 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSJD-PAC: Accelerating Speculative Jacobi Decoding via Proactive Drafting and Adaptive Continuation
Mar 19, 2026Speculative Jacobi Decoding (SJD) offers a draft-model-free approach to accelerate autoregressive text-to-image synthesis. However, the high-entropy nature of visual generation yields low draft-token acceptance rates in complex regions, creating a bottleneck that severely limits overall throughput. To overcome this, we introduce SJD-PAC, an enhanced SJD framework. First, SJD-PAC employs a proactive drafting strategy to improve local acceptance rates in these challenging high-entropy regions. Second, we introduce an adaptive continuation mechanism that sustains sequence validation after an initial rejection, bypassing the need for full resampling. Working in tandem, these optimizations significantly increase the average acceptance length per step, boosting inference speed while strictly preserving the target distribution. Experiments on standard text-to-image benchmarks demonstrate that SJD-PAC achieves a $3.8\times$ speedup with lossless image quality.
ViSpec: Accelerating Vision-Language Models with Vision-Aware Speculative Decoding
Sep 17, 2025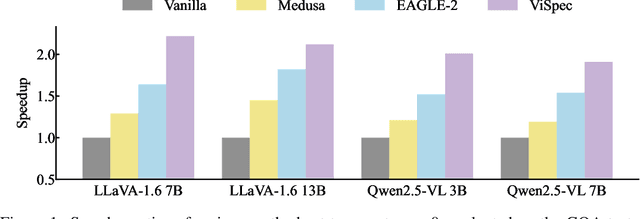
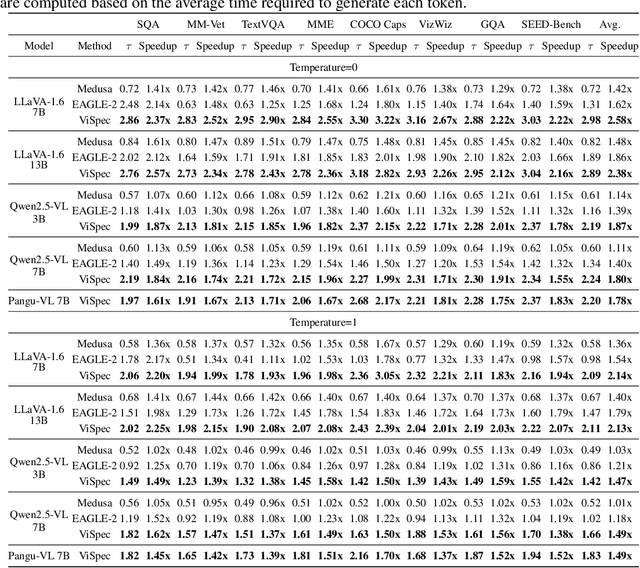
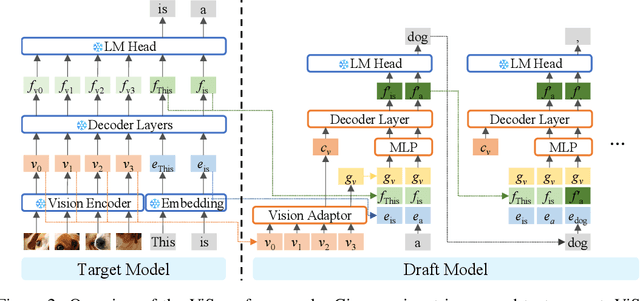
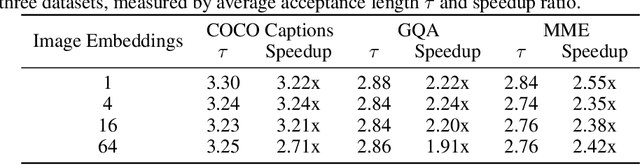
Speculative decoding is a widely adopted technique for accelerating inference in large language models (LLMs), yet its application to vision-language models (VLMs) remains underexplored, with existing methods achieving only modest speedups (<1.5x). This gap is increasingly significant as multimodal capabilities become central to large-scale models. We hypothesize that large VLMs can effectively filter redundant image information layer by layer without compromising textual comprehension, whereas smaller draft models struggle to do so. To address this, we introduce Vision-Aware Speculative Decoding (ViSpec), a novel framework tailored for VLMs. ViSpec employs a lightweight vision adaptor module to compress image tokens into a compact representation, which is seamlessly integrated into the draft model's attention mechanism while preserving original image positional information. Additionally, we extract a global feature vector for each input image and augment all subsequent text tokens with this feature to enhance multimodal coherence. To overcome the scarcity of multimodal datasets with long assistant responses, we curate a specialized training dataset by repurposing existing datasets and generating extended outputs using the target VLM with modified prompts. Our training strategy mitigates the risk of the draft model exploiting direct access to the target model's hidden states, which could otherwise lead to shortcut learning when training solely on target model outputs. Extensive experiments validate ViSpec, achieving, to our knowledge, the first substantial speedup in VLM speculative decoding.
Federated Koopman-Reservoir Learning for Large-Scale Multivariate Time-Series Anomaly Detection
Mar 14, 2025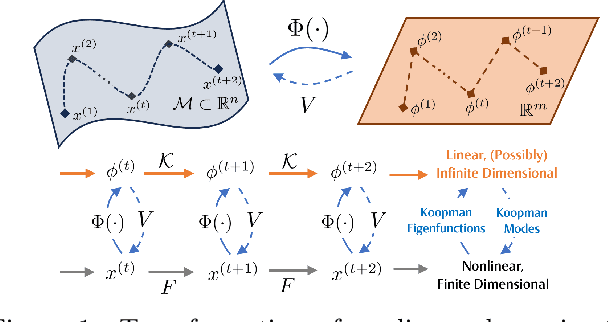
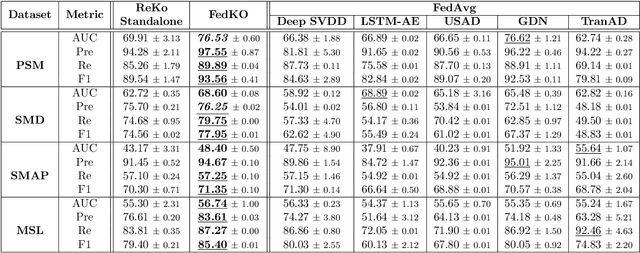
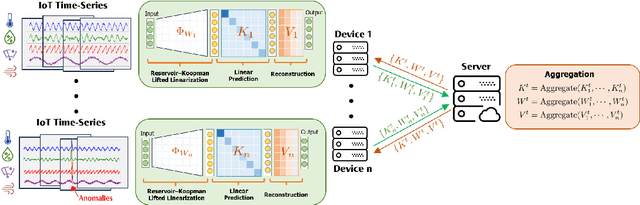
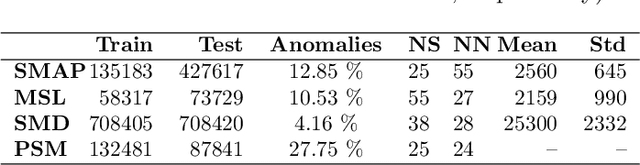
The proliferation of edge devices has dramatically increased the generation of multivariate time-series (MVTS) data, essential for applications from healthcare to smart cities. Such data streams, however, are vulnerable to anomalies that signal crucial problems like system failures or security incidents. Traditional MVTS anomaly detection methods, encompassing statistical and centralized machine learning approaches, struggle with the heterogeneity, variability, and privacy concerns of large-scale, distributed environments. In response, we introduce FedKO, a novel unsupervised Federated Learning framework that leverages the linear predictive capabilities of Koopman operator theory along with the dynamic adaptability of Reservoir Computing. This enables effective spatiotemporal processing and privacy preservation for MVTS data. FedKO is formulated as a bi-level optimization problem, utilizing a specific federated algorithm to explore a shared Reservoir-Koopman model across diverse datasets. Such a model is then deployable on edge devices for efficient detection of anomalies in local MVTS streams. Experimental results across various datasets showcase FedKO's superior performance against state-of-the-art methods in MVTS anomaly detection. Moreover, FedKO reduces up to 8x communication size and 2x memory usage, making it highly suitable for large-scale systems.
ExCP: Extreme LLM Checkpoint Compression via Weight-Momentum Joint Shrinking
Jun 17, 2024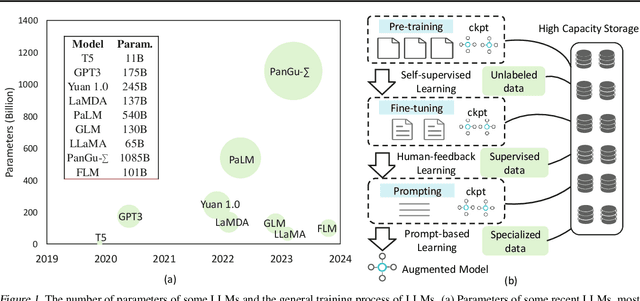
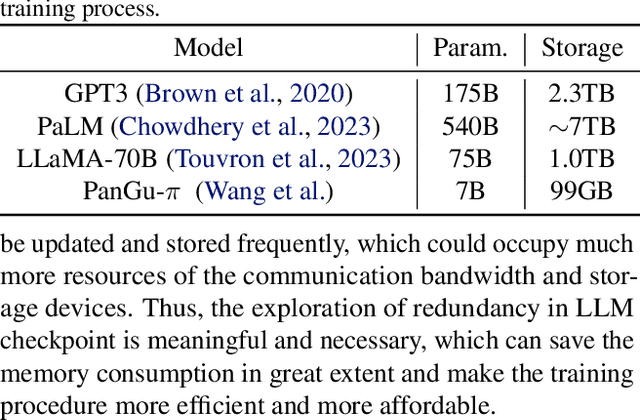
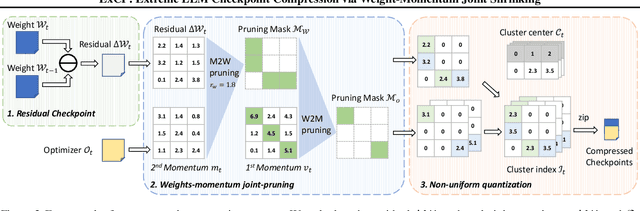
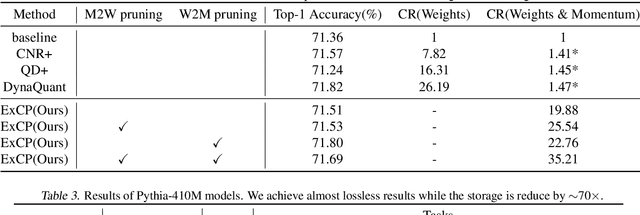
Large language models (LLM) have recently attracted significant attention in the field of artificial intelligence. However, the training process of these models poses significant challenges in terms of computational and storage capacities, thus compressing checkpoints has become an urgent problem. In this paper, we propose a novel Extreme Checkpoint Compression (ExCP) framework, which significantly reduces the required storage of training checkpoints while achieving nearly lossless performance. We first calculate the residuals of adjacent checkpoints to obtain the essential but sparse information for higher compression ratio. To further excavate the redundancy parameters in checkpoints, we then propose a weight-momentum joint shrinking method to utilize another important information during the model optimization, i.e., momentum. In particular, we exploit the information of both model and optimizer to discard as many parameters as possible while preserving critical information to ensure optimal performance. Furthermore, we utilize non-uniform quantization to further compress the storage of checkpoints. We extensively evaluate our proposed ExCP framework on several models ranging from 410M to 7B parameters and demonstrate significant storage reduction while maintaining strong performance. For instance, we achieve approximately $70\times$ compression for the Pythia-410M model, with the final performance being as accurate as the original model on various downstream tasks. Codes will be available at https://github.com/Gaffey/ExCP.
$i$REPO: $i$mplicit Reward Pairwise Difference based Empirical Preference Optimization
May 24, 2024
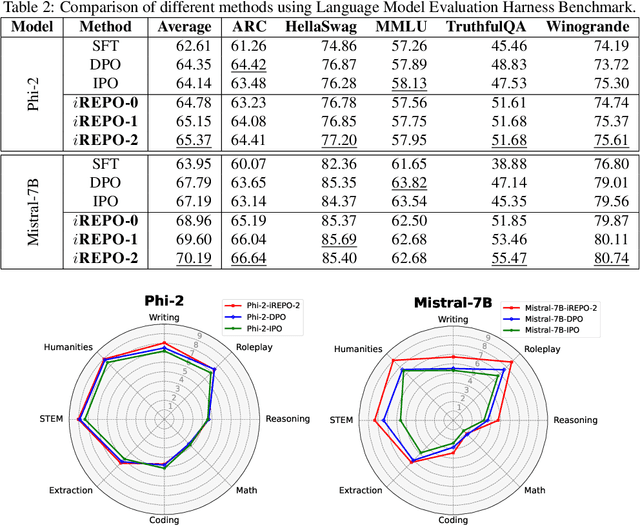
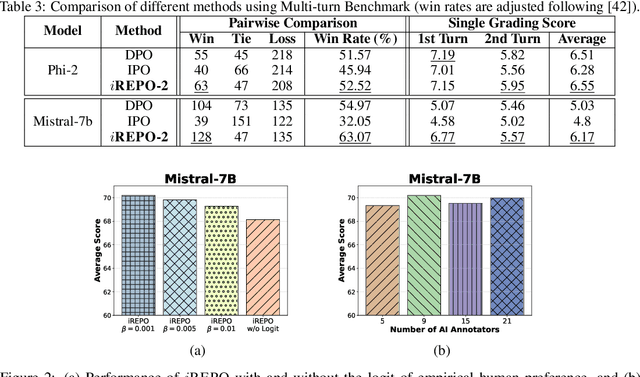
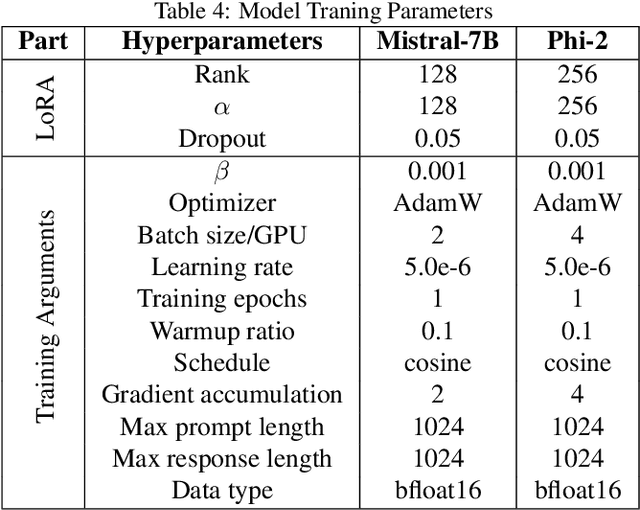
While astonishingly capable, large Language Models (LLM) can sometimes produce outputs that deviate from human expectations. Such deviations necessitate an alignment phase to prevent disseminating untruthful, toxic, or biased information. Traditional alignment methods based on reinforcement learning often struggle with the identified instability, whereas preference optimization methods are limited by their overfitting to pre-collected hard-label datasets. In this paper, we propose a novel LLM alignment framework named $i$REPO, which utilizes implicit Reward pairwise difference regression for Empirical Preference Optimization. Particularly, $i$REPO employs self-generated datasets labelled by empirical human (or AI annotator) preference to iteratively refine the aligned policy through a novel regression-based loss function. Furthermore, we introduce an innovative algorithm backed by theoretical guarantees for achieving optimal results under ideal assumptions and providing a practical performance-gap result without such assumptions. Experimental results with Phi-2 and Mistral-7B demonstrate that $i$REPO effectively achieves self-alignment using soft-label, self-generated responses and the logit of empirical AI annotators. Furthermore, our approach surpasses preference optimization baselines in evaluations using the Language Model Evaluation Harness and Multi-turn benchmarks.
TinySAM: Pushing the Envelope for Efficient Segment Anything Model
Dec 21, 2023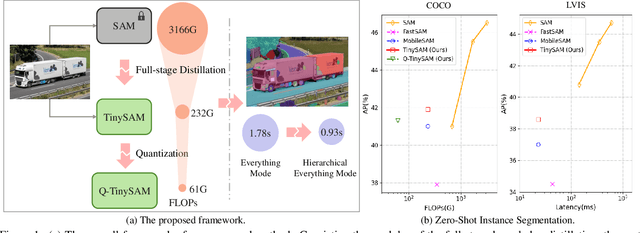
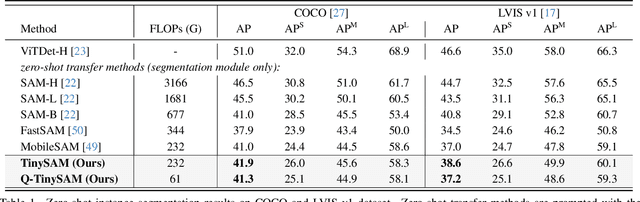
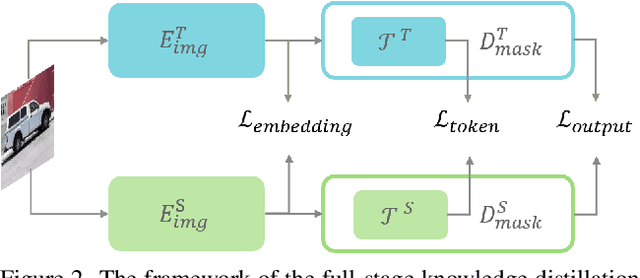
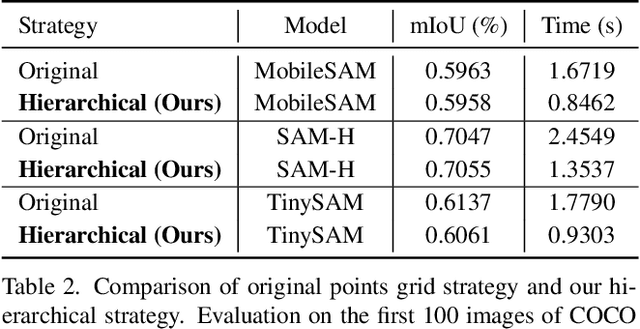
Recently segment anything model (SAM) has shown powerful segmentation capability and has drawn great attention in computer vision fields. Massive following works have developed various applications based on the pretrained SAM and achieved impressive performance on downstream vision tasks. However, SAM consists of heavy architectures and requires massive computational capacity, which hinders the further application of SAM on computation constrained edge devices. To this end, in this paper we propose a framework to obtain a tiny segment anything model (TinySAM) while maintaining the strong zero-shot performance. We first propose a full-stage knowledge distillation method with online hard prompt sampling strategy to distill a lightweight student model. We also adapt the post-training quantization to the promptable segmentation task and further reduce the computational cost. Moreover, a hierarchical segmenting everything strategy is proposed to accelerate the everything inference by $2\times$ with almost no performance degradation. With all these proposed methods, our TinySAM leads to orders of magnitude computational reduction and pushes the envelope for efficient segment anything task. Extensive experiments on various zero-shot transfer tasks demonstrate the significantly advantageous performance of our TinySAM against counterpart methods. Pre-trained models and codes will be available at https://github.com/xinghaochen/TinySAM and https://gitee.com/mindspore/models/tree/master/research/cv/TinySAM.
Coarse-to-Fine Searching for Efficient Generative Adversarial Networks
Apr 19, 2021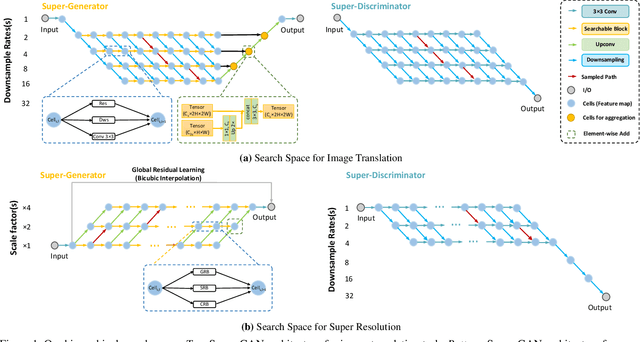
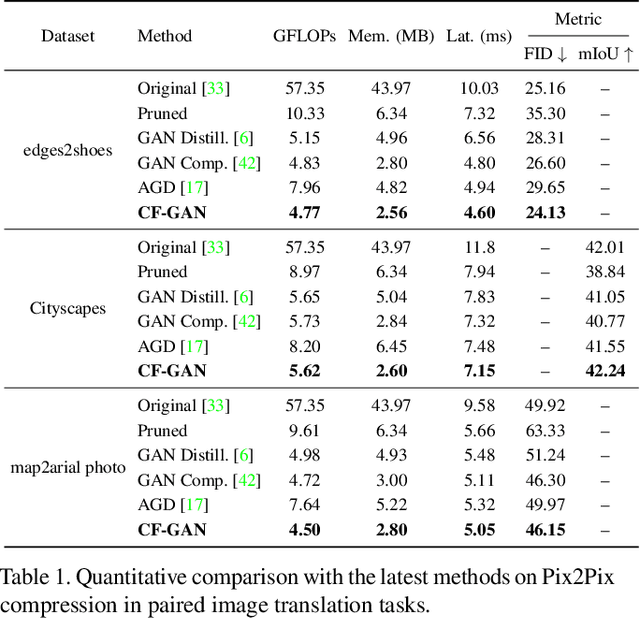
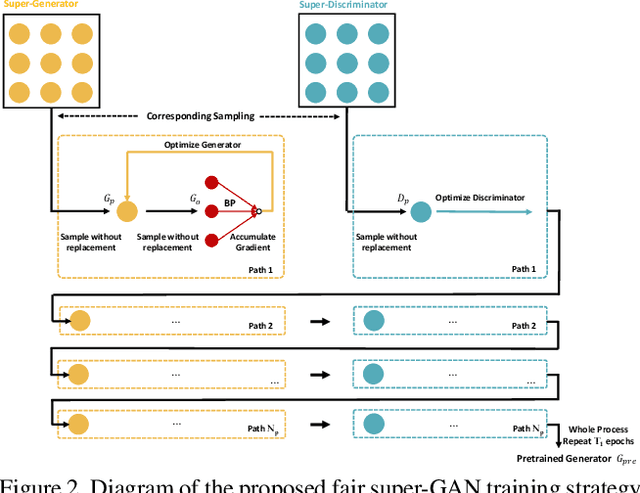
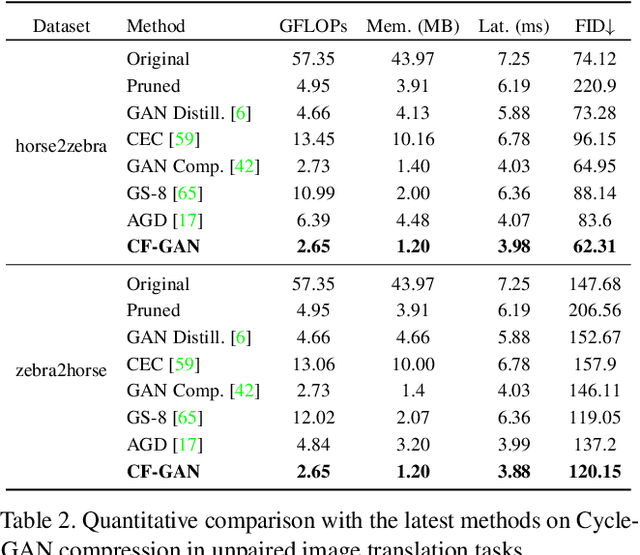
This paper studies the neural architecture search (NAS) problem for developing efficient generator networks. Compared with deep models for visual recognition tasks, generative adversarial network (GAN) are usually designed to conduct various complex image generation. We first discover an intact search space of generator networks including three dimensionalities, i.e., path, operator, channel for fully excavating the network performance. To reduce the huge search cost, we explore a coarse-to-fine search strategy which divides the overall search process into three sub-optimization problems accordingly. In addition, a fair supernet training approach is utilized to ensure that all sub-networks can be updated fairly and stably. Experiments results on benchmarks show that we can provide generator networks with better image quality and lower computational costs over the state-of-the-art methods. For example, with our method, it takes only about 8 GPU hours on the entire edges-to-shoes dataset to get a 2.56 MB model with a 24.13 FID score and 10 GPU hours on the entire Urban100 dataset to get a 1.49 MB model with a 24.94 PSNR score.
Optical Flow Distillation: Towards Efficient and Stable Video Style Transfer
Jul 10, 2020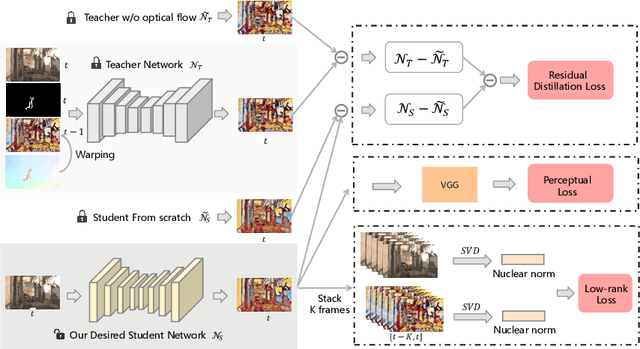
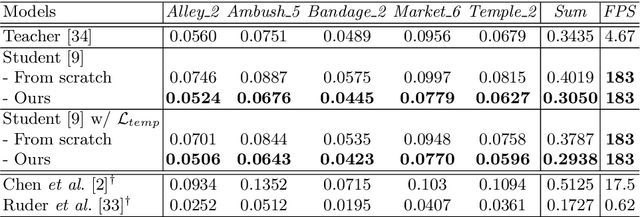
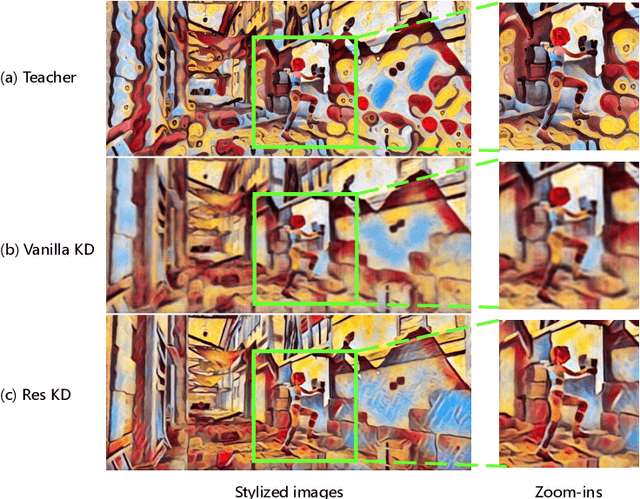
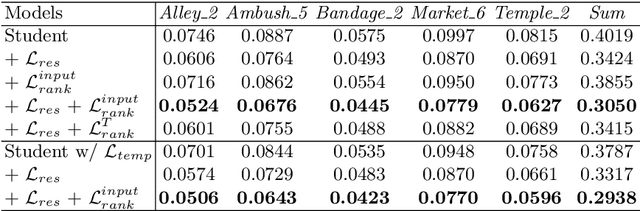
Video style transfer techniques inspire many exciting applications on mobile devices. However, their efficiency and stability are still far from satisfactory. To boost the transfer stability across frames, optical flow is widely adopted, despite its high computational complexity, e.g. occupying over 97% inference time. This paper proposes to learn a lightweight video style transfer network via knowledge distillation paradigm. We adopt two teacher networks, one of which takes optical flow during inference while the other does not. The output difference between these two teacher networks highlights the improvements made by optical flow, which is then adopted to distill the target student network. Furthermore, a low-rank distillation loss is employed to stabilize the output of student network by mimicking the rank of input videos. Extensive experiments demonstrate that our student network without an optical flow module is still able to generate stable video and runs much faster than the teacher network.
Distilling portable Generative Adversarial Networks for Image Translation
Mar 07, 2020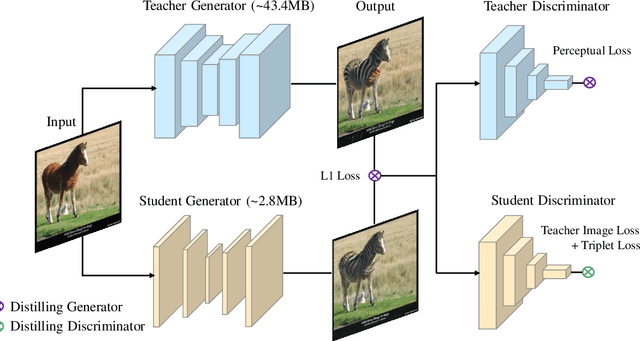
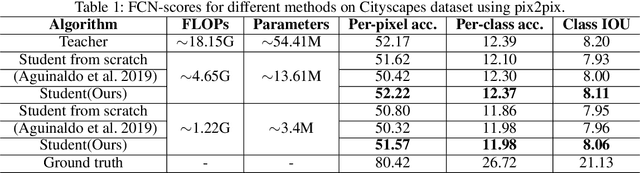

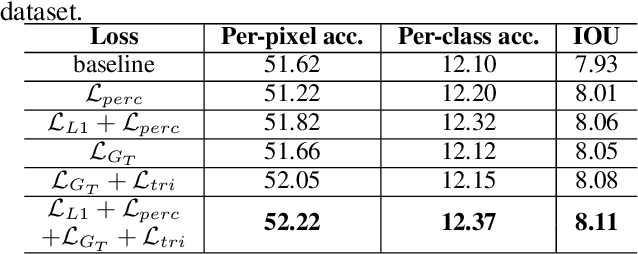
Despite Generative Adversarial Networks (GANs) have been widely used in various image-to-image translation tasks, they can be hardly applied on mobile devices due to their heavy computation and storage cost. Traditional network compression methods focus on visually recognition tasks, but never deal with generation tasks. Inspired by knowledge distillation, a student generator of fewer parameters is trained by inheriting the low-level and high-level information from the original heavy teacher generator. To promote the capability of student generator, we include a student discriminator to measure the distances between real images, and images generated by student and teacher generators. An adversarial learning process is therefore established to optimize student generator and student discriminator. Qualitative and quantitative analysis by conducting experiments on benchmark datasets demonstrate that the proposed method can learn portable generative models with strong performance.
Automatically Searching for U-Net Image Translator Architecture
Feb 26, 2020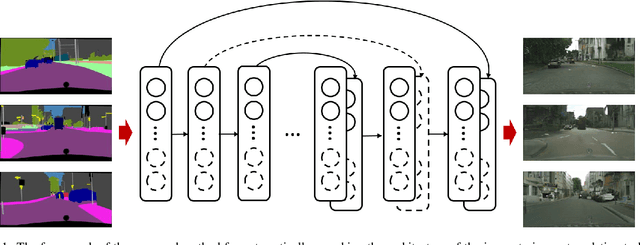
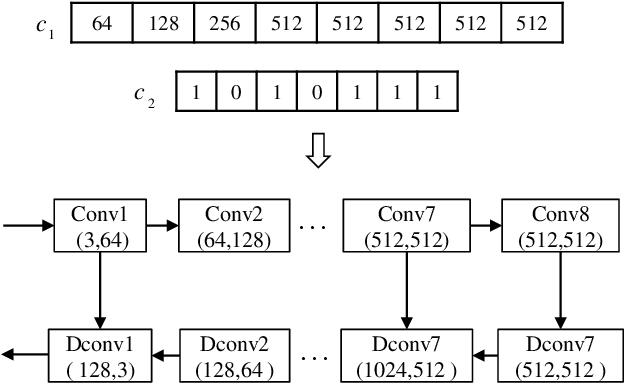


Image translators have been successfully applied to many important low level image processing tasks. However, classical network architecture of image translator like U-Net, is borrowed from other vision tasks like biomedical image segmentation. This straightforward adaptation may not be optimal and could cause redundancy in the network structure. In this paper, we propose an automatic architecture searching method for image translator. By utilizing evolutionary algorithm, we investigate a more efficient network architecture which costs less computation resources and achieves better performance than the original one. Extensive qualitative and quantitative experiments are conducted to demonstrate the effectiveness of the proposed method. Moreover, we transplant the searched network architecture to other datasets which are not involved in the architecture searching procedure. Efficiency of the searched architecture on these datasets further demonstrates the generalization of the method.