 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoomPilot: Controllable Synthesis of Interactive Indoor Environments via Multimodal Semantic Parsing
Dec 12, 2025



Generating controllable and interactive indoor scenes is fundamental to applications in game development, architectural visualization, and embodied AI training. Yet existing approaches either handle a narrow range of input modalities or rely on stochastic processes that hinder controllability. To overcome these limitations, we introduce RoomPilot, a unified framework that parses diverse multi-modal inputs--textual descriptions or CAD floor plans--into an Indoor Domain-Specific Language (IDSL) for indoor structured scene generation. The key insight is that a well-designed IDSL can act as a shared semantic representation, enabling coherent, high-quality scene synthesis from any single modality while maintaining interaction semantics. In contrast to conventional procedural methods that produce visually plausible but functionally inert layouts, RoomPilot leverages a curated dataset of interaction-annotated assets to synthesize environments exhibiting realistic object behaviors. Extensive experiments further validate its strong multi-modal understanding, fine-grained controllability in scene generation, and superior physical consistency and visual fidelity, marking a significant step toward general-purpose controllable 3D indoor scene generation.
OmniEval: A Benchmark for Evaluating Omni-modal Models with Visual, Auditory, and Textual Inputs
Jun 26, 2025In this paper, we introduce OmniEval, a benchmark for evaluating omni-modality models like MiniCPM-O 2.6, which encompasses visual, auditory, and textual inputs. Compared with existing benchmarks, our OmniEval has several distinctive features: (i) Full-modal collaboration: We design evaluation tasks that highlight the strong coupling between audio and video, requiring models to effectively leverage the collaborative perception of all modalities; (ii) Diversity of videos: OmniEval includes 810 audio-visual synchronized videos, 285 Chinese videos and 525 English videos; (iii) Diversity and granularity of tasks: OmniEval contains 2617 question-answer pairs, comprising 1412 open-ended questions and 1205 multiple-choice questions. These questions are divided into 3 major task types and 12 sub-task types to achieve comprehensive evaluation. Among them, we introduce a more granular video localization task named Grounding. Then we conduct experiments on OmniEval with several omni-modality models. We hope that our OmniEval can provide a platform for evaluating the ability to construct and understand coherence from the context of all modalities. Codes and data could be found at https://omnieval.github.io/.
TinySAM: Pushing the Envelope for Efficient Segment Anything Model
Dec 21, 2023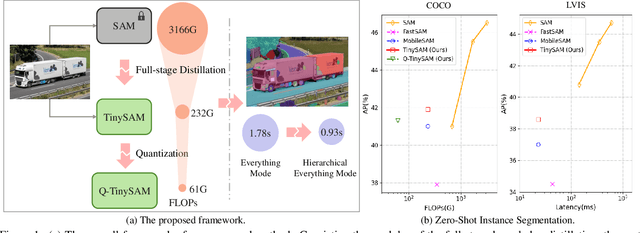
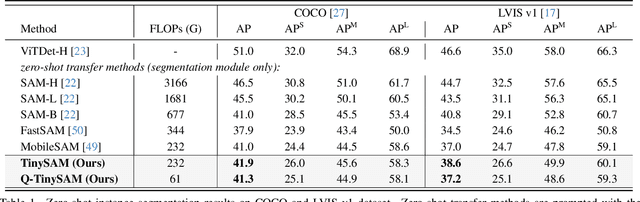
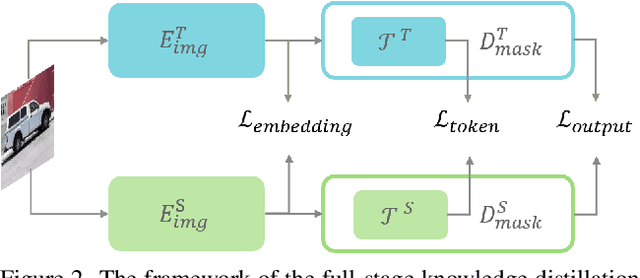
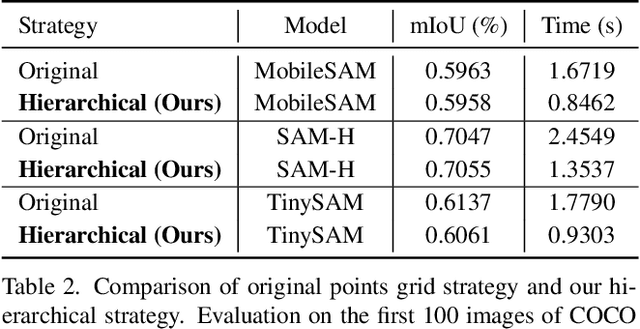
Recently segment anything model (SAM) has shown powerful segmentation capability and has drawn great attention in computer vision fields. Massive following works have developed various applications based on the pretrained SAM and achieved impressive performance on downstream vision tasks. However, SAM consists of heavy architectures and requires massive computational capacity, which hinders the further application of SAM on computation constrained edge devices. To this end, in this paper we propose a framework to obtain a tiny segment anything model (TinySAM) while maintaining the strong zero-shot performance. We first propose a full-stage knowledge distillation method with online hard prompt sampling strategy to distill a lightweight student model. We also adapt the post-training quantization to the promptable segmentation task and further reduce the computational cost. Moreover, a hierarchical segmenting everything strategy is proposed to accelerate the everything inference by $2\times$ with almost no performance degradation. With all these proposed methods, our TinySAM leads to orders of magnitude computational reduction and pushes the envelope for efficient segment anything task. Extensive experiments on various zero-shot transfer tasks demonstrate the significantly advantageous performance of our TinySAM against counterpart methods. Pre-trained models and codes will be available at https://github.com/xinghaochen/TinySAM and https://gitee.com/mindspore/models/tree/master/research/cv/TinySAM.
A Survey on Visual Transformer
Jan 30, 2021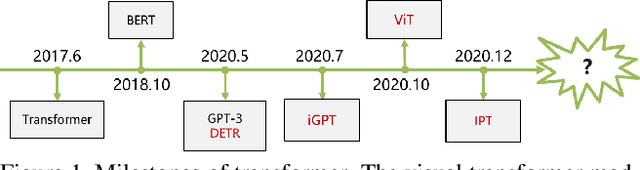
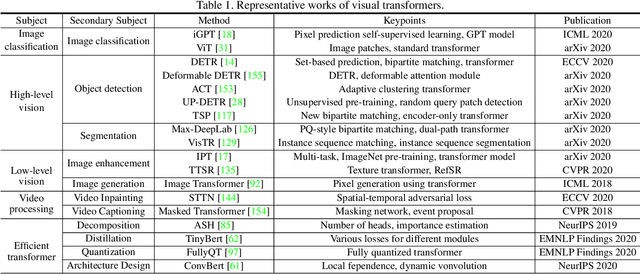
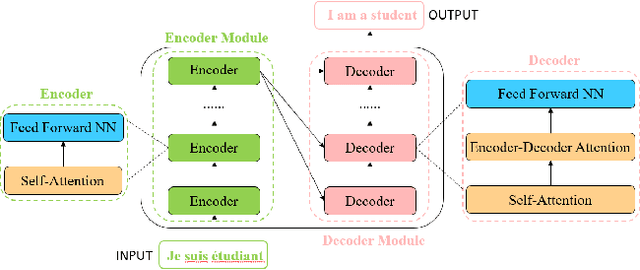
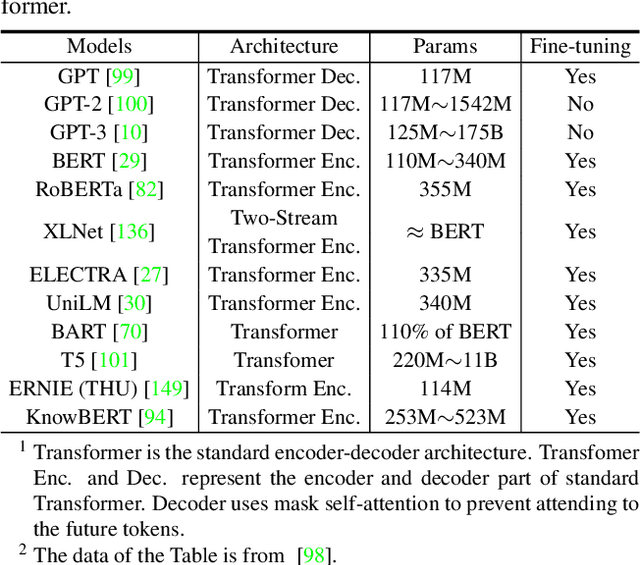
Transformer, first applied to the field of natural language processing, is a type of deep neural network mainly based on the self-attention mechanism. Thanks to its strong representation capabilities, researchers are looking at ways to apply transformer to computer vision tasks. In a variety of visual benchmarks, transformer-based models perform similar to or better than other types of networks such as convolutional and recurrent networks. Given its high performance and no need for human-defined inductive bias, transformer is receiving more and more attention from the computer vision community. In this paper, we review these visual transformer models by categorizing them in different tasks and analyzing their advantages and disadvantages. The main categories we explore include the backbone network, high/mid-level vision, low-level vision, and video processing. We also take a brief look at the self-attention mechanism in computer vision, as it is the base component in transformer. Furthermore, we include efficient transformer methods for pushing transformer into real device-based applications. Toward the end of this paper, we discuss the challenges and provide several further research directions for visual transformers.
Multi-Task Pruning for Semantic Segmentation Networks
Jul 16, 2020

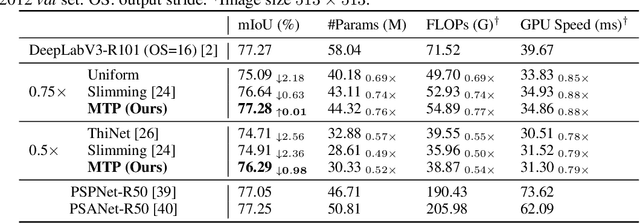
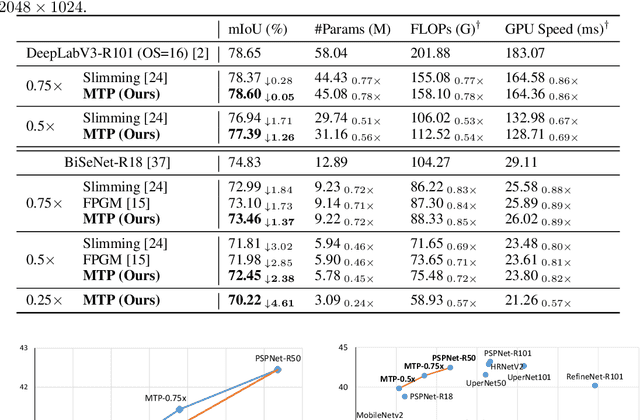
This paper focuses on channel pruning for semantic segmentation networks. There are a large number of works to compress and accelerate deep neural networks in the classification task (e.g., ResNet-50 on ImageNet), but they cannot be straightforwardly applied to the semantic segmentation network that involves an implicit multi-task learning problem. To boost the segmentation performance, the backbone of semantic segmentation network is often pre-trained on a large scale classification dataset (e.g., ImageNet), and then optimized on the desired segmentation dataset. Hence to identify the redundancy in segmentation networks, we present a multi-task channel pruning approach. The importance of each convolution filter w.r.t the channel of an arbitrary layer will be simultaneously determined by the classification and segmentation tasks. In addition, we develop an alternative scheme for optimizing importance scores of filters in the entire network. Experimental results on several benchmarks illustrate the superiority of the proposed algorithm over the state-of-the-art pruning methods. Notably, we can obtain an about $2\times$ FLOPs reduction on DeepLabv3 with only an about $1\%$ mIoU drop on the PASCAL VOC 2012 dataset and an about $1.3\%$ mIoU drop on Cityscapes dataset, respectively.
Optical Flow Distillation: Towards Efficient and Stable Video Style Transfer
Jul 10, 2020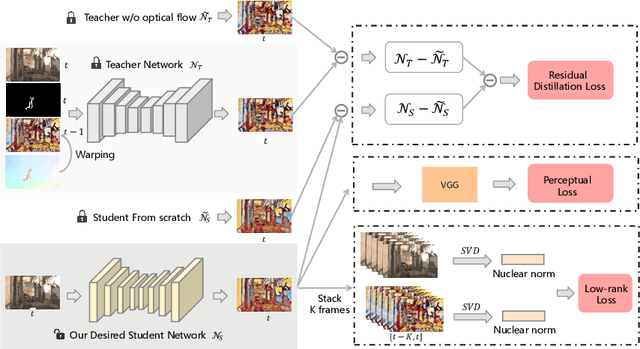
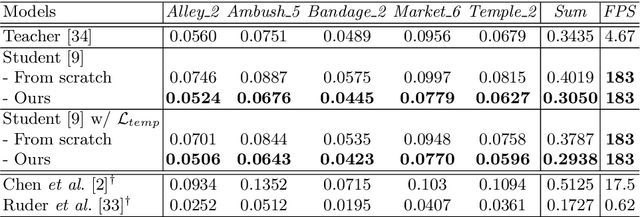
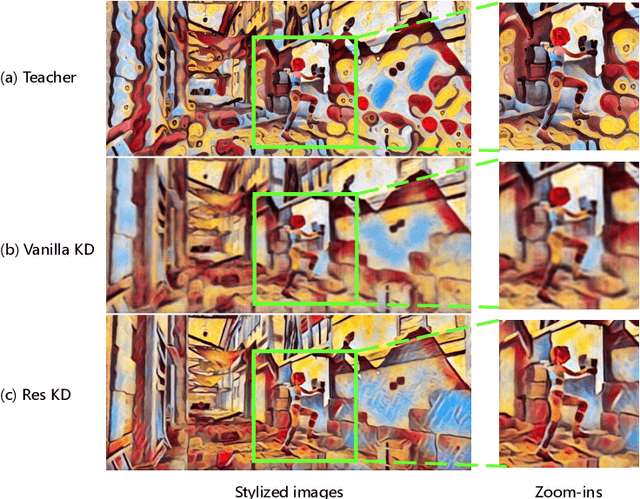
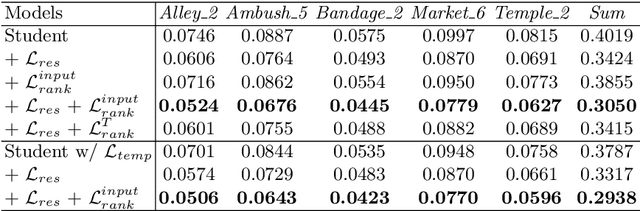
Video style transfer techniques inspire many exciting applications on mobile devices. However, their efficiency and stability are still far from satisfactory. To boost the transfer stability across frames, optical flow is widely adopted, despite its high computational complexity, e.g. occupying over 97% inference time. This paper proposes to learn a lightweight video style transfer network via knowledge distillation paradigm. We adopt two teacher networks, one of which takes optical flow during inference while the other does not. The output difference between these two teacher networks highlights the improvements made by optical flow, which is then adopted to distill the target student network. Furthermore, a low-rank distillation loss is employed to stabilize the output of student network by mimicking the rank of input videos. Extensive experiments demonstrate that our student network without an optical flow module is still able to generate stable video and runs much faster than the teacher network.