 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSJD-PAC: Accelerating Speculative Jacobi Decoding via Proactive Drafting and Adaptive Continuation
Mar 19, 2026Speculative Jacobi Decoding (SJD) offers a draft-model-free approach to accelerate autoregressive text-to-image synthesis. However, the high-entropy nature of visual generation yields low draft-token acceptance rates in complex regions, creating a bottleneck that severely limits overall throughput. To overcome this, we introduce SJD-PAC, an enhanced SJD framework. First, SJD-PAC employs a proactive drafting strategy to improve local acceptance rates in these challenging high-entropy regions. Second, we introduce an adaptive continuation mechanism that sustains sequence validation after an initial rejection, bypassing the need for full resampling. Working in tandem, these optimizations significantly increase the average acceptance length per step, boosting inference speed while strictly preserving the target distribution. Experiments on standard text-to-image benchmarks demonstrate that SJD-PAC achieves a $3.8\times$ speedup with lossless image quality.
Visual-textual Dermatoglyphic Animal Biometrics: A First Case Study on Panthera tigris
Dec 16, 2025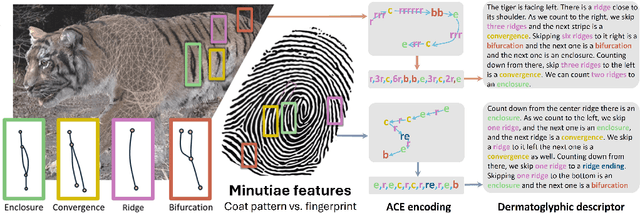
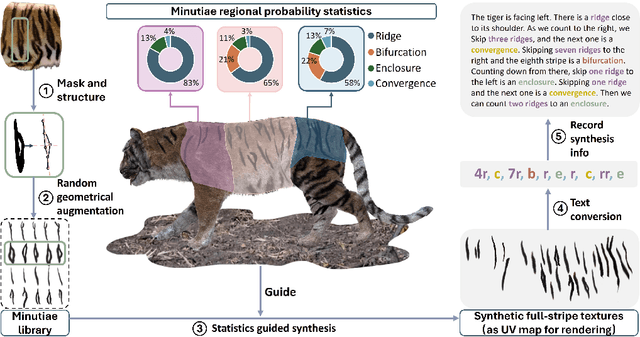
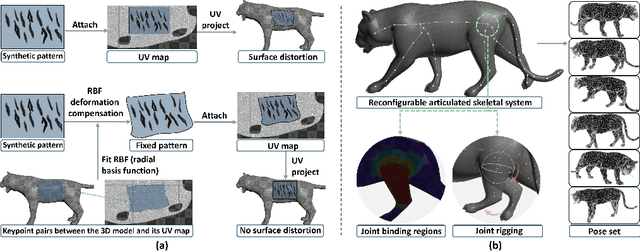
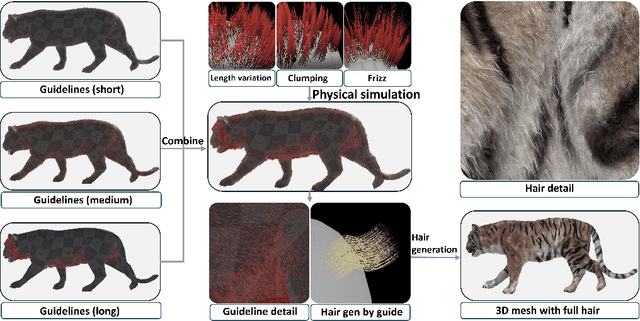
Biologists have long combined visuals with textual field notes to re-identify (Re-ID) animals. Contemporary AI tools automate this for species with distinctive morphological features but remain largely image-based. Here, we extend Re-ID methodologies by incorporating precise dermatoglyphic textual descriptors-an approach used in forensics but new to ecology. We demonstrate that these specialist semantics abstract and encode animal coat topology using human-interpretable language tags. Drawing on 84,264 manually labelled minutiae across 3,355 images of 185 tigers (Panthera tigris), we evaluate this visual-textual methodology, revealing novel capabilities for cross-modal identity retrieval. To optimise performance, we developed a text-image co-synthesis pipeline to generate 'virtual individuals', each comprising dozens of life-like visuals paired with dermatoglyphic text. Benchmarking against real-world scenarios shows this augmentation significantly boosts AI accuracy in cross-modal retrieval while alleviating data scarcity. We conclude that dermatoglyphic language-guided biometrics can overcome vision-only limitations, enabling textual-to-visual identity recovery underpinned by human-verifiable matchings. This represents a significant advance towards explainability in Re-ID and a language-driven unification of descriptive modalities in ecological monitoring.
Observability Analysis and Composite Disturbance Filtering for a Bar Tethered to Dual UAVs Subject to Multi-source Disturbances
Dec 10, 2025Cooperative suspended aerial transportation is highly susceptible to multi-source disturbances such as aerodynamic effects and thrust uncertainties. To achieve precise load manipulation, existing methods often rely on extra sensors to measure cable directions or the payload's pose, which increases the system cost and complexity. A fundamental question remains: is the payload's pose observable under multi-source disturbances using only the drones' odometry information? To answer this question, this work focuses on the two-drone-bar system and proves that the whole system is observable when only two or fewer types of lumped disturbances exist by using the observability rank criterion. To the best of our knowledge, we are the first to present such a conclusion and this result paves the way for more cost-effective and robust systems by minimizing their sensor suites. Next, to validate this analysis, we consider the situation where the disturbances are only exerted on the drones, and develop a composite disturbance filtering scheme. A disturbance observer-based error-state extended Kalman filter is designed for both state and disturbance estimation, which renders improved estimation performance for the whole system evolving on the manifold $(\mathbb{R}^3)^2\times(TS^2)^3$. Our simulation and experimental tests have validated that it is possible to fully estimate the state and disturbance of the system with only odometry information of the drones.
ViSpec: Accelerating Vision-Language Models with Vision-Aware Speculative Decoding
Sep 17, 2025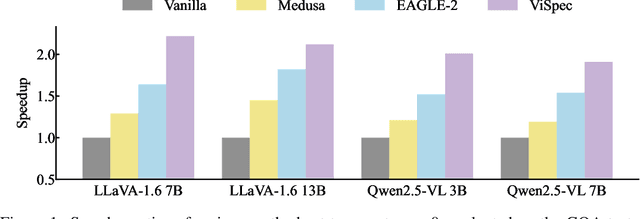
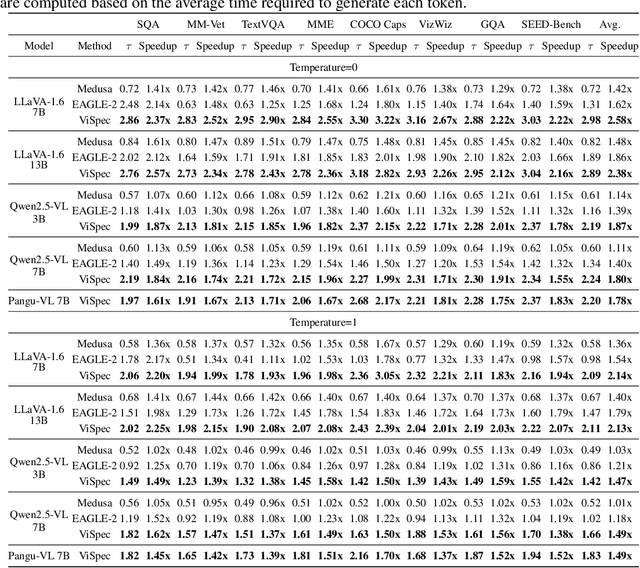
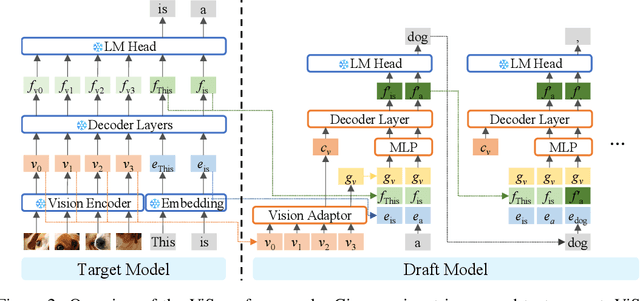
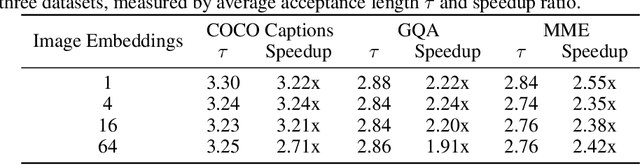
Speculative decoding is a widely adopted technique for accelerating inference in large language models (LLMs), yet its application to vision-language models (VLMs) remains underexplored, with existing methods achieving only modest speedups (<1.5x). This gap is increasingly significant as multimodal capabilities become central to large-scale models. We hypothesize that large VLMs can effectively filter redundant image information layer by layer without compromising textual comprehension, whereas smaller draft models struggle to do so. To address this, we introduce Vision-Aware Speculative Decoding (ViSpec), a novel framework tailored for VLMs. ViSpec employs a lightweight vision adaptor module to compress image tokens into a compact representation, which is seamlessly integrated into the draft model's attention mechanism while preserving original image positional information. Additionally, we extract a global feature vector for each input image and augment all subsequent text tokens with this feature to enhance multimodal coherence. To overcome the scarcity of multimodal datasets with long assistant responses, we curate a specialized training dataset by repurposing existing datasets and generating extended outputs using the target VLM with modified prompts. Our training strategy mitigates the risk of the draft model exploiting direct access to the target model's hidden states, which could otherwise lead to shortcut learning when training solely on target model outputs. Extensive experiments validate ViSpec, achieving, to our knowledge, the first substantial speedup in VLM speculative decoding.
LPVIMO-SAM: Tightly-coupled LiDAR/Polarization Vision/Inertial/Magnetometer/Optical Flow Odometry via Smoothing and Mapping
Apr 29, 2025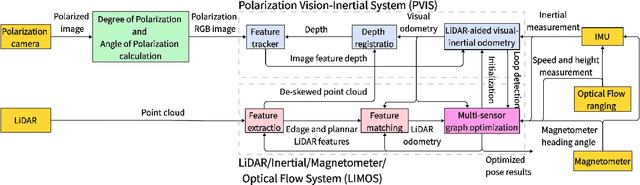
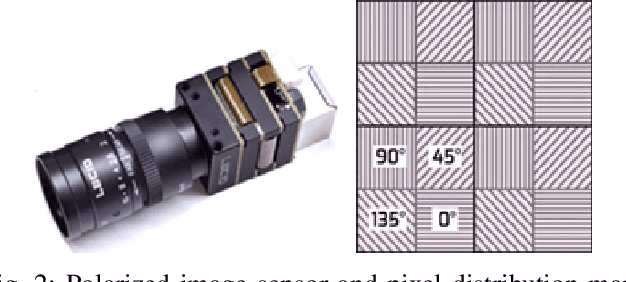
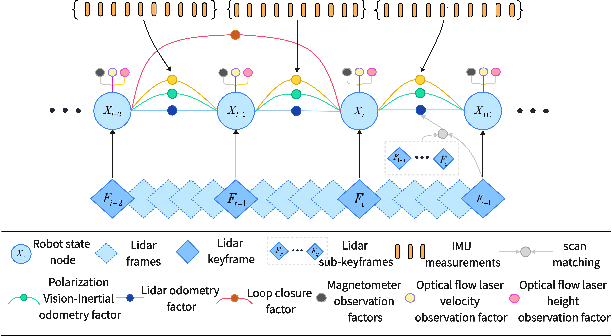
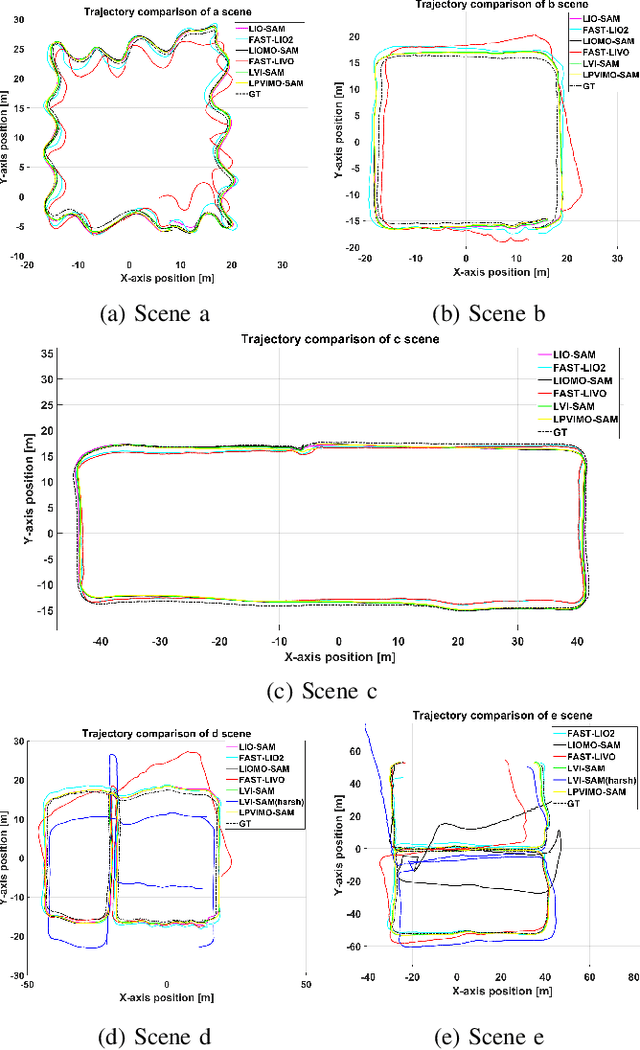
We propose a tightly-coupled LiDAR/Polarization Vision/Inertial/Magnetometer/Optical Flow Odometry via Smoothing and Mapping (LPVIMO-SAM) framework, which integrates LiDAR, polarization vision, inertial measurement unit, magnetometer, and optical flow in a tightly-coupled fusion. This framework enables high-precision and highly robust real-time state estimation and map construction in challenging environments, such as LiDAR-degraded, low-texture regions, and feature-scarce areas. The LPVIMO-SAM comprises two subsystems: a Polarized Vision-Inertial System and a LiDAR/Inertial/Magnetometer/Optical Flow System. The polarized vision enhances the robustness of the Visual/Inertial odometry in low-feature and low-texture scenarios by extracting the polarization information of the scene. The magnetometer acquires the heading angle, and the optical flow obtains the speed and height to reduce the accumulated error. A magnetometer heading prior factor, an optical flow speed observation factor, and a height observation factor are designed to eliminate the cumulative errors of the LiDAR/Inertial odometry through factor graph optimization. Meanwhile, the LPVIMO-SAM can maintain stable positioning even when one of the two subsystems fails, further expanding its applicability in LiDAR-degraded, low-texture, and low-feature environments. Code is available on https://github.com/junxiaofanchen/LPVIMO-SAM.
Align-KD: Distilling Cross-Modal Alignment Knowledge for Mobile Vision-Language Model
Dec 02, 2024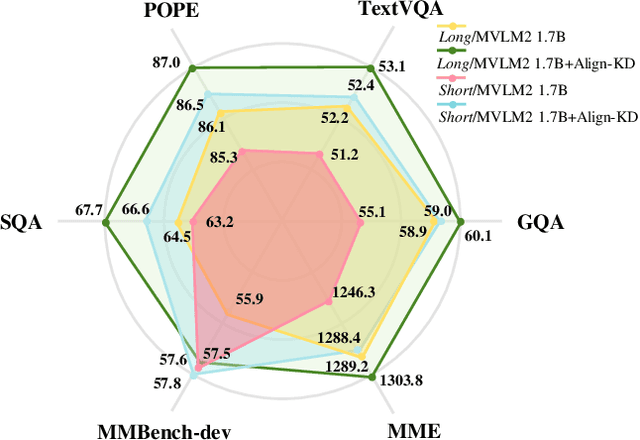
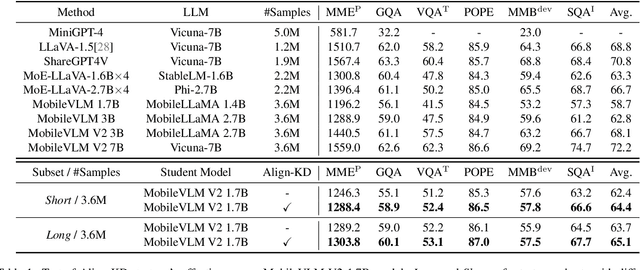
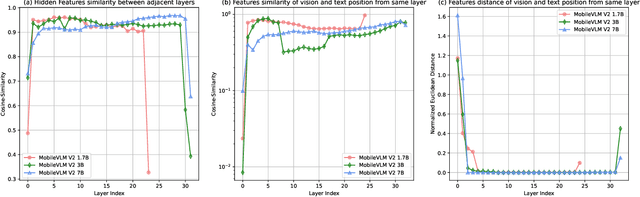
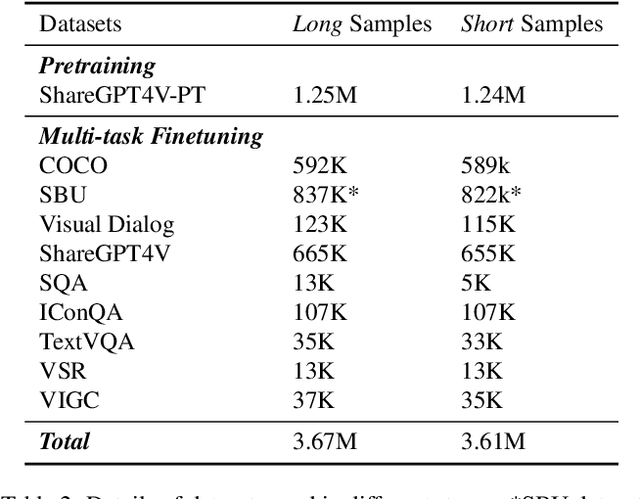
Vision-Language Models (VLMs) bring powerful understanding and reasoning capabilities to multimodal tasks. Meanwhile, the great need for capable aritificial intelligence on mobile devices also arises, such as the AI assistant software. Some efforts try to migrate VLMs to edge devices to expand their application scope. Simplifying the model structure is a common method, but as the model shrinks, the trade-off between performance and size becomes more and more difficult. Knowledge distillation (KD) can help models improve comprehensive capabilities without increasing size or data volume. However, most of the existing large model distillation techniques only consider applications on single-modal LLMs, or only use teachers to create new data environments for students. None of these methods take into account the distillation of the most important cross-modal alignment knowledge in VLMs. We propose a method called Align-KD to guide the student model to learn the cross-modal matching that occurs at the shallow layer. The teacher also helps student learn the projection of vision token into text embedding space based on the focus of text. Under the guidance of Align-KD, the 1.7B MobileVLM V2 model can learn rich knowledge from the 7B teacher model with light design of training loss, and achieve an average score improvement of 2.0 across 6 benchmarks under two training subsets respectively. Code is available at: https://github.com/fqhank/Align-KD.
Full-Stage Pseudo Label Quality Enhancement for Weakly-supervised Temporal Action Localization
Jul 12, 2024Weakly-supervised Temporal Action Localization (WSTAL) aims to localize actions in untrimmed videos using only video-level supervision. Latest WSTAL methods introduce pseudo label learning framework to bridge the gap between classification-based training and inferencing targets at localization, and achieve cutting-edge results. In these frameworks, a classification-based model is used to generate pseudo labels for a regression-based student model to learn from. However, the quality of pseudo labels in the framework, which is a key factor to the final result, is not carefully studied. In this paper, we propose a set of simple yet efficient pseudo label quality enhancement mechanisms to build our FuSTAL framework. FuSTAL enhances pseudo label quality at three stages: cross-video contrastive learning at proposal Generation-Stage, prior-based filtering at proposal Selection-Stage and EMA-based distillation at Training-Stage. These designs enhance pseudo label quality at different stages in the framework, and help produce more informative, less false and smoother action proposals. With the help of these comprehensive designs at all stages, FuSTAL achieves an average mAP of 50.8% on THUMOS'14, outperforming the previous best method by 1.2%, and becomes the first method to reach the milestone of 50%.
ExCP: Extreme LLM Checkpoint Compression via Weight-Momentum Joint Shrinking
Jun 17, 2024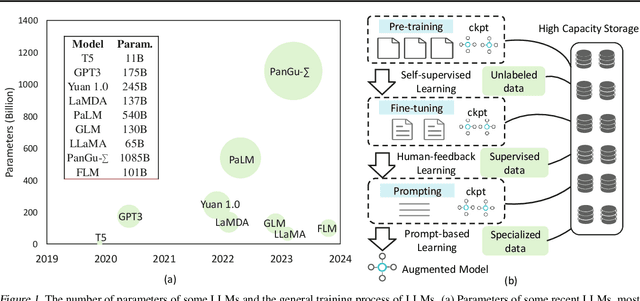
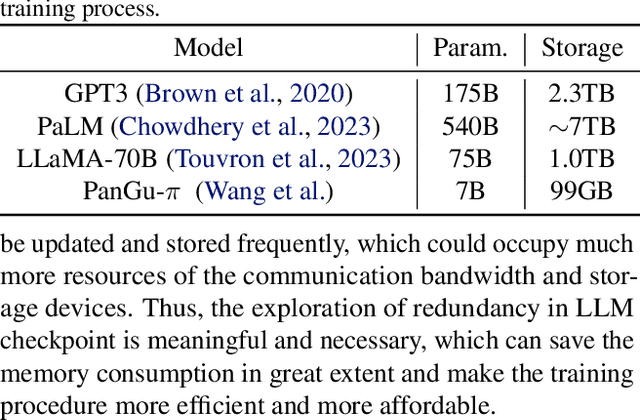
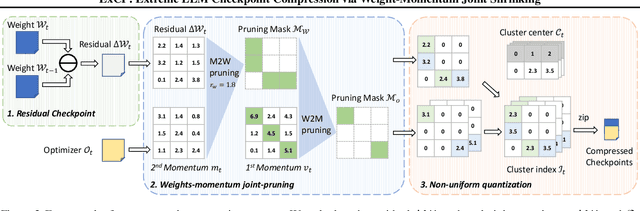
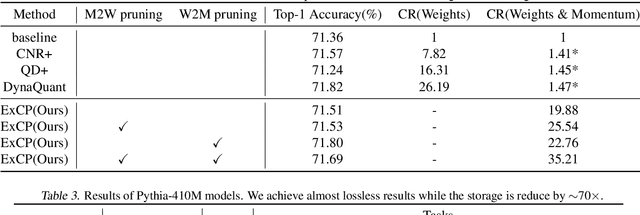
Large language models (LLM) have recently attracted significant attention in the field of artificial intelligence. However, the training process of these models poses significant challenges in terms of computational and storage capacities, thus compressing checkpoints has become an urgent problem. In this paper, we propose a novel Extreme Checkpoint Compression (ExCP) framework, which significantly reduces the required storage of training checkpoints while achieving nearly lossless performance. We first calculate the residuals of adjacent checkpoints to obtain the essential but sparse information for higher compression ratio. To further excavate the redundancy parameters in checkpoints, we then propose a weight-momentum joint shrinking method to utilize another important information during the model optimization, i.e., momentum. In particular, we exploit the information of both model and optimizer to discard as many parameters as possible while preserving critical information to ensure optimal performance. Furthermore, we utilize non-uniform quantization to further compress the storage of checkpoints. We extensively evaluate our proposed ExCP framework on several models ranging from 410M to 7B parameters and demonstrate significant storage reduction while maintaining strong performance. For instance, we achieve approximately $70\times$ compression for the Pythia-410M model, with the final performance being as accurate as the original model on various downstream tasks. Codes will be available at https://github.com/Gaffey/ExCP.
No Time to Waste: Squeeze Time into Channel for Mobile Video Understanding
May 14, 2024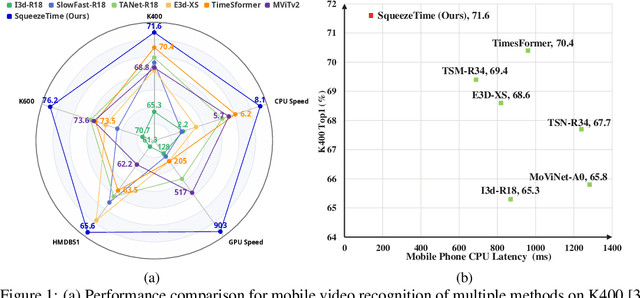
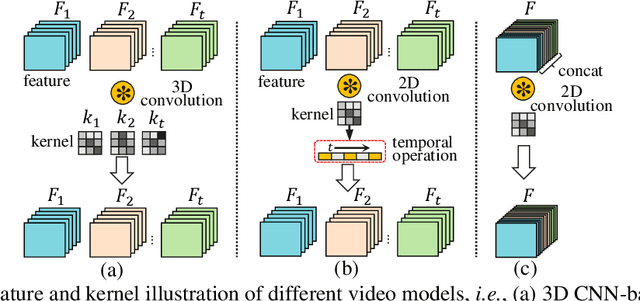
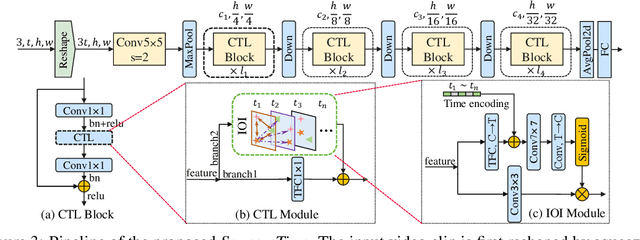

Current architectures for video understanding mainly build upon 3D convolutional blocks or 2D convolutions with additional operations for temporal modeling. However, these methods all regard the temporal axis as a separate dimension of the video sequence, which requires large computation and memory budgets and thus limits their usage on mobile devices. In this paper, we propose to squeeze the time axis of a video sequence into the channel dimension and present a lightweight video recognition network, term as \textit{SqueezeTime}, for mobile video understanding. To enhance the temporal modeling capability of the proposed network, we design a Channel-Time Learning (CTL) Block to capture temporal dynamics of the sequence. This module has two complementary branches, in which one branch is for temporal importance learning and another branch with temporal position restoring capability is to enhance inter-temporal object modeling ability. The proposed SqueezeTime is much lightweight and fast with high accuracies for mobile video understanding. Extensive experiments on various video recognition and action detection benchmarks, i.e., Kinetics400, Kinetics600, HMDB51, AVA2.1 and THUMOS14, demonstrate the superiority of our model. For example, our SqueezeTime achieves $+1.2\%$ accuracy and $+80\%$ GPU throughput gain on Kinetics400 than prior methods. Codes are publicly available at https://github.com/xinghaochen/SqueezeTime and https://github.com/mindspore-lab/models/tree/master/research/huawei-noah/SqueezeTime.
TinySAM: Pushing the Envelope for Efficient Segment Anything Model
Dec 21, 2023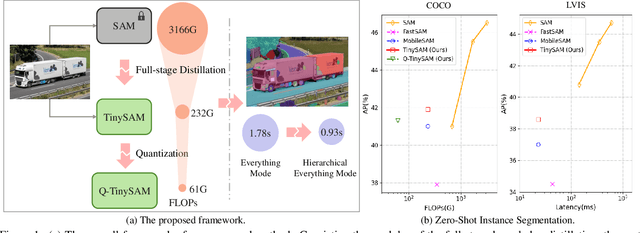
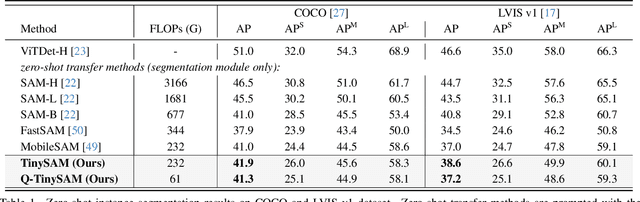
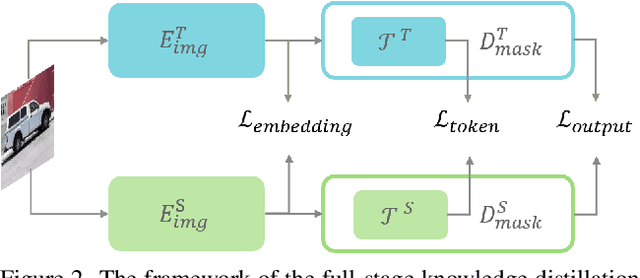
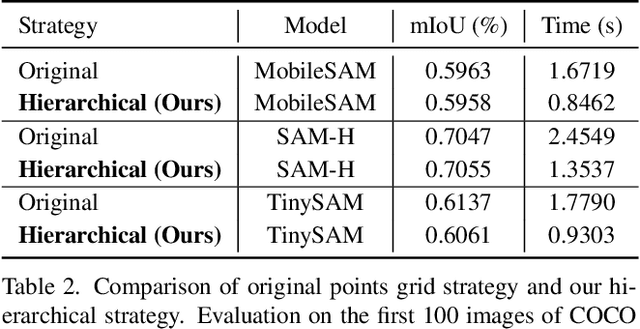
Recently segment anything model (SAM) has shown powerful segmentation capability and has drawn great attention in computer vision fields. Massive following works have developed various applications based on the pretrained SAM and achieved impressive performance on downstream vision tasks. However, SAM consists of heavy architectures and requires massive computational capacity, which hinders the further application of SAM on computation constrained edge devices. To this end, in this paper we propose a framework to obtain a tiny segment anything model (TinySAM) while maintaining the strong zero-shot performance. We first propose a full-stage knowledge distillation method with online hard prompt sampling strategy to distill a lightweight student model. We also adapt the post-training quantization to the promptable segmentation task and further reduce the computational cost. Moreover, a hierarchical segmenting everything strategy is proposed to accelerate the everything inference by $2\times$ with almost no performance degradation. With all these proposed methods, our TinySAM leads to orders of magnitude computational reduction and pushes the envelope for efficient segment anything task. Extensive experiments on various zero-shot transfer tasks demonstrate the significantly advantageous performance of our TinySAM against counterpart methods. Pre-trained models and codes will be available at https://github.com/xinghaochen/TinySAM and https://gitee.com/mindspore/models/tree/master/research/cv/TinySAM.