lingual interaction-aware language ratio, explicitly quantifying each language's effective allocation by capturing inter-language dependencies. Leveraging this ratio, Climb proposes a principled two-step optimization procedure--first equalizing marginal benefits across languages, then maximizing the magnitude of the resulting language allocation vectors--significantly simplifying the inherently complex multilingual optimization problem. Extensive experiments confirm that Climb can accurately measure cross-lingual interactions across various multilingual settings. LLMs trained with Climb-derived proportions consistently achieve state-of-the-art multilingual performance, even achieving competitive performance with open-sourced LLMs trained with more tokens.
MuRating: A High Quality Data Selecting Approach to Multilingual Large Language Model Pretraining
Jul 02, 2025Data quality is a critical driver of large language model performance, yet existing model-based selection methods focus almost exclusively on English. We introduce MuRating, a scalable framework that transfers high-quality English data-quality signals into a single rater for 17 target languages. MuRating aggregates multiple English "raters" via pairwise comparisons to learn unified document-quality scores,then projects these judgments through translation to train a multilingual evaluator on monolingual, cross-lingual, and parallel text pairs. Applied to web data, MuRating selects balanced subsets of English and multilingual content to pretrain a 1.2 B-parameter LLaMA model. Compared to strong baselines, including QuRater, AskLLM, DCLM and so on, our approach boosts average accuracy on both English benchmarks and multilingual evaluations, with especially large gains on knowledge-intensive tasks. We further analyze translation fidelity, selection biases, and underrepresentation of narrative material, outlining directions for future work.
MuBench: Assessment of Multilingual Capabilities of Large Language Models Across 61 Languages
Jun 24, 2025Multilingual large language models (LLMs) are advancing rapidly, with new models frequently claiming support for an increasing number of languages. However, existing evaluation datasets are limited and lack cross-lingual alignment, leaving assessments of multilingual capabilities fragmented in both language and skill coverage. To address this, we introduce MuBench, a benchmark covering 61 languages and evaluating a broad range of capabilities. We evaluate several state-of-the-art multilingual LLMs and find notable gaps between claimed and actual language coverage, particularly a persistent performance disparity between English and low-resource languages. Leveraging MuBench's alignment, we propose Multilingual Consistency (MLC) as a complementary metric to accuracy for analyzing performance bottlenecks and guiding model improvement. Finally, we pretrain a suite of 1.2B-parameter models on English and Chinese with 500B tokens, varying language ratios and parallel data proportions to investigate cross-lingual transfer dynamics.
MoORE: SVD-based Model MoE-ization for Conflict- and Oblivion-Resistant Multi-Task Adaptation
Jun 17, 2025Adapting large-scale foundation models in multi-task scenarios often suffers from task conflict and oblivion. To mitigate such issues, we propose a novel ''model MoE-ization'' strategy that leads to a conflict- and oblivion-resistant multi-task adaptation method. Given a weight matrix of a pre-trained model, our method applies SVD to it and introduces a learnable router to adjust its singular values based on tasks and samples. Accordingly, the weight matrix becomes a Mixture of Orthogonal Rank-one Experts (MoORE), in which each expert corresponds to the outer product of a left singular vector and the corresponding right one. We can improve the model capacity by imposing a learnable orthogonal transform on the right singular vectors. Unlike low-rank adaptation (LoRA) and its MoE-driven variants, MoORE guarantees the experts' orthogonality and maintains the column space of the original weight matrix. These two properties make the adapted model resistant to the conflicts among the new tasks and the oblivion of its original tasks, respectively. Experiments on various datasets demonstrate that MoORE outperforms existing multi-task adaptation methods consistently, showing its superiority in terms of conflict- and oblivion-resistance. The code of the experiments is available at https://github.com/DaShenZi721/MoORE.
Factorized-Dreamer: Training A High-Quality Video Generator with Limited and Low-Quality Data
Aug 19, 2024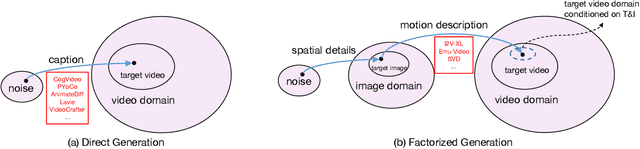
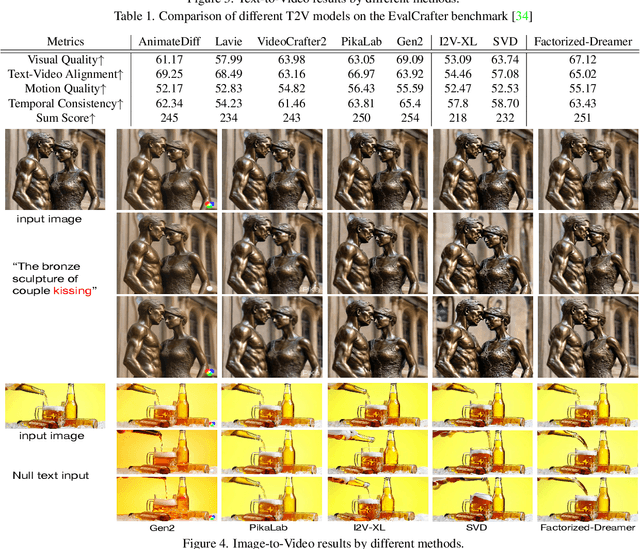
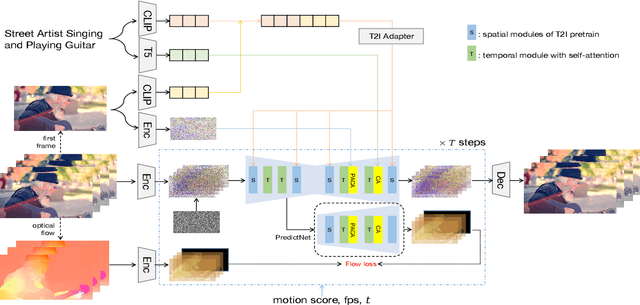

Text-to-video (T2V) generation has gained significant attention due to its wide applications to video generation, editing, enhancement and translation, \etc. However, high-quality (HQ) video synthesis is extremely challenging because of the diverse and complex motions existed in real world. Most existing works struggle to address this problem by collecting large-scale HQ videos, which are inaccessible to the community. In this work, we show that publicly available limited and low-quality (LQ) data are sufficient to train a HQ video generator without recaptioning or finetuning. We factorize the whole T2V generation process into two steps: generating an image conditioned on a highly descriptive caption, and synthesizing the video conditioned on the generated image and a concise caption of motion details. Specifically, we present \emph{Factorized-Dreamer}, a factorized spatiotemporal framework with several critical designs for T2V generation, including an adapter to combine text and image embeddings, a pixel-aware cross attention module to capture pixel-level image information, a T5 text encoder to better understand motion description, and a PredictNet to supervise optical flows. We further present a noise schedule, which plays a key role in ensuring the quality and stability of video generation. Our model lowers the requirements in detailed captions and HQ videos, and can be directly trained on limited LQ datasets with noisy and brief captions such as WebVid-10M, largely alleviating the cost to collect large-scale HQ video-text pairs. Extensive experiments in a variety of T2V and image-to-video generation tasks demonstrate the effectiveness of our proposed Factorized-Dreamer. Our source codes are available at \url{https://github.com/yangxy/Factorized-Dreamer/}.
Pareto-aware Neural Architecture Generation for Diverse Computational Budgets
Oct 14, 2022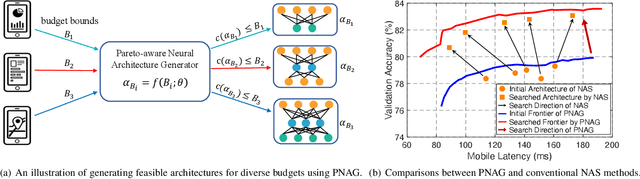
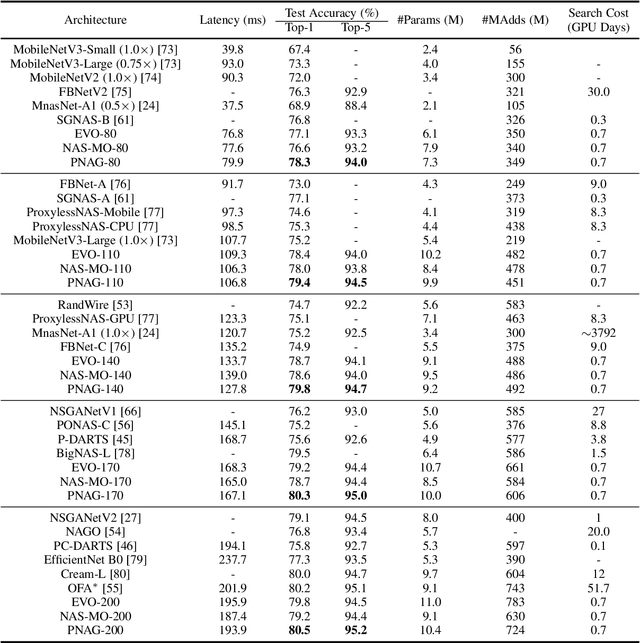
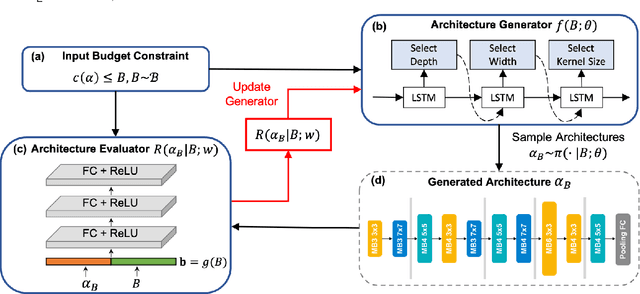
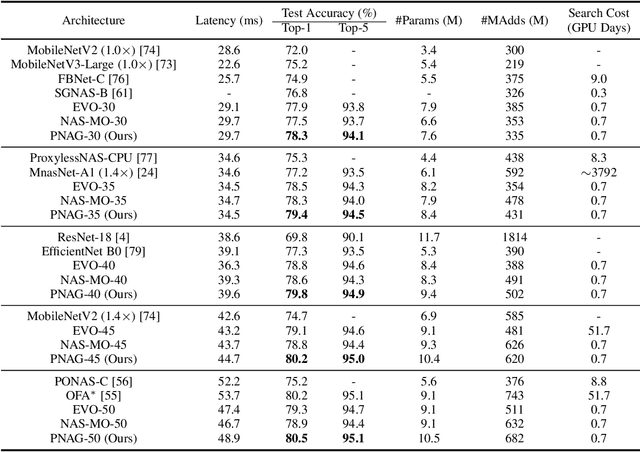
Designing feasible and effective architectures under diverse computational budgets, incurred by different applications/devices, is essential for deploying deep models in real-world applications. To achieve this goal, existing methods often perform an independent architecture search process for each target budget, which is very inefficient yet unnecessary. More critically, these independent search processes cannot share their learned knowledge (i.e., the distribution of good architectures) with each other and thus often result in limited search results. To address these issues, we propose a Pareto-aware Neural Architecture Generator (PNAG) which only needs to be trained once and dynamically produces the Pareto optimal architecture for any given budget via inference. To train our PNAG, we learn the whole Pareto frontier by jointly finding multiple Pareto optimal architectures under diverse budgets. Such a joint search algorithm not only greatly reduces the overall search cost but also improves the search results. Extensive experiments on three hardware platforms (i.e., mobile device, CPU, and GPU) show the superiority of our method over existing methods.
Pareto-Frontier-aware Neural Architecture Generation for Diverse Budgets
Feb 27, 2021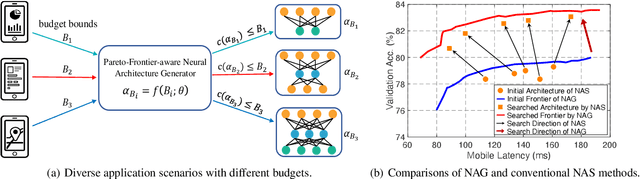
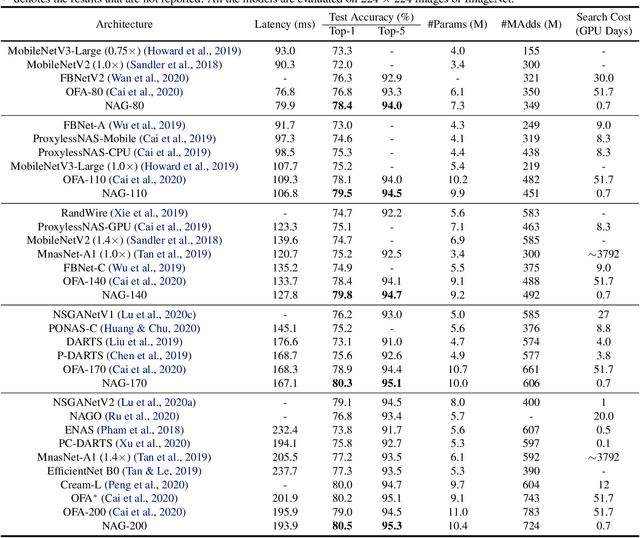
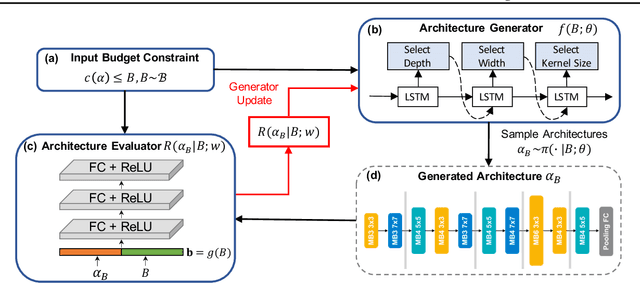

Designing feasible and effective architectures under diverse computation budgets incurred by different applications/devices is essential for deploying deep models in practice. Existing methods often perform an independent architecture search for each target budget, which is very inefficient yet unnecessary. Moreover, the repeated independent search manner would inevitably ignore the common knowledge among different search processes and hamper the search performance. To address these issues, we seek to train a general architecture generator that automatically produces effective architectures for an arbitrary budget merely via model inference. To this end, we propose a Pareto-Frontier-aware Neural Architecture Generator (NAG) which takes an arbitrary budget as input and produces the Pareto optimal architecture for the target budget. We train NAG by learning the Pareto frontier (i.e., the set of Pareto optimal architectures) over model performance and computational cost (e.g., latency). Extensive experiments on three platforms (i.e., mobile, CPU, and GPU) show the superiority of the proposed method over existing NAS methods.
Towards Accurate and Compact Architectures via Neural Architecture Transformer
Feb 20, 2021
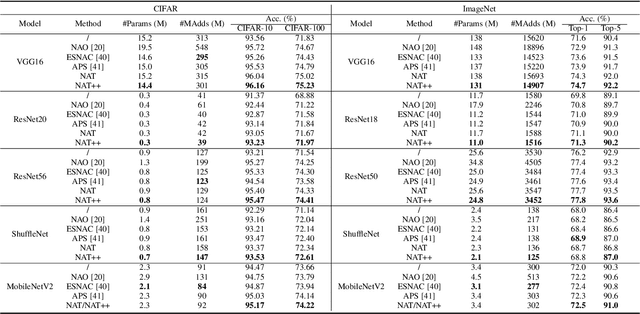
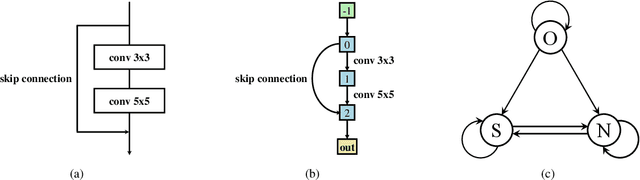
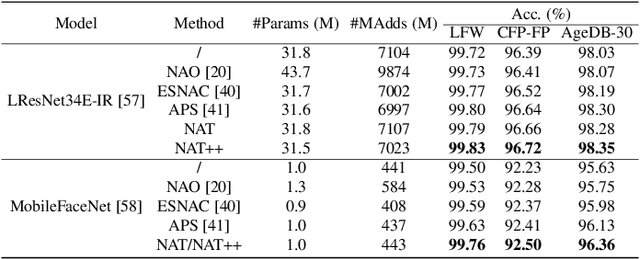
Designing effective architectures is one of the key factors behind the success of deep neural networks. Existing deep architectures are either manually designed or automatically searched by some Neural Architecture Search (NAS) methods. However, even a well-designed/searched architecture may still contain many nonsignificant or redundant modules/operations. Thus, it is necessary to optimize the operations inside an architecture to improve the performance without introducing extra computational cost. To this end, we have proposed a Neural Architecture Transformer (NAT) method which casts the optimization problem into a Markov Decision Process (MDP) and seeks to replace the redundant operations with more efficient operations, such as skip or null connection. Note that NAT only considers a small number of possible transitions and thus comes with a limited search/transition space. As a result, such a small search space may hamper the performance of architecture optimization. To address this issue, we propose a Neural Architecture Transformer++ (NAT++) method which further enlarges the set of candidate transitions to improve the performance of architecture optimization. Specifically, we present a two-level transition rule to obtain valid transitions, i.e., allowing operations to have more efficient types (e.g., convolution->separable convolution) or smaller kernel sizes (e.g., 5x5->3x3). Note that different operations may have different valid transitions. We further propose a Binary-Masked Softmax (BMSoftmax) layer to omit the possible invalid transitions. Extensive experiments on several benchmark datasets show that the transformed architecture significantly outperforms both its original counterpart and the architectures optimized by existing methods.
A Surgery of the Neural Architecture Evaluators
Aug 12, 2020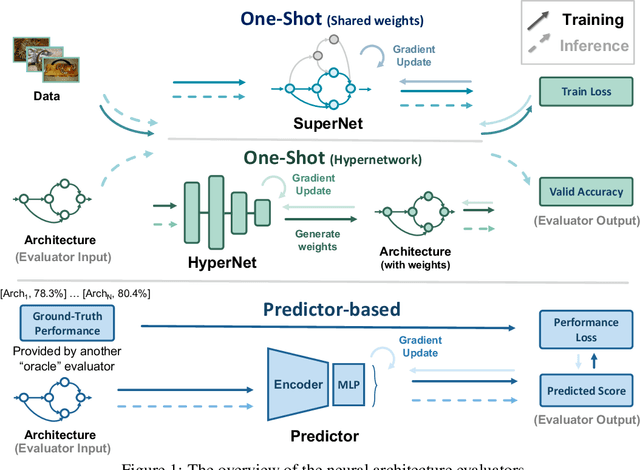

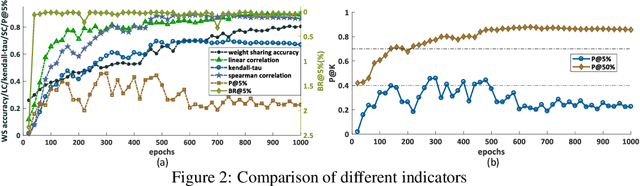

Neural architecture search (NAS) recently received extensive attention due to its effectiveness in automatically designing effective neural architectures. A major challenge in NAS is to conduct a fast and accurate evaluation of neural architectures. Commonly used fast architecture evaluators include one-shot evaluators (including weight sharing and hypernet-based ones) and predictor-based evaluators. Despite their high evaluation efficiency, the evaluation correlation of these evaluators is still questionable. In this paper, we conduct an extensive assessment of both the one-shot and predictor-based evaluator on the NAS-Bench-201 benchmark search space, and break up how and why different factors influence the evaluation correlation and other NAS-oriented criteria. Codes are available at https://github.com/walkerning/aw_nas.
Breaking the Curse of Space Explosion: Towards Efficient NAS with Curriculum Search
Jul 07, 2020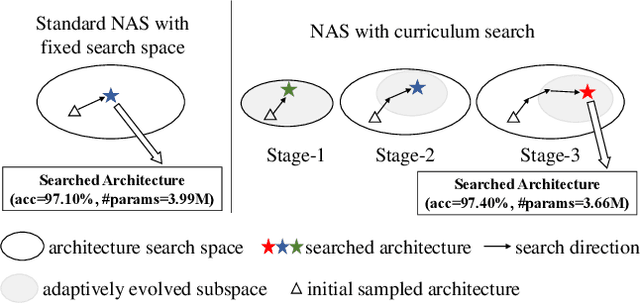
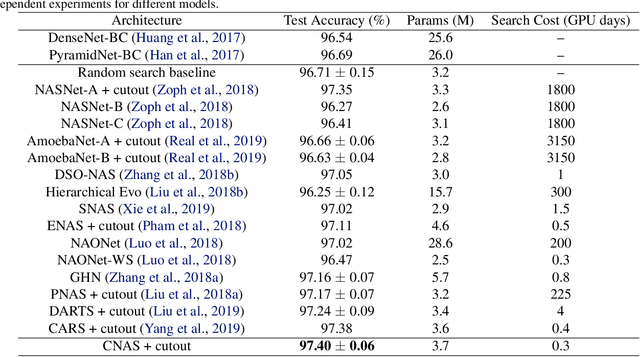
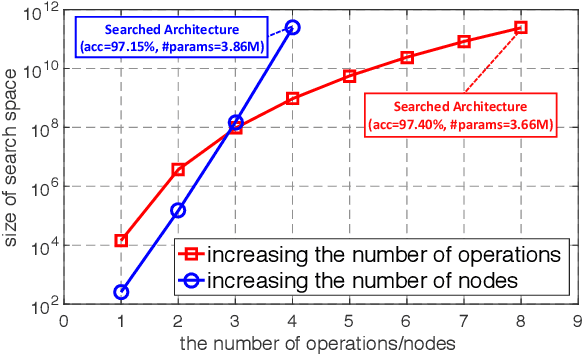
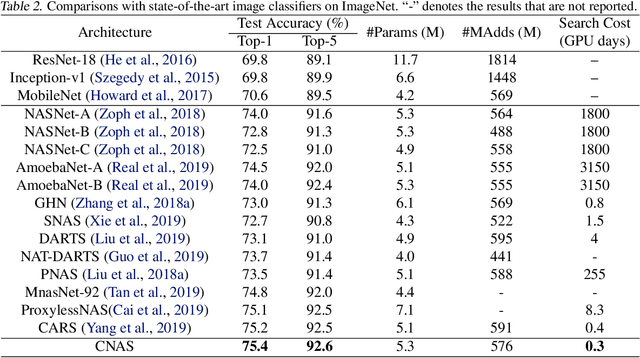
Neural architecture search (NAS) has become an important approach to automatically find effective architectures. To cover all possible good architectures, we need to search in an extremely large search space with billions of candidate architectures. More critically, given a large search space, we may face a very challenging issue of space explosion. However, due to the limitation of computational resources, we can only sample a very small proportion of the architectures, which provides insufficient information for the training. As a result, existing methods may often produce suboptimal architectures. To alleviate this issue, we propose a curriculum search method that starts from a small search space and gradually incorporates the learned knowledge to guide the search in a large space. With the proposed search strategy, our Curriculum Neural Architecture Search (CNAS) method significantly improves the search efficiency and finds better architectures than existing NAS methods. Extensive experiments on CIFAR-10 and ImageNet demonstrate the effectiveness of the proposed method.